

Self-service application deployment is a way of increasing the number of team members that can deploy to pre-production environments. Examples might include:
- Allowing developers to deploy to a development environment.
- Allowing testers to deploy to test environments.
- Allowing support team members to deploy to an environment for reproducing production bugs.
There are two main advantages to self-service deployments:
- It empowers the team to be able to deploy to pre-production environments.
- It decreases the dependency on release managers to be able to deploy.
For self-service deployments to work, the essential element is trust; we don’t want to simply allow everyone to start tinkering and making changes and modifying servers inconsistently, because that’s just going to guarantee that the next production deployment will go horribly wrong.
In this article, I want to talk about the important things to consider when planning for self-service deployment.
First, a story…
Prior to going full time on Octopus Deploy, I worked at an investment bank in the UK. There, we had a release manager, who I’ll call Mike. Mike was in charge of release management to the 1000+ servers that our various applications were deployed to.
Mike was brilliant. He wasn’t afraid of PowerShell or writing code to automate his work, and he’s one of the few people I know who can actually read Perl. Despite the large number of servers, he had managed to get the deployment process from start to finish down to about half a dozen steps, which he knew very well.
My team was a smaller team within the group that Mike served, and we liked to iterate quickly. Sometimes we’d deploy on a weekly basis, and if there were problems we’d fix them and redeploy a few hours later. Deploying to our dev and test servers wasn’t such a problem because we eventually got remote desktop access. Production, however, always required Mike to be involved: partly because only Mike had the permissions to deploy, and partly because only Mike knew how to do all the steps needed, and to recover if it all failed.
While we could deploy to dev and test ourselves, this caused problems. Sometimes we’d install a new component or run a migration script, and forget to document that for Mike. It worked fine in test, but when he went to deploy to production, the step would be missed, and we’d be in big trouble. Mike could also be quite scary!
Mike was brilliant, but he was a bottleneck. I like to think we were brilliant too, but we did things differently than Mike did, not intentionally but simply because humans are different.
When a production deployment goes wrong, no one is happy, and if it happens too frequently it can lead to conflict and disunity.
To increase our odds of a successful production deployment, there would have been three options:
- Have Mike do all the deployments, even to dev and test.
- Let us developers deploy to production.
- Spend a lot more time on documentation.
- Automate the deployments so that they are always run consistently, and implement a self-service model.
Option 1 wouldn’t have been workable; Mike was way too busy as it is. Option 2… let’s just say that was never going to happen! Option 3 is usually what large organizations default to, but wouldn’t have worked because a) we’d still forget things, and b) no one reads documentation anyway.
So that leaves option 4.
Requirements for self-service deployments to work
For self-service deployments to work successfully, and to maintain the trust and unity of the team, there are a number of basic requirements:
- Deployments must be automated.
- The deployment process should be consistent across environments.
- Some level of auditing, centralized logging and visibility is needed.
- Robust permissions system to restrict who can deploy what, where.
Let’s examine these in detail.
Rule 1: Deployments must be automated
If your deployment process involves someone opening remote desktop, copying a folder, editing a configuration file, or modifying a service, self-service deployments won’t work. No matter how well you document it, someone will forget a step, or forget to document a new step (such as running a SQL migration script). That means that when deploying to production, your chances of deploying successfully are decreased, because it’s too easy to have missed a step. This is going to breed mistrust and create conflict.
Where steps can’t be automated, you might like to use manual steps to pause a deployment part way through, and provide very, very specific instructions about what needs to be done.
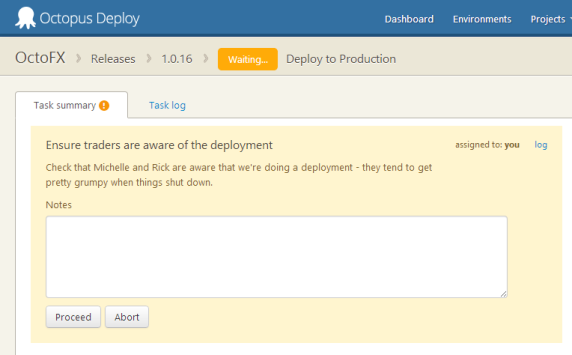
Rule 2: The deployment process should be consistent
Similar to the above, the deployment script has to be consistent between environments. Two or more different people are going to be performing deployments. Which of these scenarios is more likely to be successful?
- Developers and testers have been running one script for their deployments and it worked fine. A completely different script is going to be run in production.
- Developers and testers have been running one script for their deployments and it worked fine. The same script (with slightly different parameters) is going to be run in production.
Of course, there will be differences between environments, but these should be parameters/configuration variables for the deployment script; the script itself should be the same.
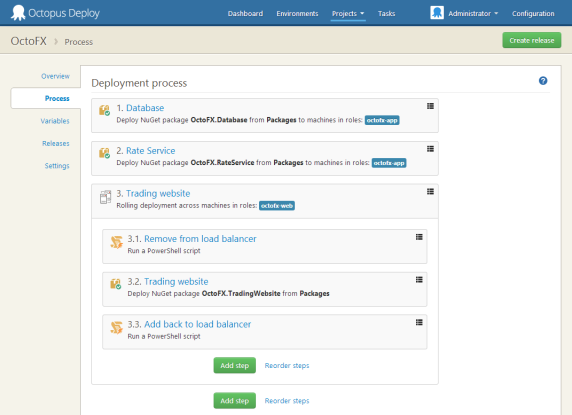
Rule 3: Auditing, centralized logging and visibility
If one person does all of the deployments, they know what version is deployed where. Once multiple people start to deploy, the need for visibility - a dashboard, for example - becomes very important. Ideally this dashboard shouldn’t require someone to remember to update it after they deploy.
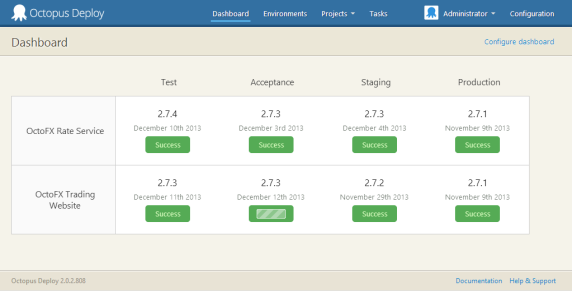
Likewise, auditing provides some accountability: who changed the deployment script? Who triggered that deployment? Who cancelled it?
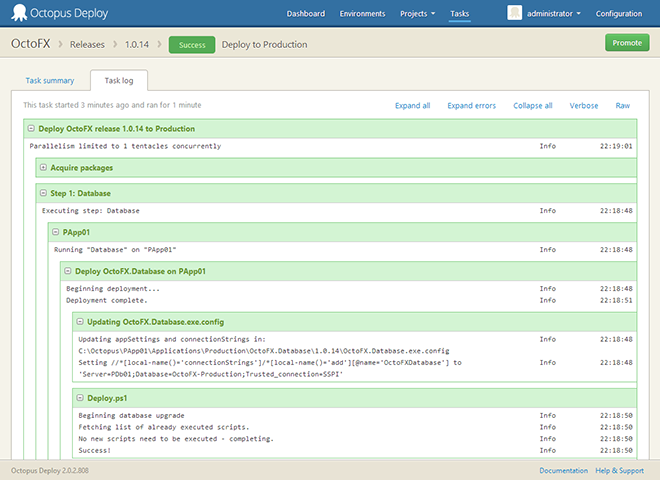
Finally, centralized logging is essential. If there’s a problem during the deployment, it’s important for team members to be able to see this easily, without needing to request access to all the servers involved. In Octopus, a single page shows the logs from the entire deployment from all servers.
Rule 4: Robust permissions
This goes without saying. Self-service deployment is about giving people permissions to deploy specific applications to specific environments, not for marketing interns to deploy mission critical applications to production.
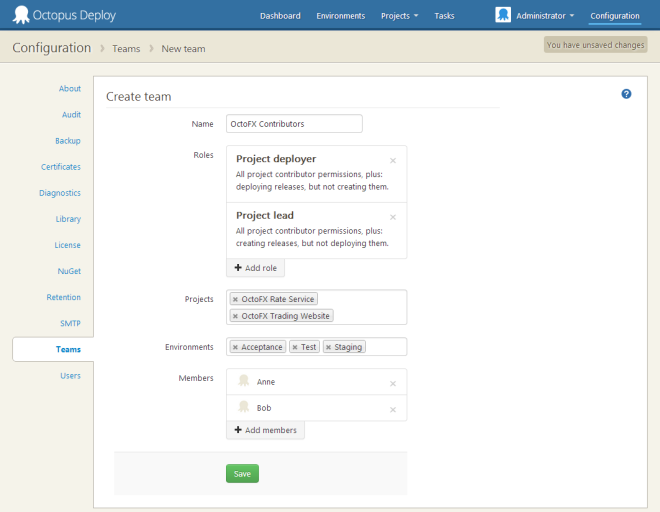
In Octopus, you can use Teams to control who has access to deploy specific applications to specific environments.
Summary
Self-service deployments are extremely empowering, and something that I think all teams could benefit from. But for self-service deployments to work, there needs to be trust. Release engineers need to trust that the same process is being followed in all environments, and that people aren’t just configuring servers willy-nilly. Increased visibility and accountability is also needed to ensure that everyone is on the same page and there are no surprised. Finally, there needs to be limits, and it’s probably a good idea to keep production deployments with the operations team.
Are there any other essential requirements that I missed? Leave a comment below!
Tags:


