

18 months ago I blogged about how we decided to switch from RavenDB to SQL Server in Octopus 3.0. That post explained the problems we had and the reasons we decided to switch. We followed it with a post on how we planned to use SQL Server. Octopus 3.x has been in production for a while now, so in this post, I want to provide an update, and go into some detail about how we use SQL Server as a document store.
Goals
When using Raven, we had found that the document database model made it so much easier to work with our data than we ever could have with a relational model. Even though we decided to switch to SQL Server, we wanted to keep many of the aspects that we had grown used to when using a document store.
We had a few goals in mind:
- Load/save entire aggregate roots into a single table
- Fast queries
- Plain old ACID, no eventual consistency to worry about
- Avoid the need for joins as much as possible
Typical table structure
Each type of entity/aggregate root that we deal with (Machines, Environments, Releases, Tasks) gets its own table, which follow a similar pattern:
- An ID (details below)
- Any other fields that we query against
- A JSON
nvarchar(max)column
For example, here’s the Deployment table. We often need to perform queries like, “what deployments belong to this release”, or “what is the most recent deployment for this project/environment”, so these are fields on the table:
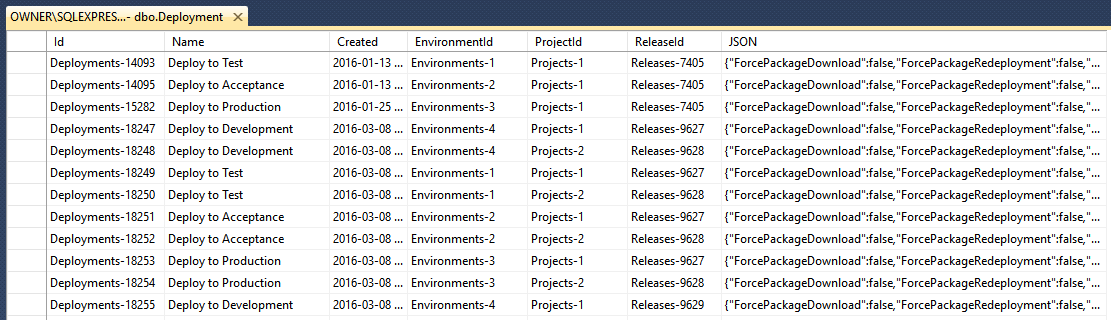
The JSON column contains all of the other properties of the document, including any nested objects. We use a custom JSON.NET Contract Resolver to ensure that properties that are already saved in other columns of the table aren’t duplicated in the JSON.
Relations
We model relationships in different ways. For relationships that we don’t query against, the property or array is simply serialized in JSON.
When we do need to query against a relationship, for one-to-many relationship, the property is stored in a single column as you’d expect:
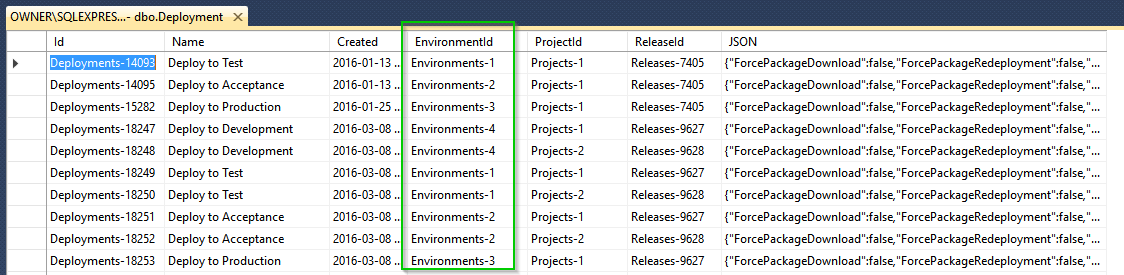
For a many-to-many, we do something a bit naughty: we store the values with | characters between each value:

This gives us two options for querying. For tables that we’d expect to only get a few dozen, no more than a thousand results, we can simply query them using LIKE '%|' + @value + '|%'. We know it results in a full table scan, but these queries are rare, the tables are small, and it’s fast enough for us.
For tables that grow into the millions of records (audit events, where each event references many related documents), we use a trigger. Each time the row is written, we split the values, and use the MERGE statement to keep a join table up to date:
ALTER TRIGGER [dbo].[EventInsertUpdateTrigger] ON [dbo].[Event] AFTER INSERT, UPDATE
AS
BEGIN
DELETE FROM [dbo].EventRelatedDocument where EventId in (SELECT Id from INSERTED);
INSERT INTO [dbo].EventRelatedDocument (RelatedDocumentId, EventId)
select Value, Id from INSERTED
cross apply [fnSplitReferenceCollectionAsTable](RelatedDocumentIds)
END
We can then perform queries that join against this table, but application code can still load/save objects as a single JSON document.
ID generation
Instead of using integer/identity fields or GUIDs for ID’s, we use strings, and something similar to the Hi-Lo algorithm. The format is always <PluralTableName>-<Number>.
This is an idea borrowed from RavenDB, and it means that if we have a document like an audit event, which relates to many other documents, we can do something like:
{
"Id": "Events-245",
"RelatedDocumentIds": [ "Project-17", "Environments-32", "Releases-741" ]
...
}
If we had just used numbers or GUIDs, it would be difficult to ever work out whether 17 is the ID of a project, or an environment. Making the document name a prefix in the ID gives a lot of advantages.
To generate these IDs, we use a table, called KeyAllocation. Each Octopus Server uses a serializable transaction to ask for a chunk of ID’s (usually 20 or so) by increasing the allocated range in this table:
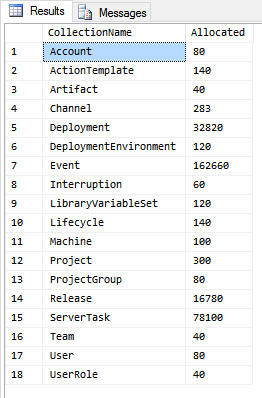
As time goes by, the server can then issue these ID’s out of the batch, without going to the database each time.
Usage from .NET
When working with the database from .NET code, we wanted to be very deliberate about database operations. Most ORM’s provide a unit of work (NHibernate’s ISession, Entity Framework’s DbContext), which track changes made to objects and automatically update records that have changed.
Since unintended consequences of the unit of work had been a performance issue for us in the past, we decided to be very deliberate about:
- Transaction boundaries
- Inserting/updating/deleting documents
Instead of a unit of work, we simply abstract a SQL transaction/connection. Typical code for loading, editing and saving an document looks like this:
using (var transaction = store.BeginTransaction())
{
var release = transaction.Load<Release>("Releases-1");
release.ReleaseNotes = "Hello, world";
transaction.Update(release);
transaction.Commit();
}
When querying, we don’t use LINQ or any fancy criteria/specification builders, we just have a very simple query helper which just helps to structure a SQL query. Anything you can do in SQL can be put here:
var project = transaction.Query<Project>()
.Where("Name = @name and IsDisabled = 0")
.Parameter("name", "My Project");
.First();
var releases = transaction.Query<Release>()
.Where("ProjectId = @proj")
.Parameter("proj", project.Id)
.ToList();
Since our tables store entire documents, object/relational mapping is easy - we just need to specify the table that a given document maps to, and which fields should be stored as columns vs. in the JSON field. Here’s an example mapping:
public class MachineMap : DocumentMap<Machine>
{
public MachineMap()
{
Column(m => m.Name);
Column(m => m.IsDisabled);
Column(m => m.Roles);
Column(m => m.EnvironmentIds);
Unique("MachineNameUnique", "Name", "A machine with this name already exists. Please choose a different name. To add the same machine to multiple environments, edit the machine details and select additional environments.");
}
}
(While we don’t use a lot of foreign keys, we do rely on some constraints, like unique constraints as shown above)
Migrations
Any database, even a document database, has to deal with schema migrations at some point.
For some changes, like introducing a new property that we don’t plan to query against, there’s nothing to do: the JSON serializer will automatically start writing the new property, and will handle the property being missing in older documents. Class constructors can set reasonable default values.
Other changes require a migration script. For these, we use DbUp. This will either be a SQL script, or C# code (DbUp can let you execute arbitrary .NET code during migrations) for more advanced migrations. We’ll soon have done four major releases and dozens of minor releases on top of this database, and so far haven’t found a case where we haven’t been able to deal with migrations easily.
Stats
Using SQL Server as a document store works for us, but I’m sure it’s not for everyone. Some rough statistics might help to put it into perspective:
- Since 3.x was released, there have been about 15,000 successful Octopus installs - that’s about 68% of all installs
- Some of these installs are very big: deploying 300+ projects to 3,500+ machines
- Some have hundreds of thousands of deployments in the database
- The largest tables are the tables for audit events, which are routinely in the millions of records
- We’ve had very few complaints about performance since 3.x was released, and performance issues have been fixed easily
We don’t just use this approach in Octopus either - we also use it for our website and order processing system.
SQL Server 2016 JSON support
The approach that we are following is going to become much more common. SQL Server 2016 is introducing support for JSON, not by adding a new type (the way XML was supported), but by adding functions to deal with JSON that is stored in nvarchar columns. Our current schema is perfectly positioned to take advantage of this.
Unfortunately, we’ll need to support versions of SQL Server older than 2016, so it’ll take a while before we can rely on these features. But we might be able to use it to optimize certain cases - if JSON functions are available in your version of SQL Server, we might be able to do less processing in the server for example.
Why not just use Entity Framework?
Here are some advantages we get to using SQL as a document store, instead of Entity Framework and a relational store:
- No SELECT N+1 problems; since we get entire object trees from a single table, we don’t need to perform selects or do joins to get child records
- No joins. There is a single code path in Octopus where we join against two tables; in all other operations, we’ve avoided joins completely.
- Easy mapping
- The query you write is the query you get. It’s very easy to reason about the SQL that is going to be executed; we aren’t relying on a LINQ translator
- Many to many relationships are much easier to deal with
Summary
Changing storage technologies and rewriting much of the application to do it was a big bet that we made a few years ago, and I’m very happy with the result. Performance is much better, very few support issues (unlike the previous architecture), and it’s a technology our customers are much more comfortable with.
While many applications use an occasional JSON column for some data, when we started this, I hadn’t seen many that went this far to pretend that SQL Server is a document store, throwing out most of the relational aspects. I do think it’s going to become more common though. Recently on .NET Rocks!, Jeremy Miller spoke about Marten, which sounds exactly like what we’ve done except on top of PostgreSQL. With SQL 2016 getting its own JSON functions, I expect it’s going to become even more popular.
I’m sure this approach isn’t for everyone. Applications that write a lot of data and query less can probably benefit more from the relational model. Applications that need to scale the database horizontally should stick to document databases that are built for the job. But if you’re in an environment where SQL Server is already there, and where the performance requirements aren’t insane, then SQL as a document store might just work for you.
Tags:

