

Hard disks are cheap, but running out of free space is a common problem when it comes to managing application servers, especially virtual servers. Octopus isn’t meant to replace Nagios or other health monitoring tools, but we do have a basic health check that we run every 30 minutes against your servers.
This is the health check summary in Octopus 2.0:
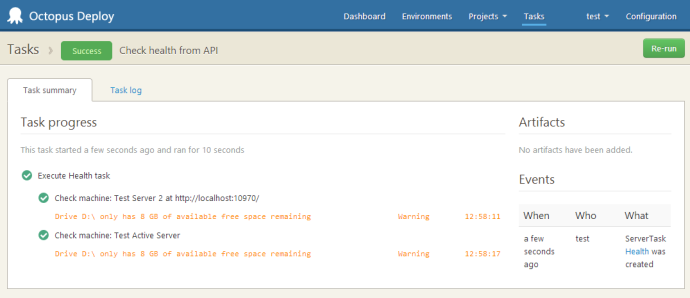
Clicking through, you can see the details for all the fixed disks:
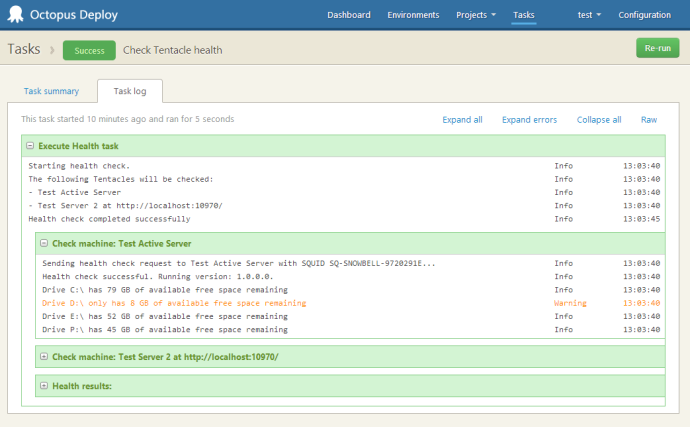
As I said, this feature isn’t meant to replace your existing server monitoring tools, but if you don’t already have something in place, hopefully it’s useful. Happy deployments!
Tags:

