
My previous blog posts discussed why you should consider automated database deployments and tips for getting started.
This article walks through setting up a database deployment automation pipeline using the state-based approach for Redgate’s SQL Change Automation. I picked this tool because it is easy to set up, integrates with SSMS, and I already had a demo setup. I’m also biased towards Redgate’s tooling.
By the end of this article, you will have a working proof of concept you can demo.
Prep work
For this demo, you need a running SQL Server instance, an Octopus Deploy instance, and a CI server. I recommend using a dev environment or your local machine for this proof of concept.
Required tools
You will need the following tools. The examples given use TeamCity and VSTS/TFS, but even if you’re using a different tool, the core concepts and UI for all the CI tools are very similar.
- Octopus Deploy:
- Redgate SQL Tool-belt
- Build Server/Continuous Integration (CI) tool (pick one):
- SQL Server Management Studio (SSMS):
- SQL Server:
Installing the software
If you run into issues installing any of these tools, please go to the vendor’s website for help. If you need any help installing Octopus Deploy, please start with our docs or contact support.
Developer workstation
This is the machine you will use to make the schema changes and check them into source control. When you install Redgate’s SQL Tool-belt, you will be prompt to install quite a bit of software. You only need to install the following:
- SQL Source Control.
- SQL Prompt (it isn’t required, but it makes things much easier).
- SSMS Integration Pack.
Build server/Continuous Integration tool
Both Octopus Deploy and Redgate have plug-ins for the major build servers/continuous integration tools:
- Jenkins:
- TeamCity:
- VSTS/TFS:
- Bamboo:
Deployment target or database worker
Installing an Octopus Tentacle on SQL Server is a big no-no. Our documentation goes into further details why.
The preferred solution is to configure a jump box that sits between Octopus Deploy and SQL Server. Octopus supports two options for this:
- Deployment target
- Database worker
In this post, I’ll add a deployment target but I wanted to mention workers as another good option. They’re particularly useful for teams doing a lot of database deployments.
Workers enable you to move deployment work onto other machines running in pools and database deployments are a common use case for this. You can create a pool of dedicated workers that can be used for database deployments by multiple projects and teams.
See our documentation for more information.
For security purposes, I recommend running the Tentacle/Worker as a specific user account. This way you can make use of integrated security. You can configure Active Directory or use SQL Users instead.
For the jump box, you need to install the following items:
- SQL Change Automation PowerShell 3.0.
- SQL Change Automation.
Sample project
For this walk-through, I modified the RandomQuotes project. The source code for this sample can be found in this GitHub repo. Fork the repository so you can make modifications as you follow this article.
Configuring the CI/CD pipeline
Everything you need is already checked into source control. All we need to do is build it and push it to the SQL Server.
Octopus Deploy configuration
You need the step templates from Redgate to create a database release and deploy a database release. When you browse the step template you might notice the step template to deploy directly from a package. The state-based functionality for SQL Change Automation works by comparing the state of the database stored in the NuGet package with the destination database. Each time it runs, it creates a new set of delta scripts to apply. The recommended process is:
- Download the database package to the jump box.
- Create the delta script by comparing the package on the jump box with the database on the SQL Server.
- Review the delta script (this can be skipped in dev).
- Run the script on SQL Server using the Tentacle on the jump box.
Using the step template to deploy from the package prevents the ability to review the scripts.
This is the process I have put together for deploying databases.
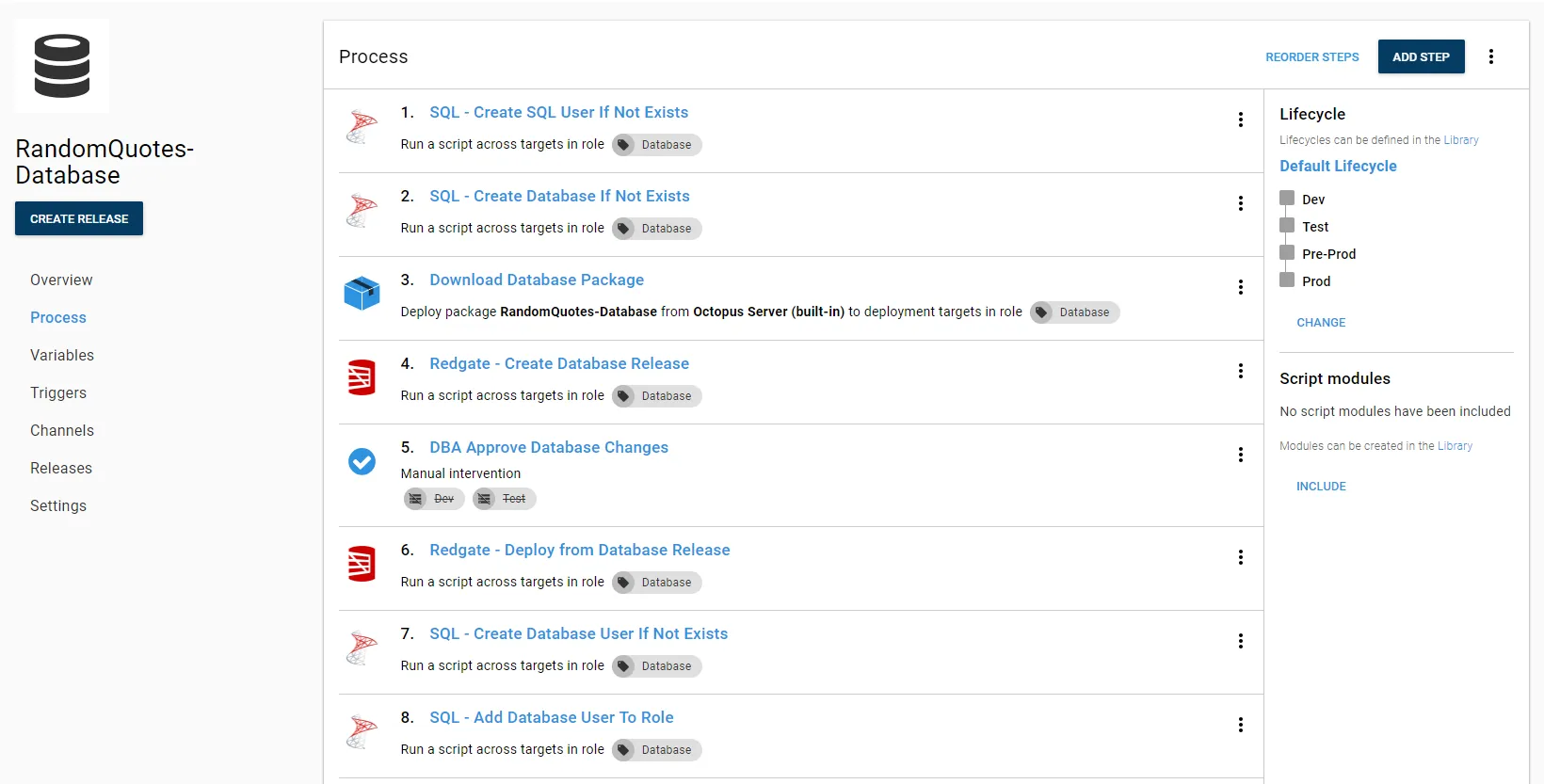
This process does the following:
- The main SQL user for the database.
- The database.
- Adds the SQL user to the database.
- Adds the user to the role.
If you want your process to do that, you can download those step templates from the Octopus Community Step Template Library.
If this is the beginning of your automated database deployment journey, you don’t have to add all that functionality. The main steps you need from the above screenshot are:
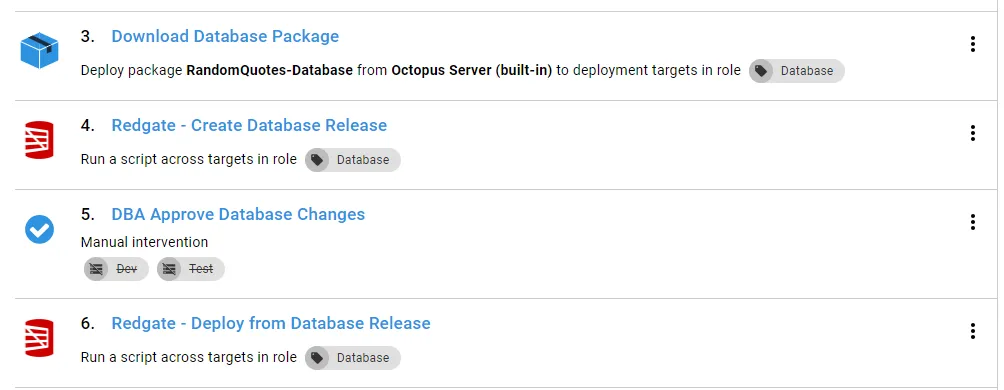
Let’s walk through each one. The download a package step is very straightforward, no custom settings aside from picking the package name:
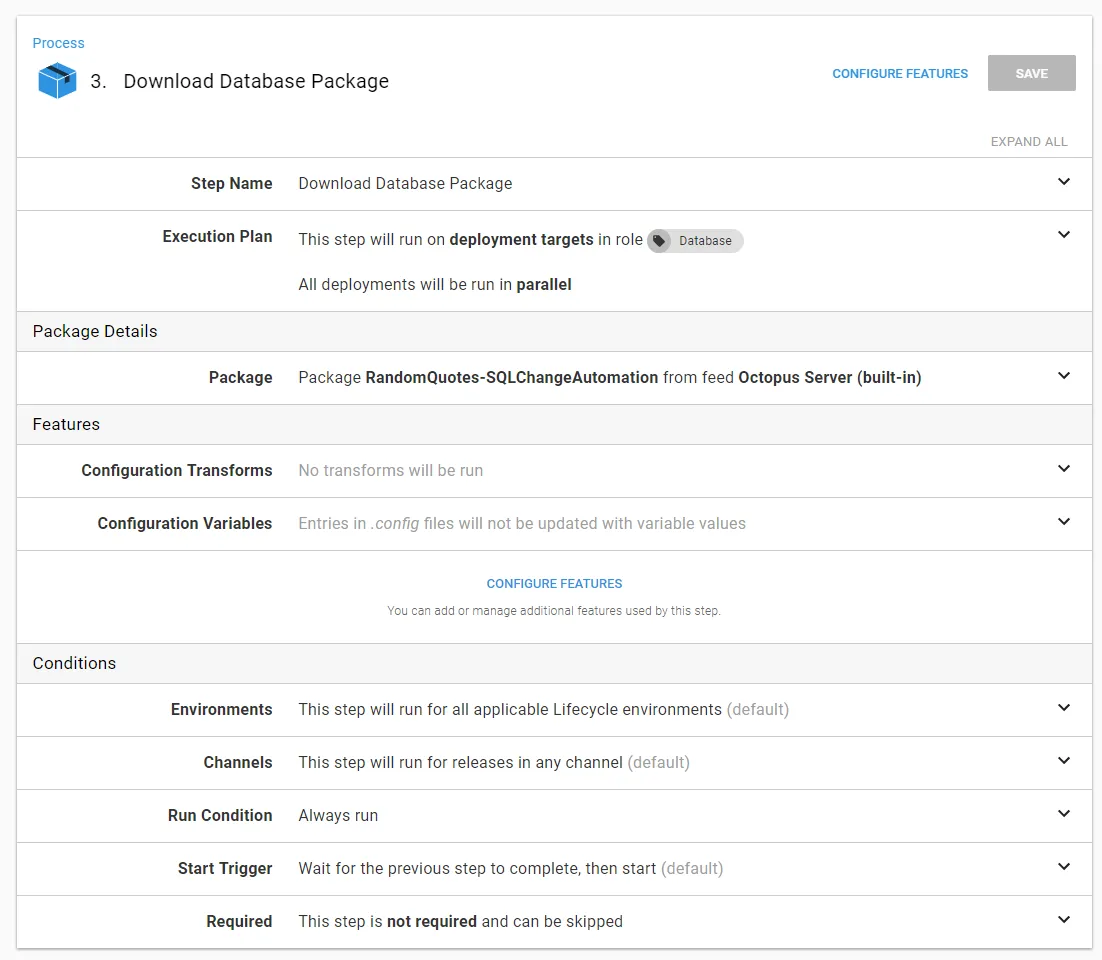
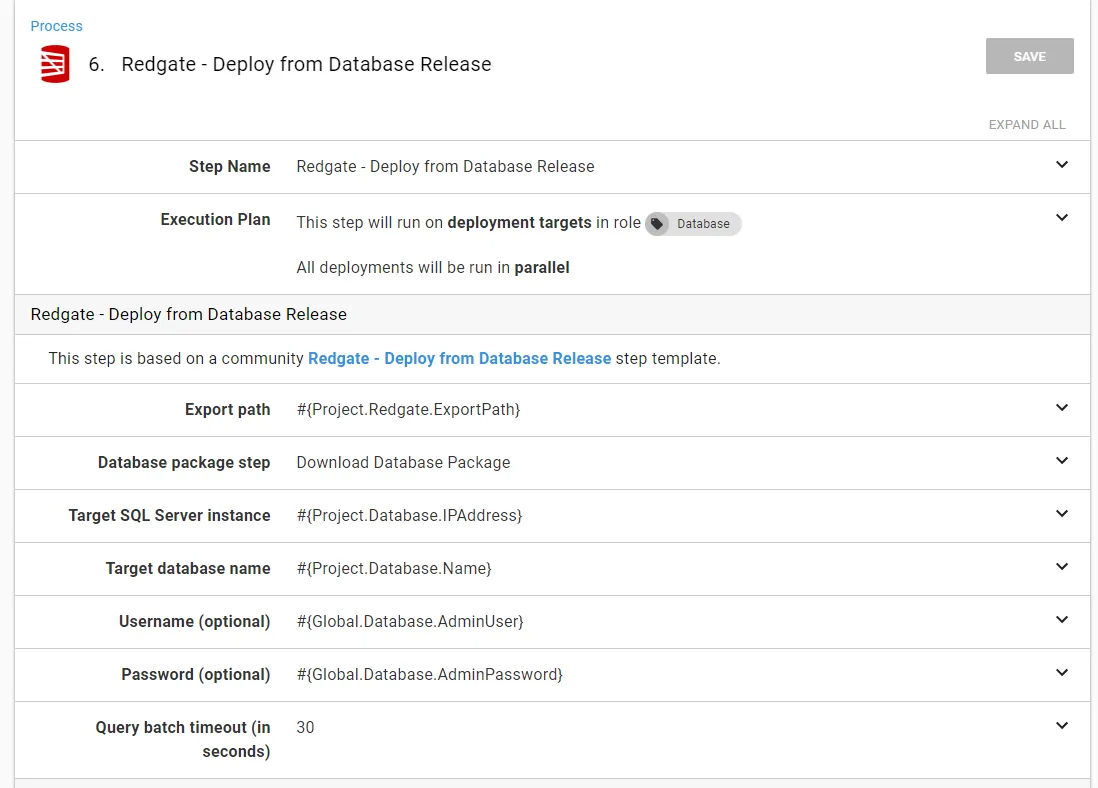
The Redgate - Create Database Release step is a little more interesting. The Export Path is the location the delta script will be exported to. This must be a directory outside of the Octopus Deploy Tentacle folder because the Redgate - Deploy from Database Release step needs access to that path, and the Tentacle folder will be different for each step:
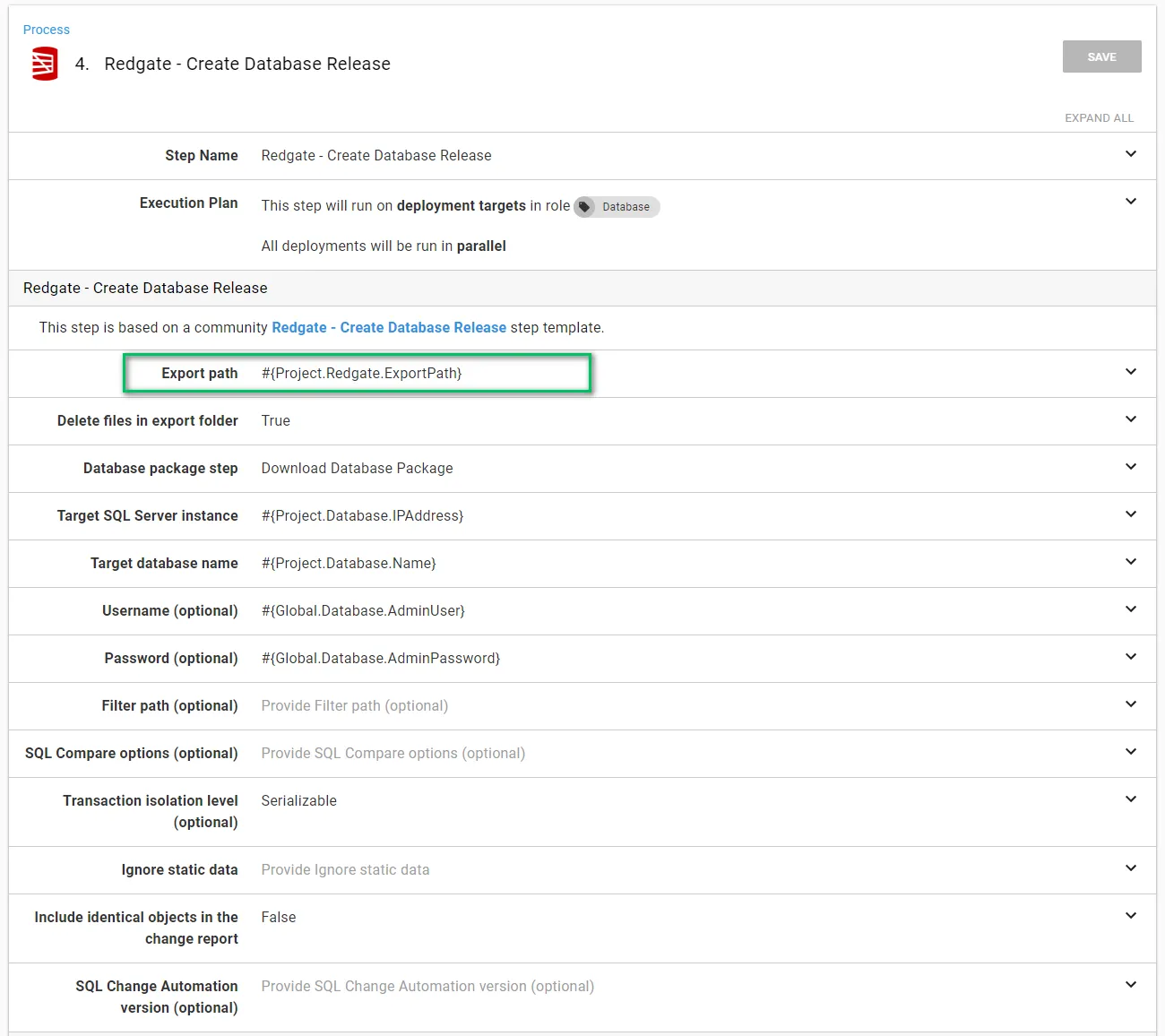
I like to use a project variable:
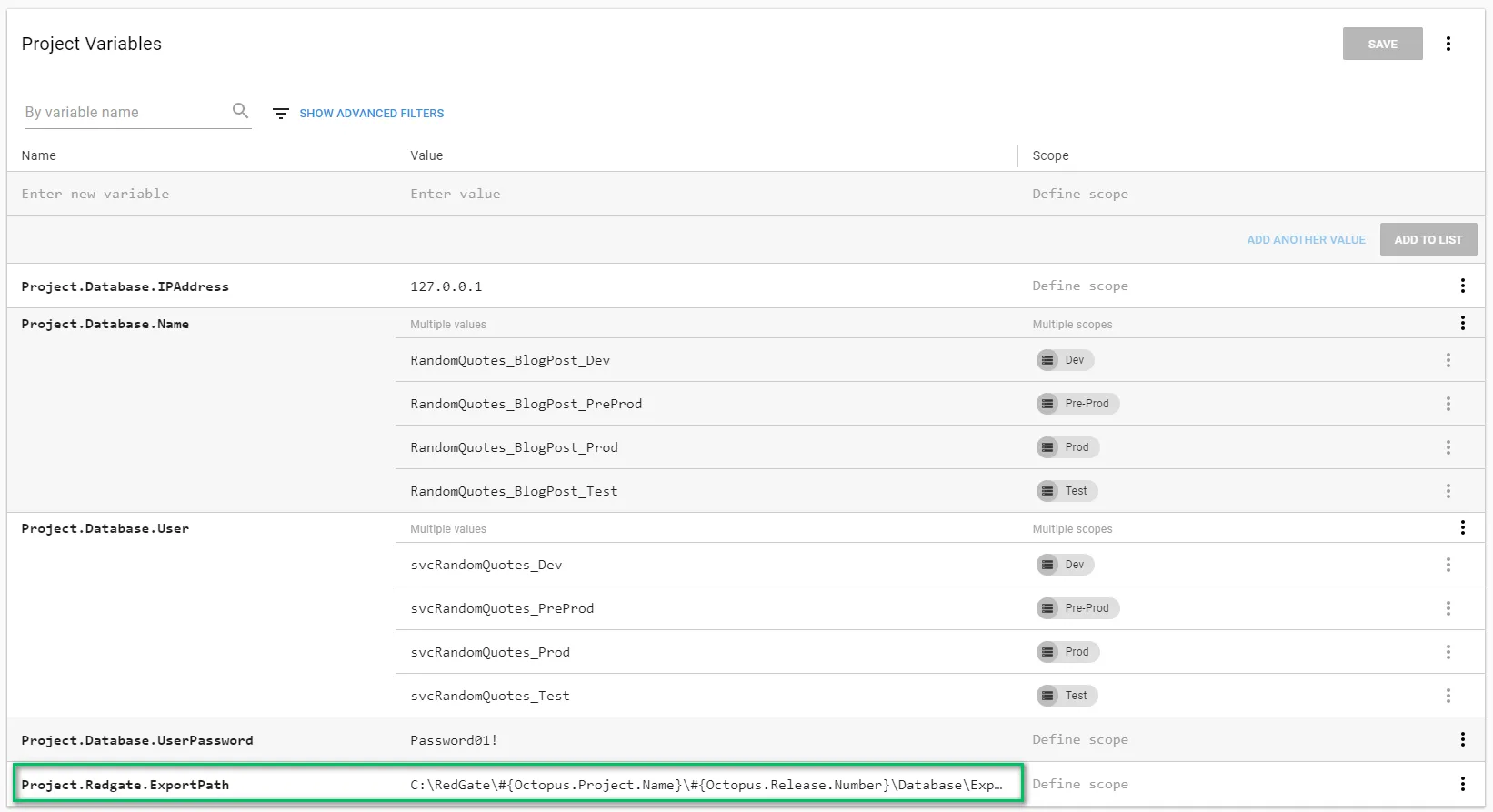
The full value of the variable is:
C:\RedGate\#{Octopus.Project.Name}\#{Octopus.Release.Number}\Database\ExportOther recommendations on this screen:
- I have supplied the username and password. I recommend using integrated security and having the Tentacle running as a specific service account. I don’t have Active Directory configured on my test machine, so I used SQL Users for this demo.
- Take a look at the default SQL Compare Options and make sure they match what you need. If they don’t, you need to supply the ones you want in the
SQL Compare Options (optional)variable. You can view the documentation here. If you do decide to use custom options, I recommend creating a variable in a library variable set, so those options can be shared across many projects. - Use a custom filter in the event you want to limit what the deployment process can change. I wrote a lengthy blog post about how to do that here. My personal preference is to filter out all users and let the DBAs manage them. Even better, let Octopus manage them since it can handle environmental differences.
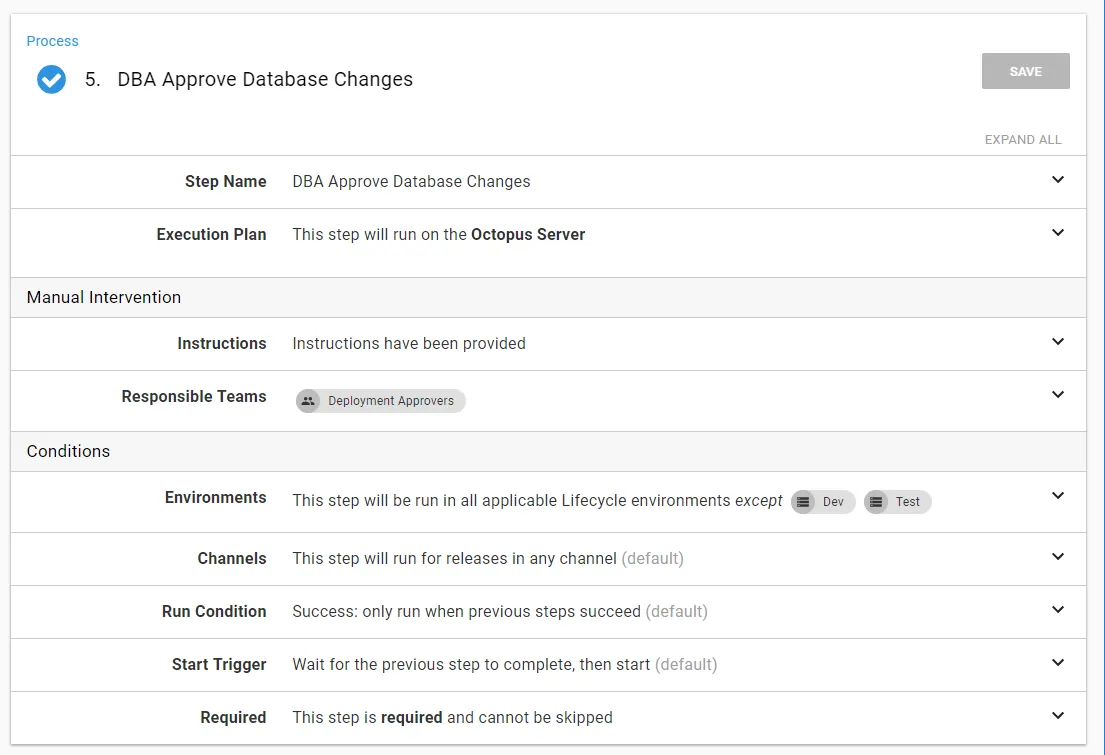
The next step is approving the database release. I recommend creating a custom team to be responsible for this, but I prefer to skip this step in dev and QA:
The create database release step makes use of the artifact functionality built into Octopus Deploy. This allows the approver to download the files and review them:
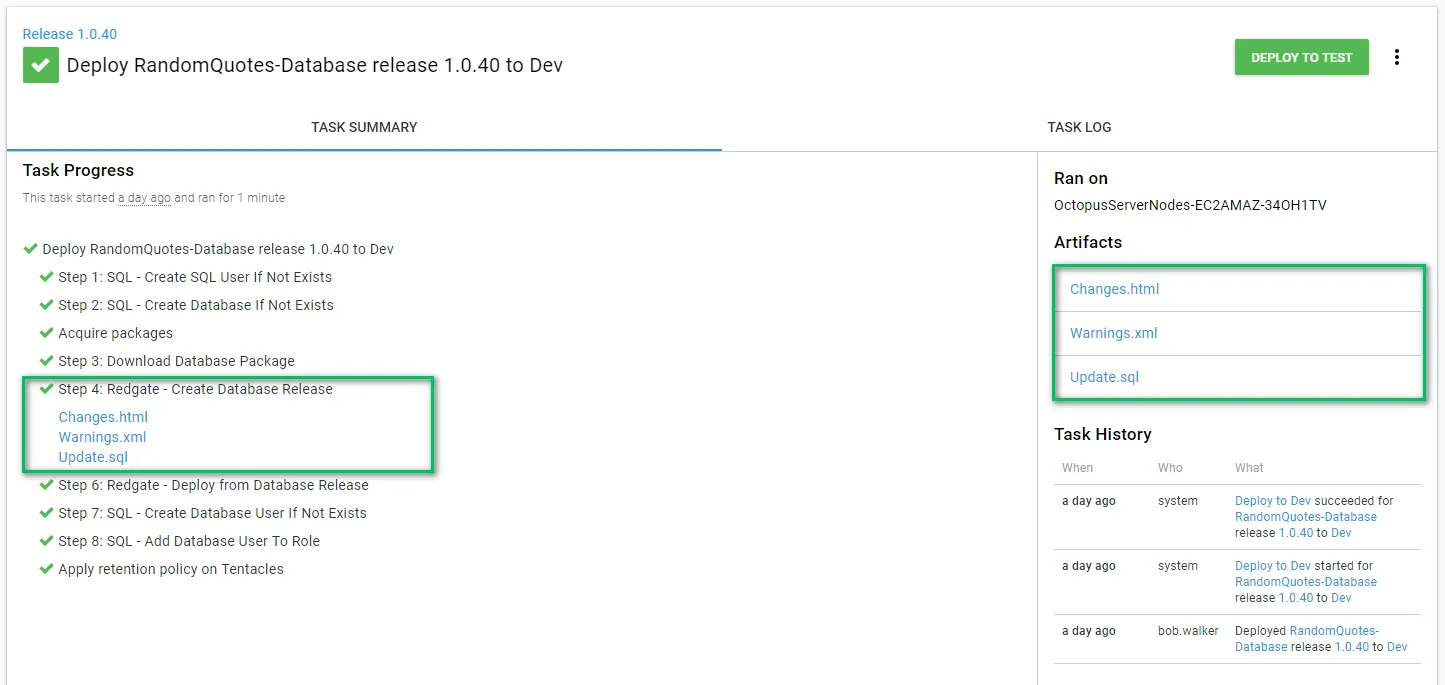
The final step is deploying the database release. This step takes the delta script in the export data path and runs it on the target server, which is why I recommend putting the export path in a variable:
That’s it for the Octopus Deploy configuration. Now it’s time to move on to the build server.
Build server configuration
For this blog post, I use VSTS/TFS and TeamCity. At a minimum, the build should do the following:
- Build a NuGet package containing the database state using the Redgate plug-in.
- Push that package to Octopus Deploy using the Octopus Deploy plug-in.
- Create a release for the package, which was just pushed using the Octopus Deploy plug-in.
- Deploy that release using the Octopus Deploy plug-in.
VSTS / TFS build
There are only three steps in VSTS/TFS to build and deploy a database:
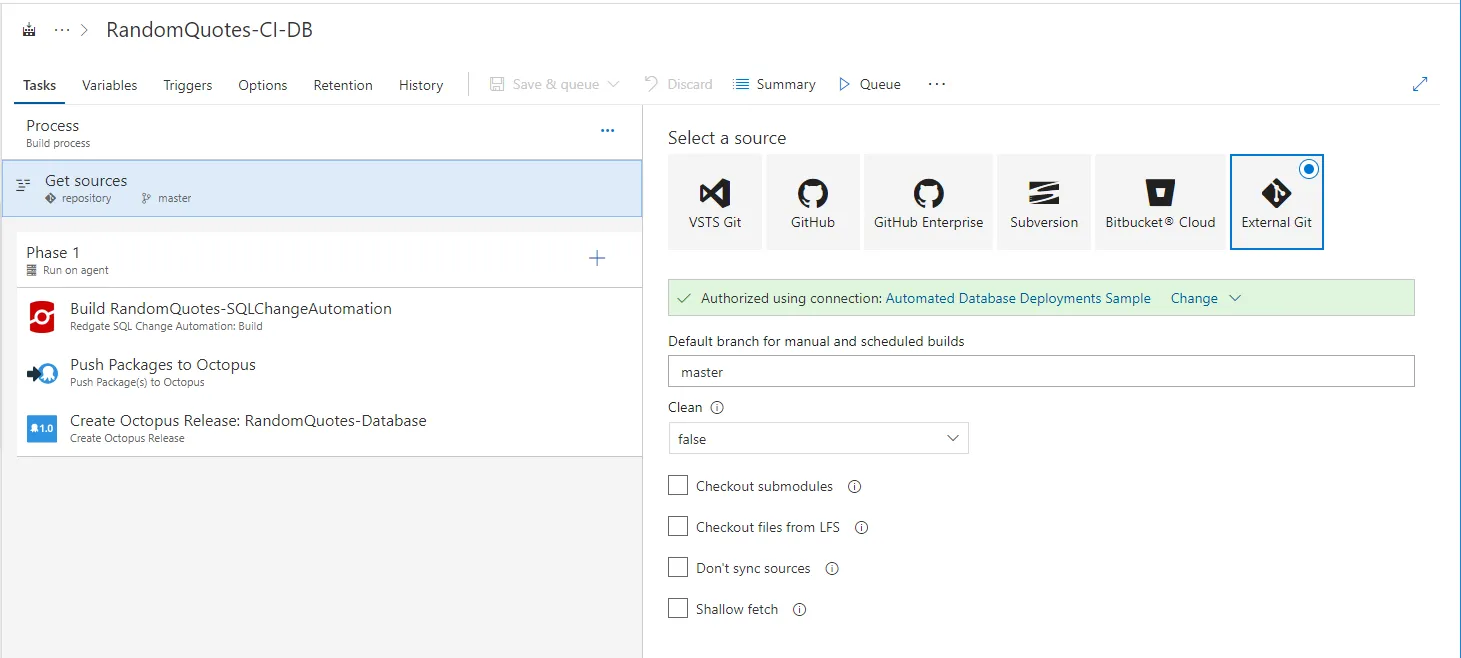
The first step will build the database package from source control. The highlighted items are the ones you need to change. The subfolder path variable is relative. I am using a sample Git repo which is why the RedgateSqlChangeAutomationStateBased folder is in the path:
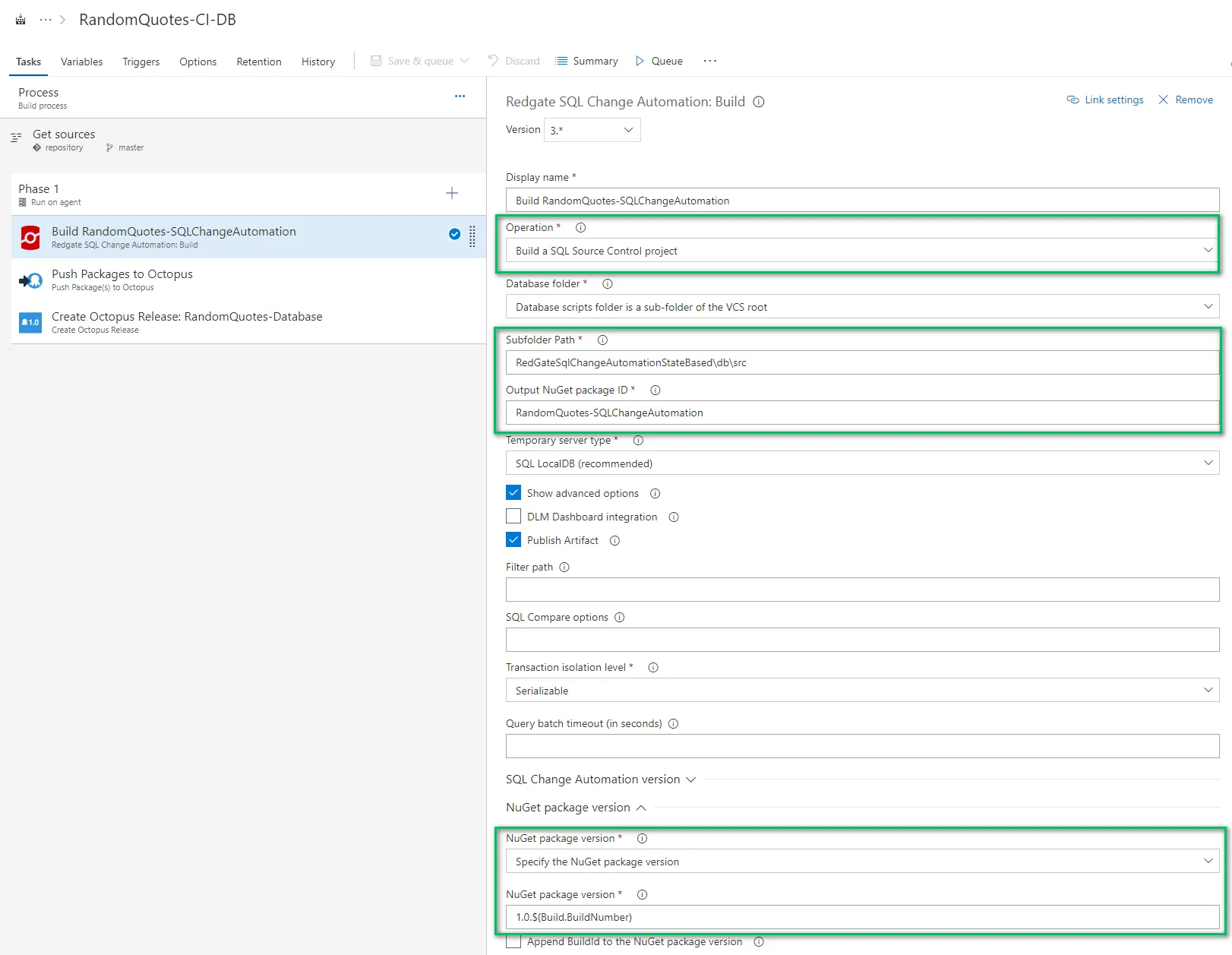
The push package to Octopus step requires you to know the full path to the artifact generated by the previous step. I’m not 100% sure how you would know without trial and error:
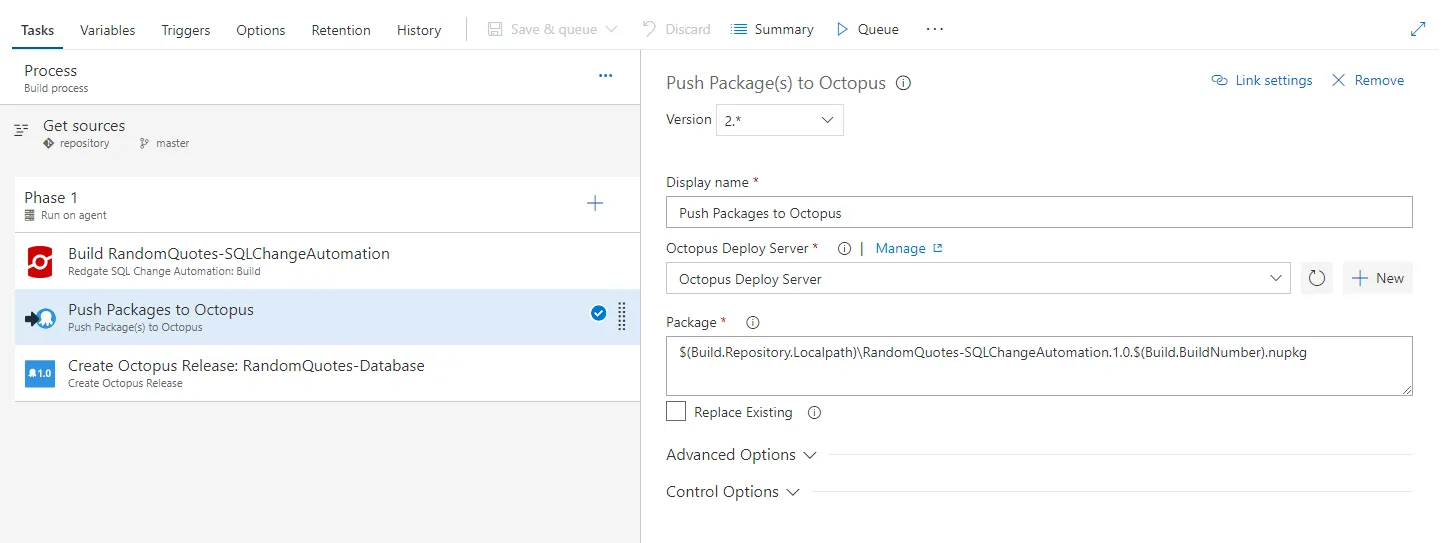
Here is the full value, if you’d like to copy it:
$(Build.Repository.Localpath)\RandomQuotes-SQLChangeAutomation.1.0.$(Build.BuildNumber).nupkgThe Octopus Deploy server must be configured in VSTS/TFS. You can see how to do that in our documentation.
The last step is to create a release and deploy it to dev. After connecting VSTS/TFS with Octopus Deploy, you can read all the project names. You can also configure this step to deploy the release to dev. Clicking the Show Deployment Progress will stop the build and force it to wait for Octopus to complete:
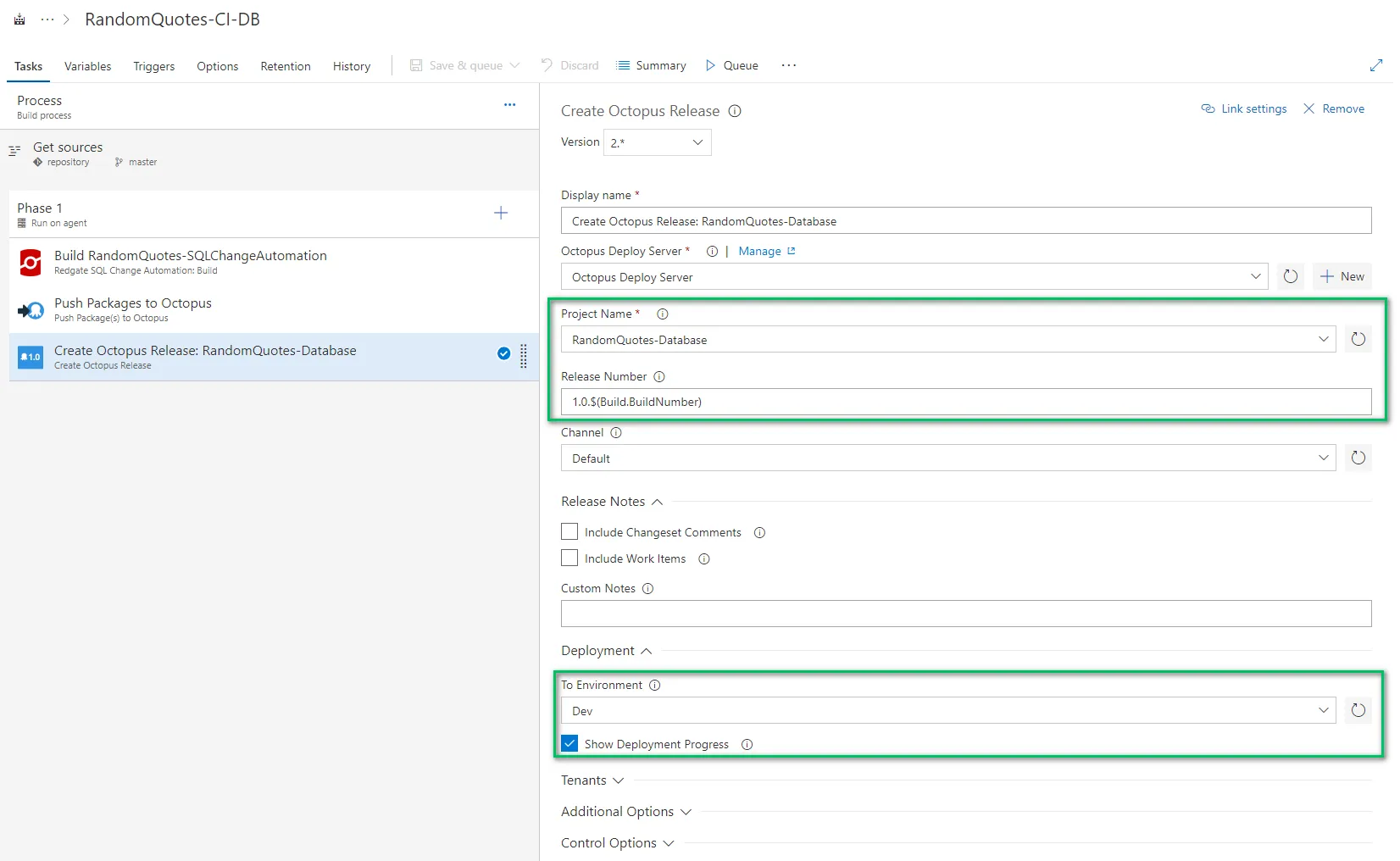
TeamCity
The TeamCity setup is very similar to the VSTS/TFS setup. Only three steps are needed:
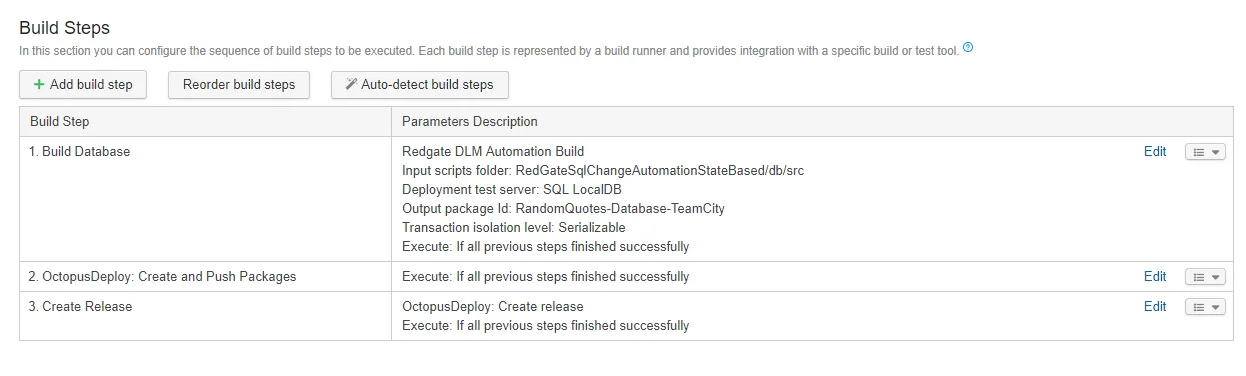
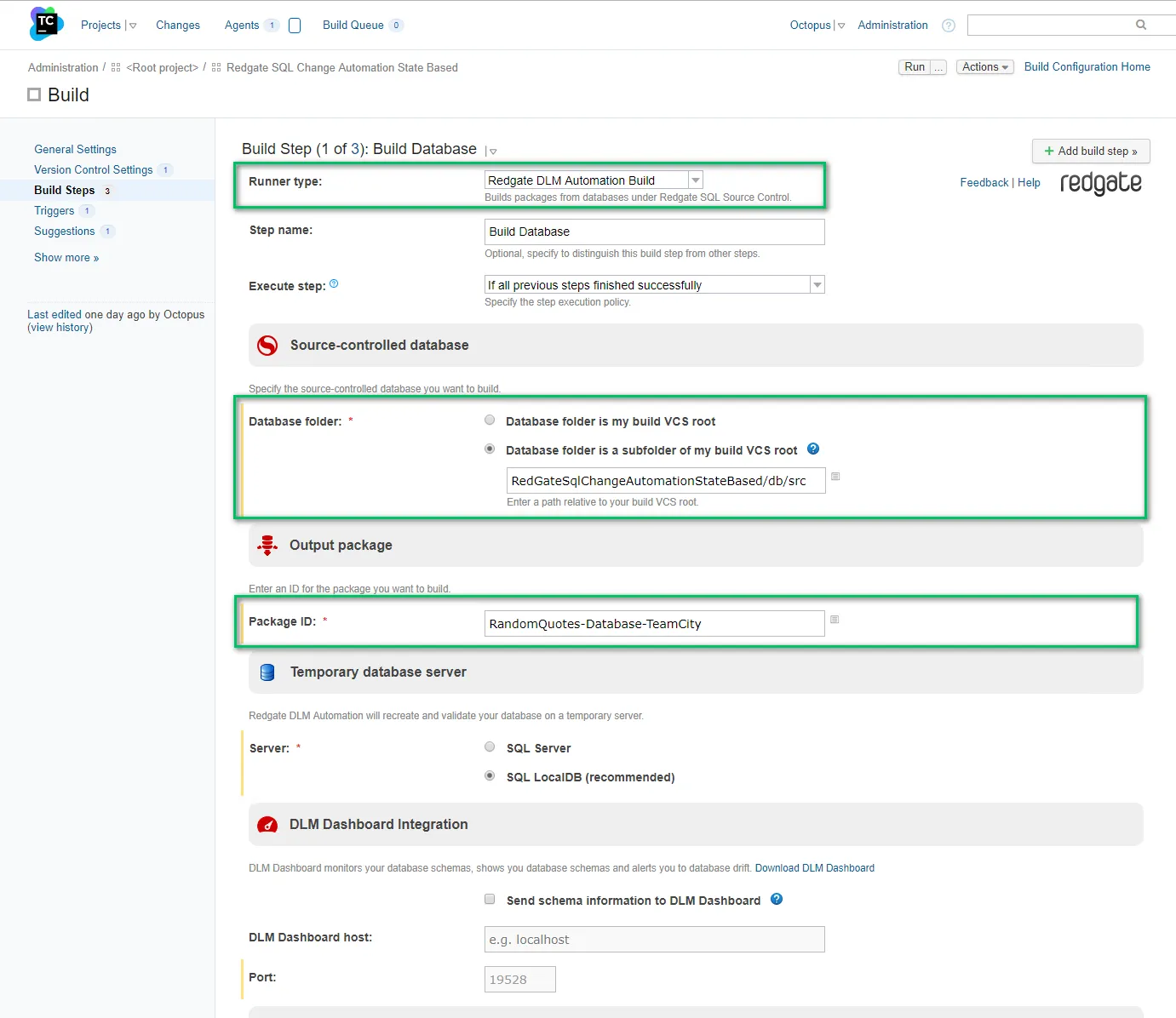
The first step is the build database package step, and it has similar options to VSTS/TFS. You need to enter the folder as well as the name of the package:
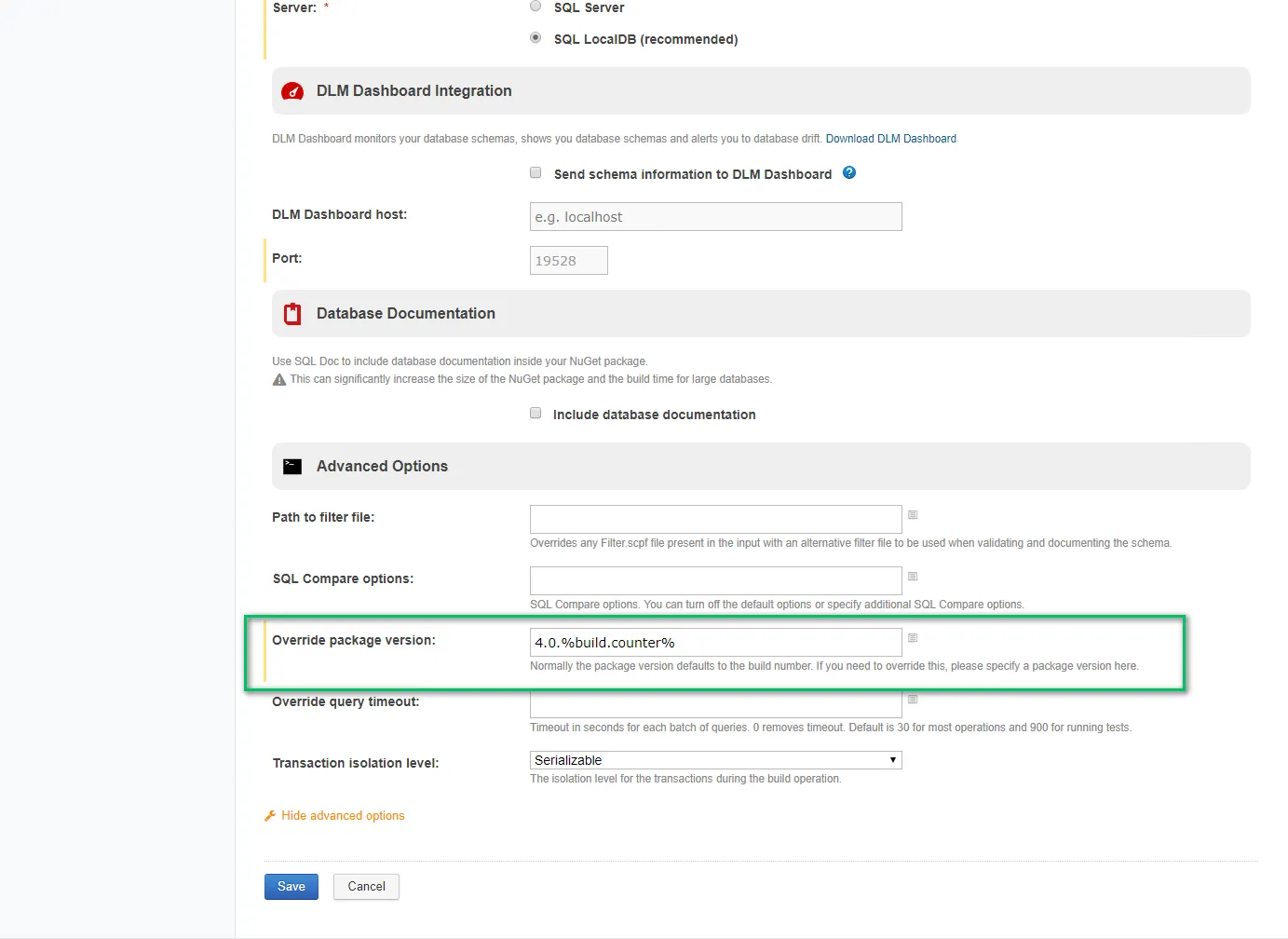
You have to enter a package version in the advanced options, or you will get errors from the Redgate tooling about an invalid package version:
The publish package step requires all three of the options to be populated. By default, the Redgate tool will create the NuGet package in the root working directory:
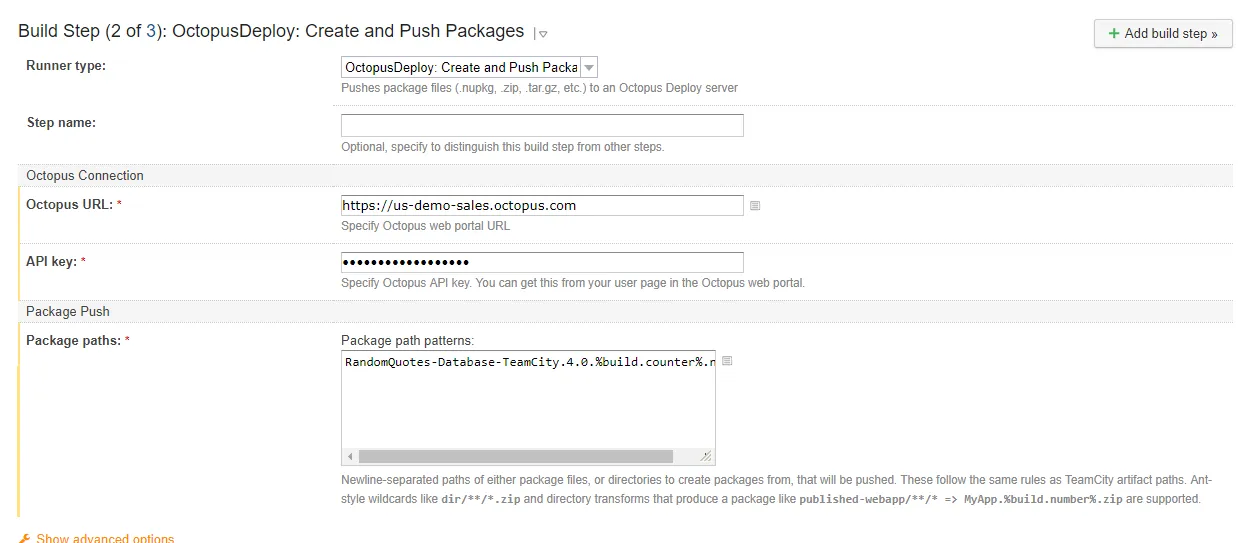
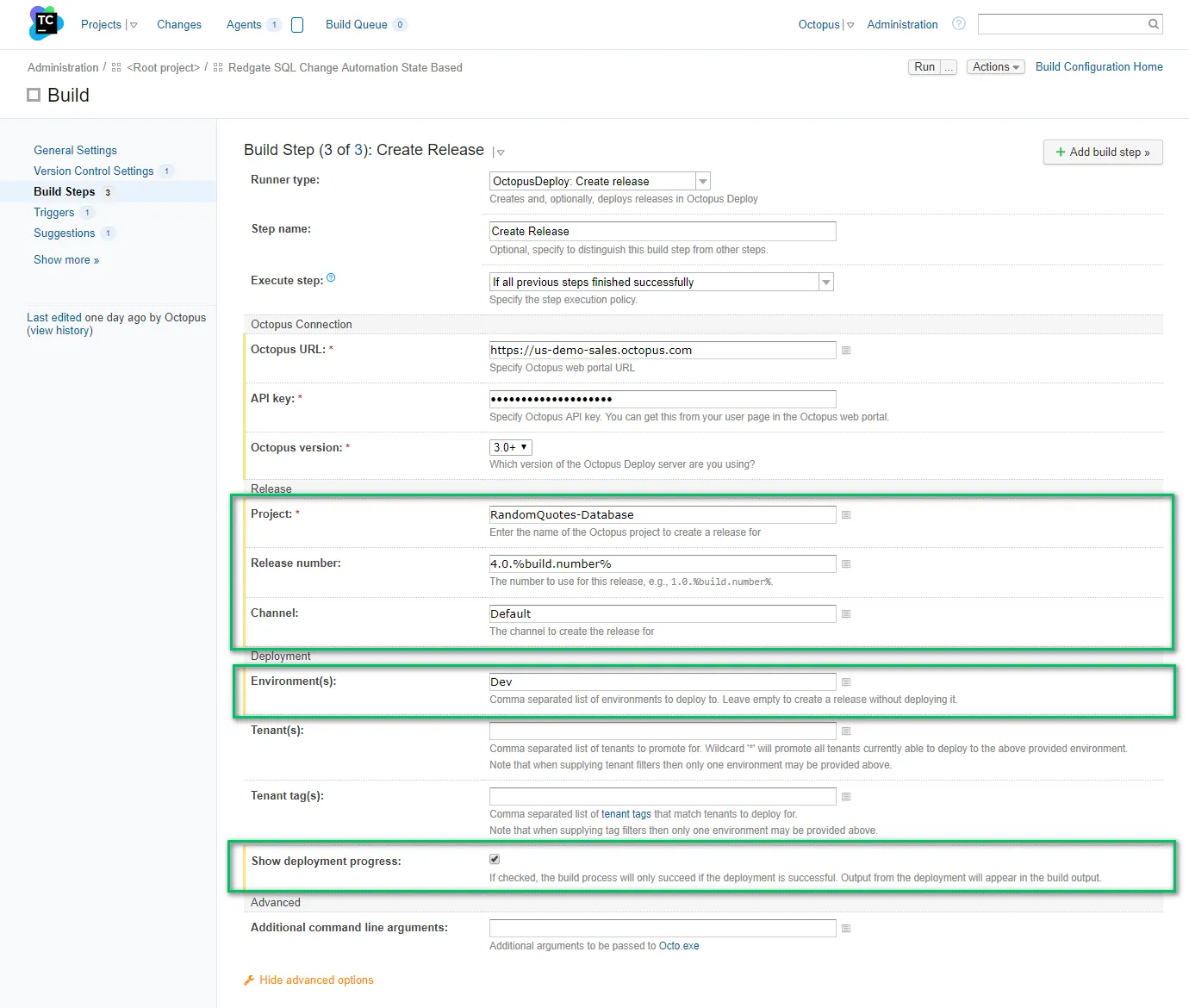
The final step is creating and deploying the release. Provide the name of the project, the release number, and the environment you are deploying to:
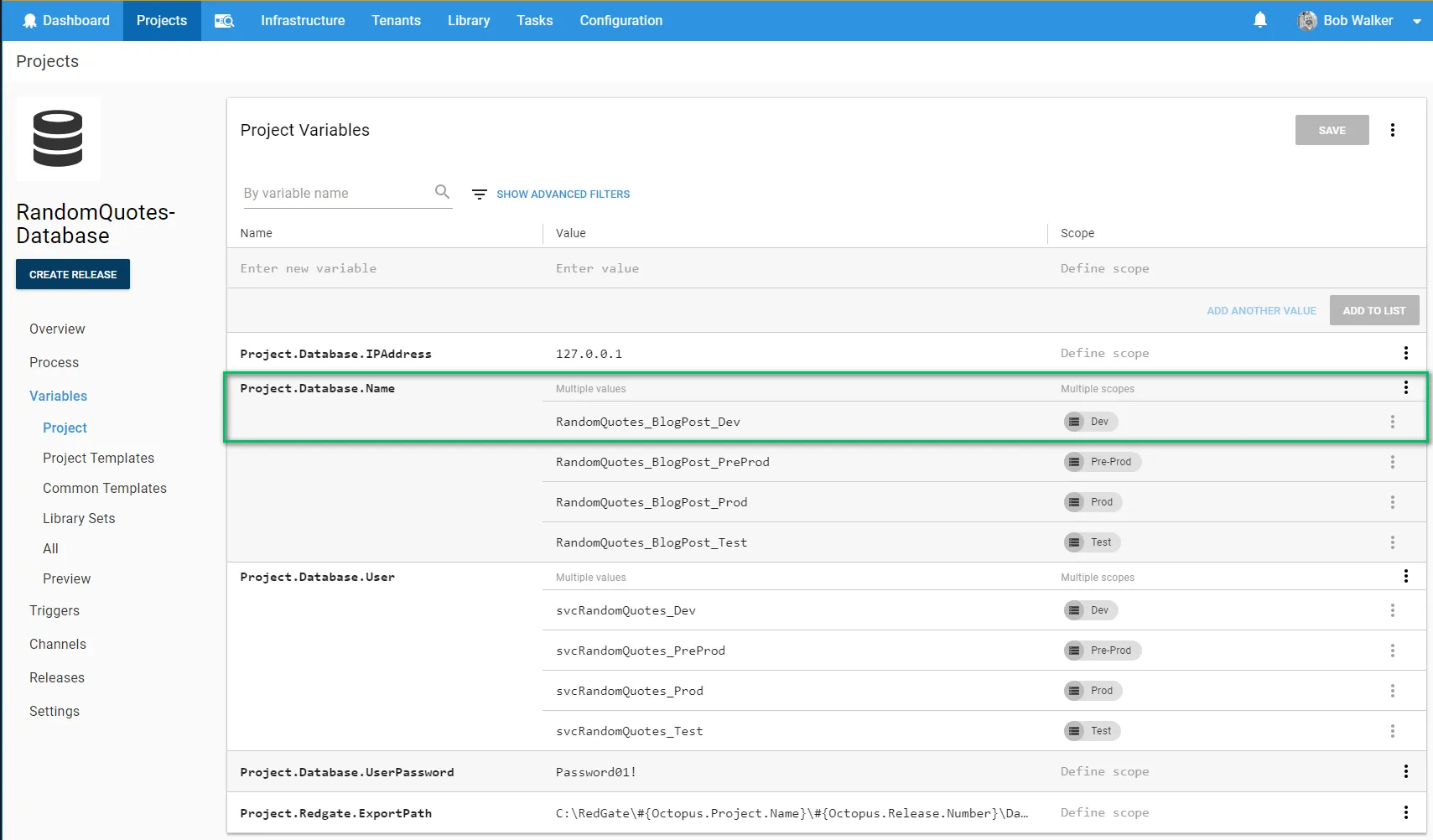
See the CI/CD pipeline in action
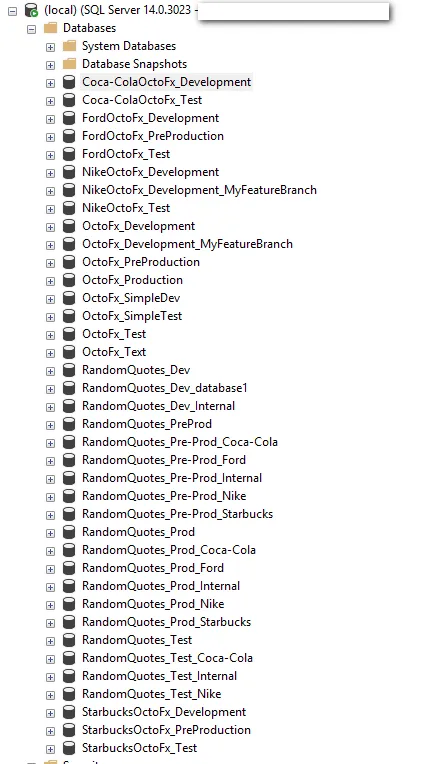
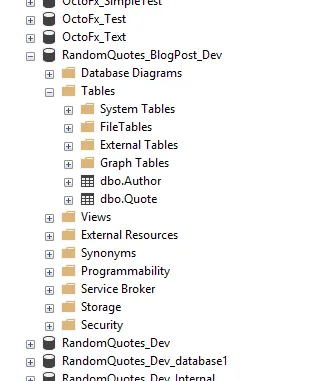
Now it’s time to see all of this in action. For this demo, I create a new database, RandomQuotes_BlogPost_Dev:
As you can see, I do not have any databases with that name. I have used this SQL Server as my test bench for automated deployments:
Let’s take a quick look at the tables stored in source control:
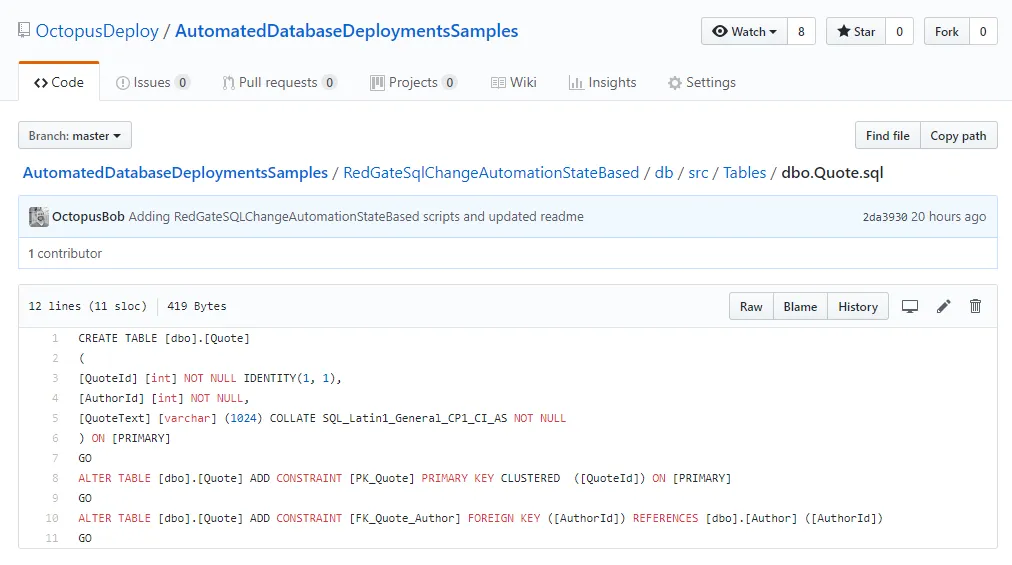
If we open one of those files, we can see the create script generated by Redgate’s SQL Source Control:
Kick off a build, and let’s see that whole pipeline in action. The build looks successful:
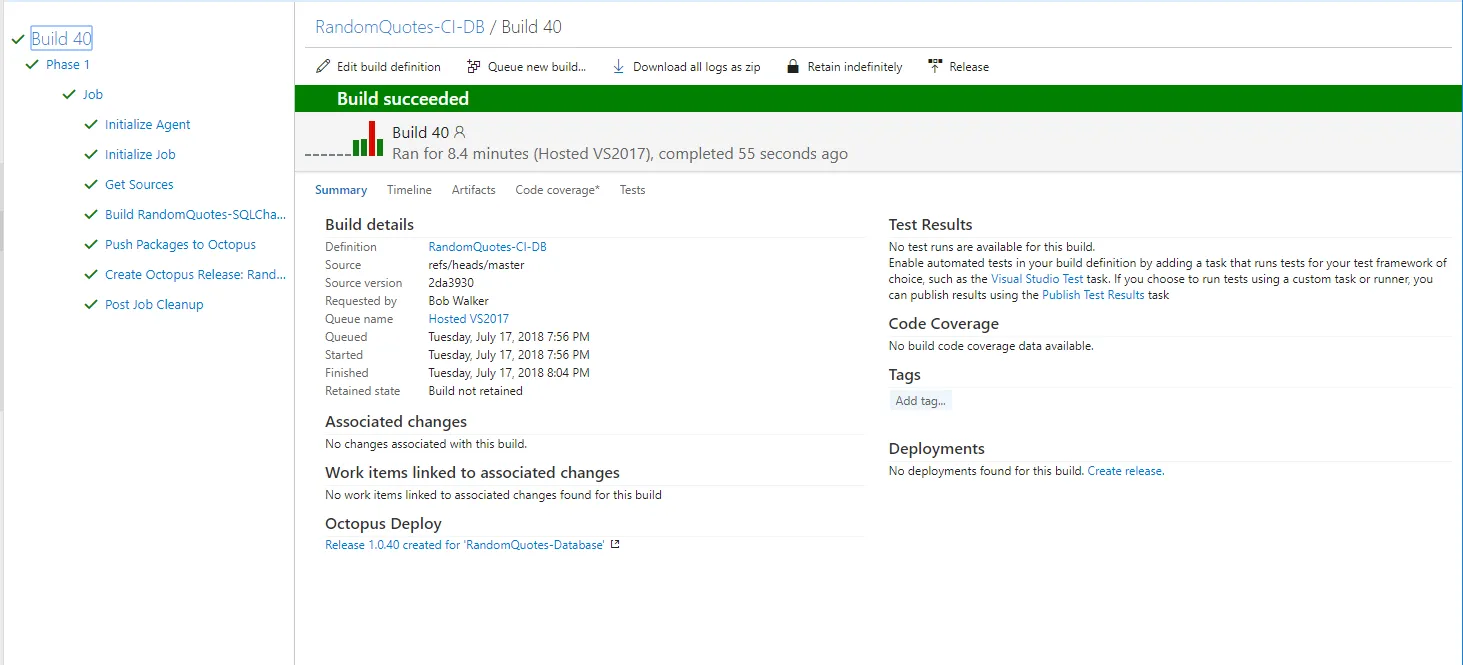
No surprise, the deployment was successful in Octopus Deploy. The VSTS/TFS build was set to wait on Octopus Deploy to finish deploying the database. If the deployment failed the build would’ve failed:

Going back to SSMS and we can now see the database and the tables have been created:
Changing the database schema
That works with an existing project, but let’s make a small database schema change and test the process. There is a bit more setup involved with this:
- Clone your forked repo to your local machine.
- Open up SSMS and create a random quotes database on your local machine or dev.
- In SSMS bind the source controlled database to the newly created database. You can read how to do that in the documentation.
When linking the database to source control, you need to provide the full path to the folder where the source control is stored. I store all my code in a folder called C:\Code.git. The full path is:
C:\Code.git\AutomatedDatabaseDeploymentsSamples\RedGateSqlChangeAutomationStateBased\db\src\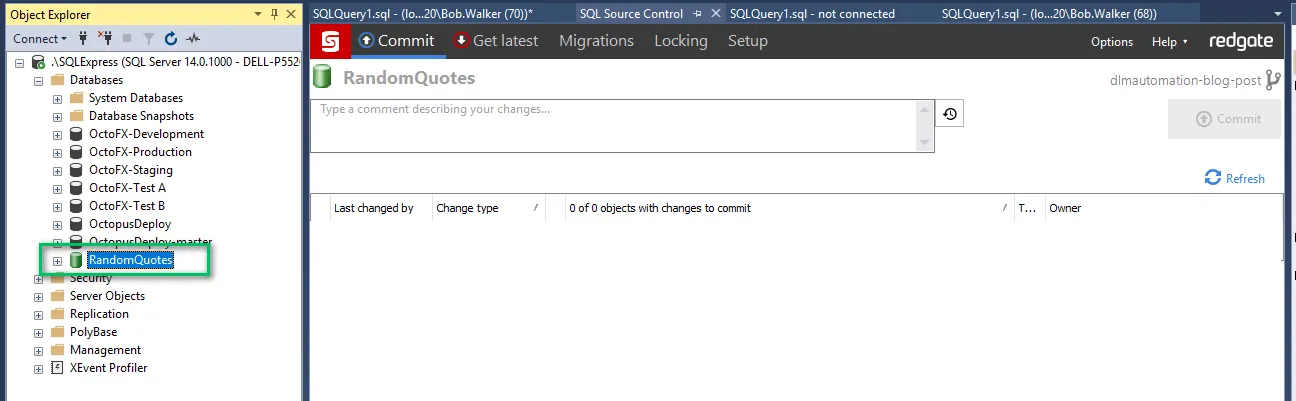
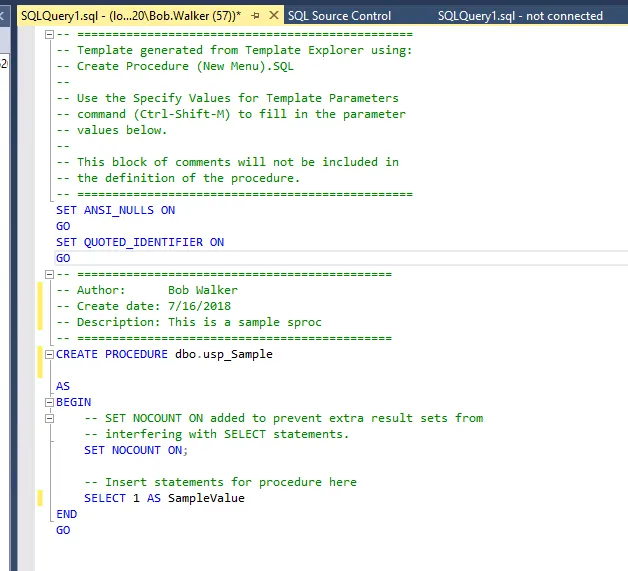
Now we can make the change to the database. For this test, let’s just add in a stored procedure which will return a value:
Now we can commit that change to source control:
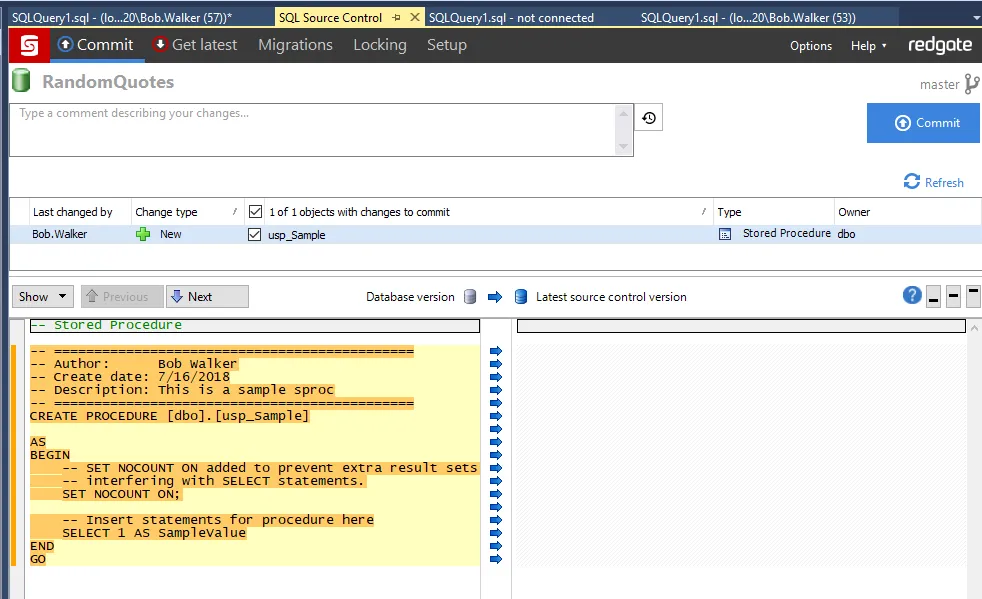
Assuming the CI/CD pipeline is set to fire on commit, you should see that new sproc appear in dev.
Conclusion
Database deployment automation does require a bit of prep-work, but the payoff is well worth the effort. The auditing alone is worth it. With this tool, I can now see who made a change, when a change was made, and when that change went into production. In the past, that was kept in another location with a 50/50 shot of it being updated.
As you start on this journey, my recommendation is to add the manual verification step to all environments until trust has been established. This will ensure you don’t accidentally check in a change that blows away half the team’s database changes.
Until next time, happy deployments!
Further reading
Posts in the database deployment automation series:
- Why consider automated database deployment
- Database deployment automation approaches
- Database deployment automation using state-based Redgate SQL Change Automation
- Using ad-hoc scripts in your automated database deployment pipeline
- Database deployment automation using Octopus and Redgate Deployment Suite for Oracle
- Database deployment automation using Jenkins and Octopus Deploy post deployment scripts for Oracle
- Using DbUp and Octopus workers for database deployment automation
- Automatic approvals for your database deployment automation
Related posts

Octopus Cloud architecture
Learn how cell-based architecture helped us make Octopus Cloud reliable and scalable.


Solutions engineer - the jack of all trades
Learn why being a jack of all trades is great when you're a solutions engineer.


How to bulk update the execution container image
Learn how to use an API script to update the image used for execution containers in deployment processes and runbooks.