

When configuring a WildFly domain in a cloud environment, it is often not possible to rely on fixed IP addresses or network broadcasts to discover resources. One solution offered to AWS users for discovering domain controllers is to use a S3 bucket as a central configuration point. In this blog post we’ll take a look at how to configure a simple WildFly domain in AWS using a S3 bucket for discovering domain controllers.
AWS IAM User
To start with we will need an IAM user with permissions to access the S3 bucket. The keys for this user will be used by WildFly to update the S3 bucket with the details of the domain controller.
In this example we will be using a bucket called wildfly-domain. To grant access to this bucket, the IAM user whose keys WildFly will be using has the following security policy.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Stmt1496702015000",
"Effect": "Allow",
"Action": [
"s3:*"
],
"Resource": [
"arn:aws:s3:::wildfly-domain",
"arn:aws:s3:::wildfly-domain/*"
]
}
]
}With this policy in place we need to create the access keys. Make a note of the Access key ID and Secret access key when they are generated, because AWS will not show you the secret access key again.
Create the Bucket
The S3 bucket itself is nothing special. It requires no special features to be enabled, so simply create a bucket with the name referenced in the security policy (wildfly-domain in our case).
Configuring the Domain Controller
There are a number of steps required to configure the domain controller to allow slave instances to discover it via the S3 bucket and connect.
Add a Slave User
The first thing we need to do is to create a user on the domain controller that slave instances will use to connect to it. This is done with the bin/add-user.sh script. The user:
- is a
Management User - doesn’t belong to any groups
- is going to be used for one AS process to connect to another AS process
The output of creating a user called slave is shown below.
[ec2-user@ip-172-30-0-89 bin]$ ./add-user.sh
What type of user do you wish to add?
a) Management User (mgmt-users.properties)
b) Application User (application-users.properties)
(a):
Enter the details of the new user to add.
Using realm 'ManagementRealm' as discovered from the existing property files.
Username : slave
Password recommendations are listed below. To modify these restrictions edit the add-user.properties configuration file.
- The password should be different from the username
- The password should not be one of the following restricted values {root, admin, administrator}
- The password should contain at least 8 characters, 1 alphabetic character(s), 1 digit(s), 1 non-alphanumeric symbol(s)
Password :
Re-enter Password :
What groups do you want this user to belong to? (Please enter a comma separated list, or leave blank for none)[ ]:
About to add user 'slave' for realm 'ManagementRealm'
Is this correct yes/no? yes
Added user 'slave' to file '/home/ec2-user/wildfly-11.0.0.Final/standalone/configuration/mgmt-users.properties'
Added user 'slave' to file '/home/ec2-user/wildfly-11.0.0.Final/domain/configuration/mgmt-users.properties'
Added user 'slave' with groups to file '/home/ec2-user/wildfly-11.0.0.Final/standalone/configuration/mgmt-groups.properties'
Added user 'slave' with groups to file '/home/ec2-user/wildfly-11.0.0.Final/domain/configuration/mgmt-groups.properties'
Is this new user going to be used for one AS process to connect to another AS process?
e.g. for a slave host controller connecting to the master or for a Remoting connection for server to server EJB calls.
yes/no? yes
To represent the user add the following to the server-identities definition <secret value="example-value=" />Take a note of the line
To represent the user add the following to the server-identities definition <secret value="example-value=" />We’ll need this to configure the slave instance later on.
Configure the S3 Bucket
In the domain/configuration/host-master.xml file, replace the default contents of the <domain-controller> element with the following code. This configuration instructs the domain controller to save its details in the wildfly-domain S3 bucket when it is started.
<domain-controller>
<local>
<discovery-options>
<discovery-option name="s3-discovery" code="org.jboss.as.host.controller.discovery.S3Discovery" module="org.jboss.as.host-controller">
<property name="access-key" value="ACCESS-KEY-VALUE"/>
<property name="secret-access-key" value="your-secret-key-goes-here"/>
<property name="location" value="wildfly-domain"/>
</discovery-option>
</discovery-options>
</local>
</domain-controller>Running the Domain Controller
By default the management interface is bound to localhost, and in this situation the domain controller will dutifully save configuration in the S3 bucket indicating that it can be reached on 127.0.0.1, which is obviously not useful information when the slave is running on another instance.
To fix this the domain controller must bind its management port to the external interface. Here we have started the domain controller with the -bmanagement=<ip> argument, which instructs WildFly to bind the management port to the IP address of the external NIC.
We have also supplied the name of the host configuration file via the --host-config parameter.
[ec2-user@ip-172-30-0-89 bin]$ ./domain.sh --host-config=host-master.xml -bmanagement=172.30.0.89Verifying the S3 Configuration
Once the domain controller has booted you will find new files created in the S3 bucket.
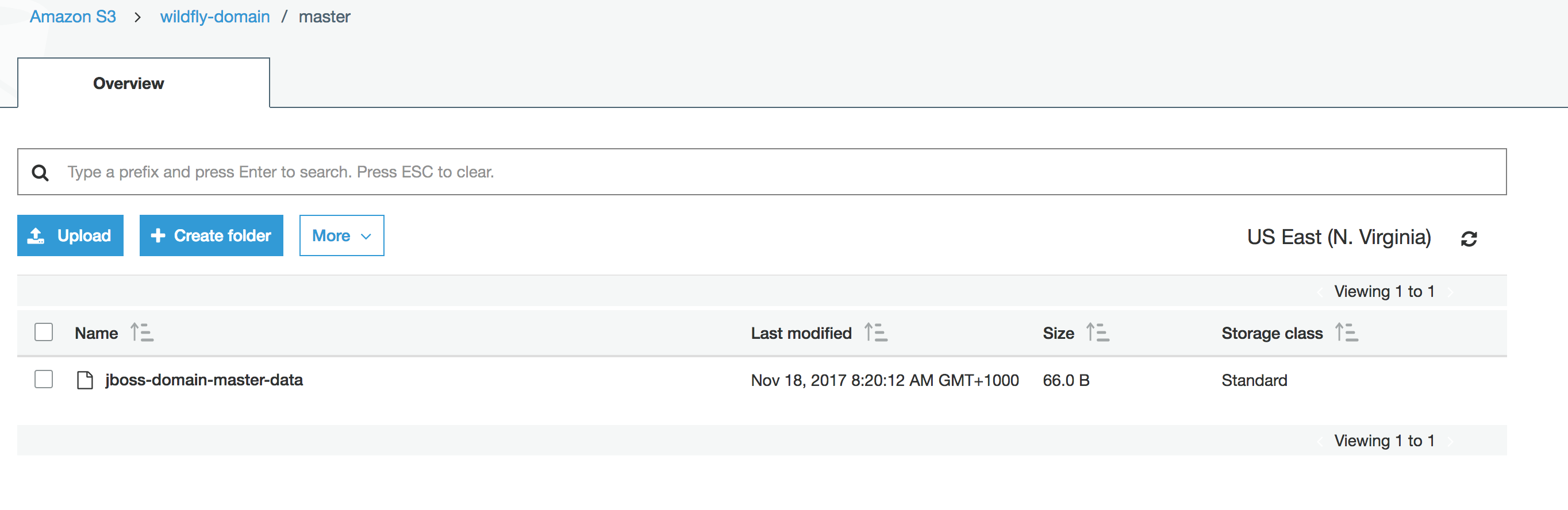
Configuring the Domain Slave
To configure the slave we need to edit the domain/configuration/host-slave.xml file.
Replace the contents of the <server-identities> element with the <secret> that was generated by the add-users.sh script when we created the slave user.
<server-identities>
<!-- Replace this with either a base64 password of your own, or use a vault with a vault expression -->
<secret value="example-value=" />
</server-identities>Then replace the contents of the <domain-controller> element with the following code.
<domain-controller>
<remote security-realm="ManagementRealm" username="slave">
<discovery-options>
<discovery-option name="s3-discovery" code="org.jboss.as.host.controller.discovery.S3Discovery" module="org.jboss.as.host-controller">
<property name="access-key" value="ACCESS-KEY-VALUE"/>
<property name="secret-access-key" value="your-secret-key-goes-here"/>
<property name="location" value="wildfly-domain"/>
</discovery-option>
</discovery-options>
</remote>
</domain-controller>The slave instance can then be started with the command
./domain.sh --host-config host-slave.xmlVerifying the Domain in the Management Console
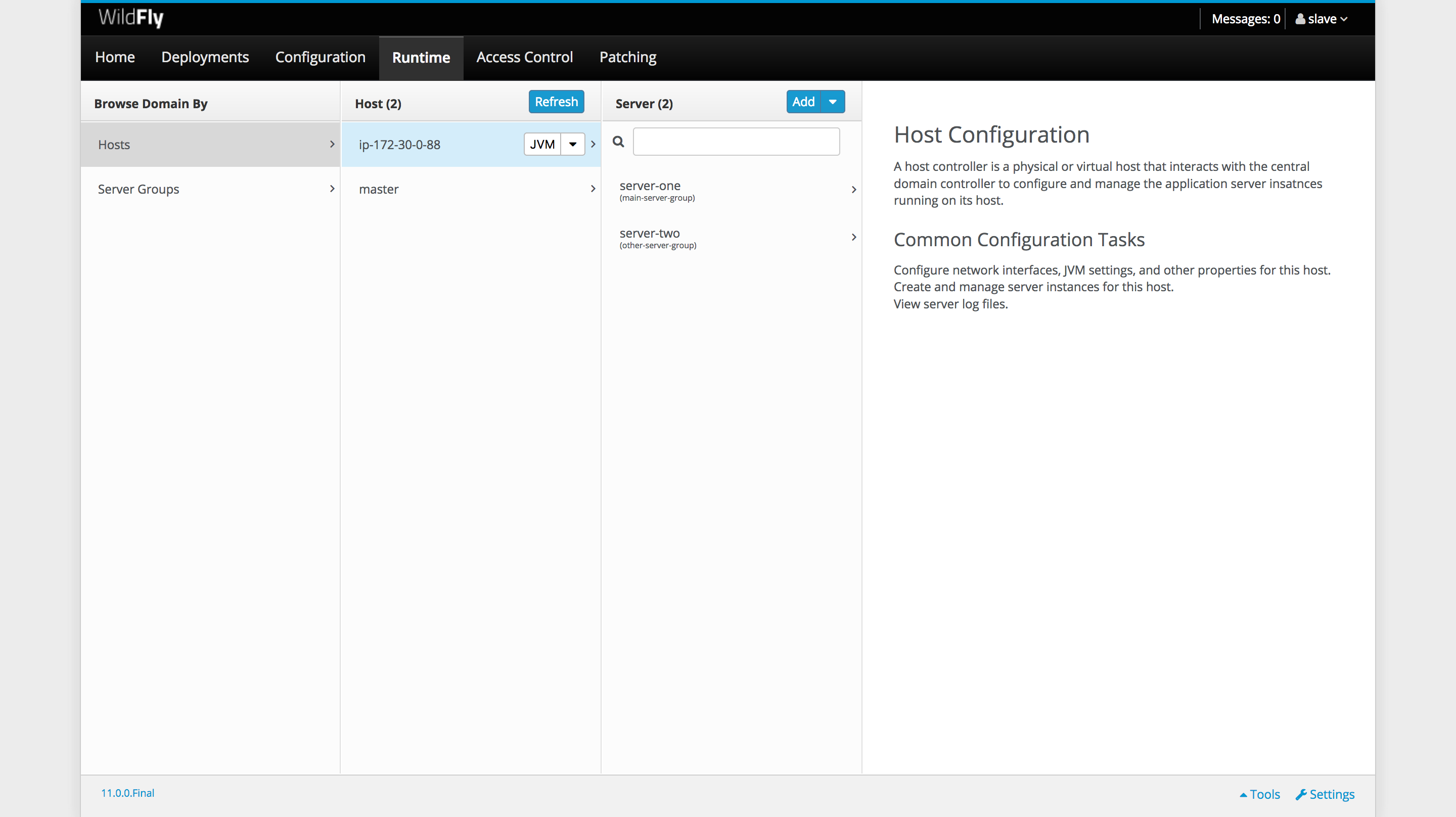
With the domain controller and slave both running, we can use the management console to view the details of the domain. Open up http://domaincontrollerip:9990. You will be prompted for credentials. Normally we would have a dedicated user created for the management console, but for convenience we can just use the slave user that we created earlier.
Under the Runtime tab we can see that the master and slave hosts are indeed connected as expected.
Conclusion
Using S3 buckets as a central point of configuration is an easy, convenient and reliable way to configure a WildFly domain in AWS. It removes the need to have fixed IP addresses, and works around the AWS limitation of preventing network broadcasts.
If you are interested in automating the deployment of your Java applications, download a trial copy of Octopus Deploy, and take a look at our documentation.
Tags:




