

Implementing database deployments in an organization can be a daunting task. In this post, I share some of my experiences from a previous role and some things to watch out for with database deployments.
Tightly coupled databases
It happens, and most of us have seen it, two different systems accessing each other’s database. They need information from each other, and the quickest and easiest way to get it is to reach in and take it. It may start with a single table or view, but as each system grows, the coupling gets tighter and tighter, which introduces a multitude of problems.
Database dependencies
I can recall an emergency meeting following the deployment of an application (let’s call it application A) which caused a different application (we’ll call this one application B) to start failing. Tempers were high, and fingers from both teams were firmly pointed at each other.
As the configuration manager, I was in charge of deployments, so I was facilitating the meeting. The latest deployment had introduced changes to the database schema of A, which cause B to fail. The most troubling part of the situation was that A had no idea that B was pulling data, so naturally, A didn’t understand why B was so worked up.
Circular dependencies
On another occasion, I was evaluating Microsoft SQL Server DACPAC as an automated database deployment method, and I ran into a circular dependency problem. The Microsoft SQL Server Database project that I created would not compile without a DACPAC reference to another database it was joining against. When I attempted to compile the project for the second database, it failed because the second project had a dependency on the first project and would not compile its DACPAC reference.
Redgate SQL Source Control and three-part naming convention
The organization where I worked settled on using Redgate SQL Source Control as the method for maintaining database schema. The standard at the time was to always write joins using a three-part naming convention, database.schema.object. For Redgate SQL Source Control, this caused an issue. When specifying the database in the object reference, it thought it was an external database call and didn’t take it into account when determining the build order of objects. This sometimes caused views to attempt to be built before the underlying table existed.
Constraints without names
Microsoft SQL Server can be fairly forgiving, sometimes to its detriment. One issue that we ran into was not giving a default constraint a name. The following is valid SQL syntax for creating a table with a default constraint:
CREATE TABLE Persons
(
P_Id int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255) DEFAULT 'Chicago'
)In this instance, Microsoft SQL Server will help you by giving the constraint a generated name:
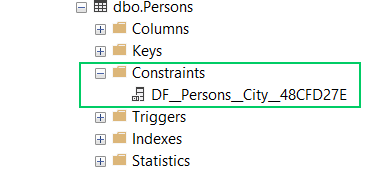
State-based (also known as model-based) deployments create a scratch database from the scripts folder. When the post-deployment check to ensure the target database is in the desired state executes, the deployment fails because the constraints don’t have the same name.
Mixing deployment technologies
We used Redgate SQL Source Control for schema changes and DbUp for data changes. Most, if not all, of the migrations-based deployment technologies (DBup, Flyway, and RoundhousE) create a table in the target database to keep track of which scripts have already been executed so that they’re not run again. State-based methods will delete any object not present in the state. We failed to take this into account, and Redgate SQL Source Control kept deleting the schemaversions table that DbUp created to keep track of previously run scripts. This caused scripts that were intended to be executed once to run with every deployment.
Bugs in the software
State-based deployment software is incredibly powerful and equally as complex. I’m impressed with how the technology can generate scripts in the correct order to transform the database to the desired state; however, just like any software, there are always edge cases that don’t quite work right.
One example of this involved changing a column so that it was not an identity column. This would usually be fine, but this same table was also configured for static data maintenance. Redgate SQL Source Control successfully generated the correct script to alter the table, but because of the static data maintenance, it included IDENTITY INSERT ON when populating the table. Since the identity column had been removed, the statement failed. It has since been fixed, but the bug caused some issues as we tried to get the release out.
Conclusion
Along with being daunting, database deployment issues can be quite troublesome to debug. It is my hope that these tips will save you hours if not days worth of investigation and troubleshooting.
Tags:





