

In Octopus 1.0, we used WCF to communicate between Octopus servers and Tentacles. When the Octopus server needed to tell Tentacle to do something, such as run a PowerShell script, it looked something like this:
var client = clientBroker.Create<IJobService>("http://some-machine");
var ticket = client.RunScript("Write-Host 'Hello'; Start-Sleep -s 100; Write-Host 'Bye'");
do
{
var status = client.GetJobStatus(ticket);
log.Append(status.Log);
Thread.Sleep(4000);
if (IsCancelled())
{
client.Cancel(ticket);
}
} while (status.State == JobStatus.InProgress);
log.Append("Script run complete");This RPC style of programming worked well, but it had one limitation: it meant that the Tentacle always had to be the TCP listener, and the Octopus always had to be the TCP client.
When designing Octopus 2.0, the biggest feature request at the time was the ability to have polling Tentacles; effectively, reversing the TCP client/server relationship.
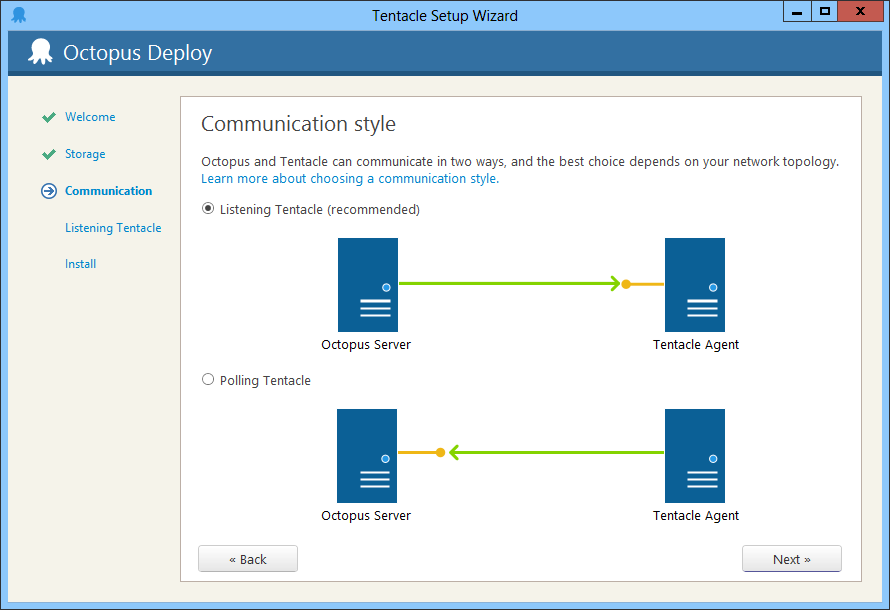
In the example above, this means that the Octopus server would need to somehow queue a command for Tentacle to run the script, and when Tentacle polls the Octopus for jobs to do, it would find this command and process it. Conceptually, it would mean something like this:
var runScriptCommand = new RunScriptCommand("Write-Host....");
messageQueue.For("MachineA").Enqueue(runScriptCommand);Using messages decoupled the TCP client/server relationship from the code - we’d be able to write code in Octopus to orchestrate Tentacles, without a whole lot of if/else conditions making it work differently depending whether the Tentacles were listening or polling. Since polling Tentacles required us to have some way of queuing messages to be picked up later, we may as well use them for listening Tentacles too.
There’s a big body of knowledge around building distributed systems based on messages and queues, so as soon as we decided that we’d needed queues of messages, those patterns and practices became central to our thinking. Most of our experience with messaging came from frameworks like NServiceBus and similar, which we’d put into practice many times.
Using messages as intended did make the orchestration code more complicated, and our orchestration code started to resemble NServiceBus sagas:
void Handle(BeginScriptRun message)
{
Send("MachineA", new RunScriptCommand("Write-Host ...."));
}
void Handle(JobStartedMessage message)
{
State.Ticket = message.Ticket;
}
void Handle(CancelMessage message)
{
Send("MachineA", new CancelCommand(State.Ticket));
}
void Handle(ScriptOutputLogged message)
{
log.Append(message.Log);
}
void Handle(ScriptCompletedMessage message)
{
log.Append("Script run complete");
Complete();
}Breaking away from the request/response RPC paradigm to messaging appeared to bring a number of benefits:
- It can better handle really long-running tasks, since you don’t have a thread blocked waiting for a response
- Server uptime is decoupled - if the Tentacle is offline initially, but eventually comes back online, the script run in this example can complete
- It allowed us to support both polling and listening Tentacles, since our application code could be written agnostic of the transport underneath
Over time, our NServiceBus saga-like classes evolved into an Actor framework, similar to Akka (though this was about six months before Akka.NET began). We borrowed a number of concepts from Akka, like supervision trees, which made error handling a little more bearable.
This has been in production now for the last 12 months. And while it mostly works well, I’ve started to notice many downsides to this actor/message-oriented approach:
- The single-threaded nature of actors is great and makes concurrency easy. However, there are times where you do want some kind of mutual exclusion, and you end up having to implement it using some ugly messaging approaches anyway.
- It’s much harder to follow the code and reason about it. Finding which actor handles which message is always a two-step navigation process in Visual Studio.
- Crash dumps and stack traces become almost useless.
- Managing actor lifetimes is really hard. That
Complete()call at the end of the example above is important because it tells us when this actor can be cleaned up. It’s so easy to forget to call these (should I have called it in the cancel message handler too?) - Error handling is equally nasty. E.g., in the first code example, if the remote machine failed, the exception would bubble up, or be handled with a
try/catch. In the second example, catching and handling these errors is an explicit step. - It’s much harder to teach this style of programming to a new developer
When I look at the orchestration code in Octopus 1.6, it’s really easy to reason about and follow. Perhaps it doesn’t scale as nicely, and perhaps there are a few too many places where we explicitly deal with threading or locking. But the stack traces are readable, and I can navigate it easily. When reading the deployment orchestration code in 2.0, I have to really concentrate.
It also turns out that the “server uptime is decoupled” benefit that I mentioned wasn’t terribly useful for us either. If a Tentacle is offline, we might want some automatic retries for, say, 30 seconds or a few minutes. Beyond that, we really don’t need messages to queue up. If we’re in the middle of a deployment, and a machine is offline, we need to make a decision: either skip it or fail the deployment. We’re not going to wait 6 hours. That’s usually handled in messaging frameworks by giving messages a very short time-to-live, but it still complicates the exception handling process.
The key benefit of actors is that you gain great concurrency with much simpler code than using the threading/locking primitives directly. And yet when I look at the Octopus 1.0 orchestration code, we use so few of those primitives that the actor approach turns out to be less clean. This suggests that our problem domain isn’t really suited for actors. And while we might not be able to escape having messages at some level to handle the polling/listening configuration, request/response semantics would seem to be more suitable.
So, what are we doing for Octopus 3.0? We’ll be reverting to something very similar to the Octopus 1.0 style. The difference is that, while from a coding point of view we’ll use request/response, underneath those proxies we’ll still allow for polling or listening Tentacles:
- If the Tentacle is listening, we’ll open a
TcpClientand connect. - If the Tentacle is polling, we’ll put the response in a queue, and wait on a wait handle. When the request is picked up and a response is available, the wait handle will complete.
You can think of this as being two layers: a transport layer in which either party can be the TcpClient/TcpListener, and a logical request/response layer that sits on top.
Our new communication stack will be open source (and will build upon the Halibut work I wrote about some time ago), and I’ll post more details as it evolves.
Tags:


