

A broken build is annoying, sometimes frustrating and counterproductive, but rarely a crisis. Build servers rightly “fail fast” when things go wrong, and expect a completely new build to be performed, from scratch, when the problem is rectified.
In Octopus 1.0, we used this model too. Broken deployments are a bit different from broken builds, though: if a deployment breaks in production, then quite often there is an escalation and “all hands on deck” until the deployment is completed successfully. Broken deployments can cause downtime, and while in an ideal world redundancy and roll-back might save the day, often:
- Rollback processes, especially for databases, are hard to implement reliably
- Complex deployments can be time consuming to execute once the cause of a failure is rectified
- Failure of a single machine, say, one web server out of five, is better to ignore rather than halt the remaining deployment tasks
Sometimes the cause of a failure is as simple as a missing dependency, Windows feature or configuration setting on a machine, a locked file or read-only path. The fastest way to go from broken to deployed is to let a human get involved, and when it makes sense, either ignore or retry the failing activity.
So, in Octopus 2.0, while our default strategy will still be to “fail fast” like we did in the first version, we’re exploring the possibility of getting a human involved to sort things out when something goes wrong. We’re calling this feature Guided Failures.
To avoid unanticipated “races” between people addressing the issue, you’ll need to take charge of addressing a failure before actioning it.
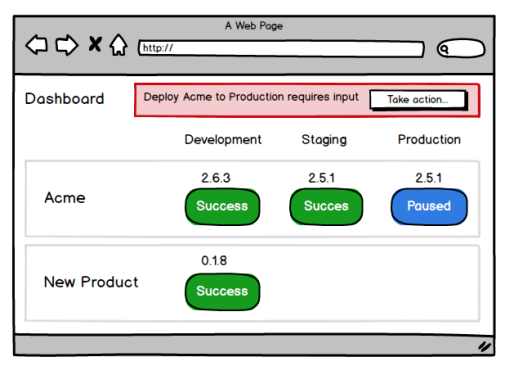
Once you’ve decided to take action on a failure, you can view full information about the error and the progress of the rest of the deployment.
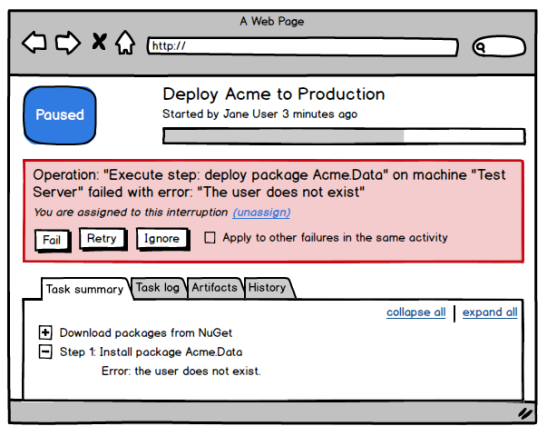
Choosing to Ignore the failure will cause deployment to continue despite the error, possibly resulting in more failures. _Retry_ing the failed action will cause Octopus to attempt it again, while choosing Fail will result in the deployment ending as it does today.
Many failures occur on multiple machines in large environments. To keep overhead to a minimum we’ll allow the Ignore and Retry actions to be applied once for all similar activities in a step.
Guided Failures will be enabled per-environment, so that it can be switched on in critical environments like production, while staying out of the way in continuously-deployed build and test scenarios. The behavior will also be able to be overridden on a per-deployment basis.
What do you think? Are Guided Failures something that will help in your deployments with Octopus? We’d love to have your feedback in the comments below.
Tags:

