

When I started building Octopus Deploy, I wanted to build something that worked well enough to release a beta and start getting feedback. I had plenty of experience with SQL Server and NHibernate/EF, so I decided to go with a SQL Server + EF Code First stack for my persistence layer.
In the recent 1.0 RC release, I switched Octopus to use RavenDB. In this post I’ll explain the reason for the change, and show how it is being used.
Where SQL Server was letting us down
About 6 months into the beta, the decision to use SQL Server started to become more and more of a constraint. I was getting great feedback and suggestions, and had a lot of feature ideas. But I noticed myself making feature trade-offs based on how complicated they’d make the database. I would avoid implementing feature suggestions that meant too many joins or too many intermediary tables. I felt like the rigid nature of SQL tables, and the tyranny of Cartesian products, was having too much influence on the application design.
Needless to say, that’s a terrible way to design a product. The needs of the application should take precedence over the needs of the database, not the other way around. And yet I found myself being almost “frugal” in what I decided to persist.
SQL Server also made the installation process more complicated. As a shrink-wrap product, the installation experience is hugely important to Octopus, because it’s the very first experience customers will have with the product. The assumption was that users would either install SQL Express, or use an external SQL Server.
Both of these were problematic. SQL Express meant yet another installer users needed to run. And using a standalone SQL instance meant all kinds of security configuration changes to allow the Octopus IIS process and Windows Service to talk to the database. I felt silly selling a product that is designed to make automated deployment easy, and yet had such a complicated installation process!
Why RavenDB?
The installation problems above suggested that SQL Server wasn’t a good choice for a shrink-wrap product. But there are plenty of embeddable relational databases that might have worked - SQLite or SQL CE, for example. What made RavenDB more attractive?
There were two reasons. The first was that our problem domain - deployment automation - seemed to naturally lead to a document-oriented data model over a relational model. With a relational model I found myself worrying about joins, while most of my use cases actually only revolved around a single document.
The second reason was architectural. Octopus is split into two separate processes, as you can see in the diagram below: a Windows Service which runs the deployments and scheduled tasks, and the IIS website.
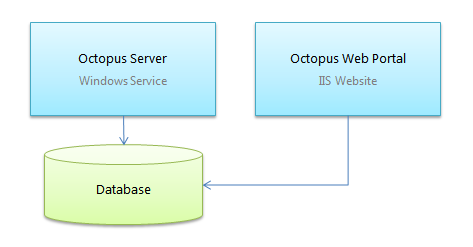
Any embedded option would need to be embedded in one process, but accessible via the other. With RavenDB this was easy - the Octopus Server hosts an embedded RavenDB instance, which also listens on port 10930 using Ravens embedded HTTP listener, and the web site connects to RavenDB on that port. This gives me a lot of flexibility; you can actually spin our secondary Octopus Server and web site instances all using the same embedded database.
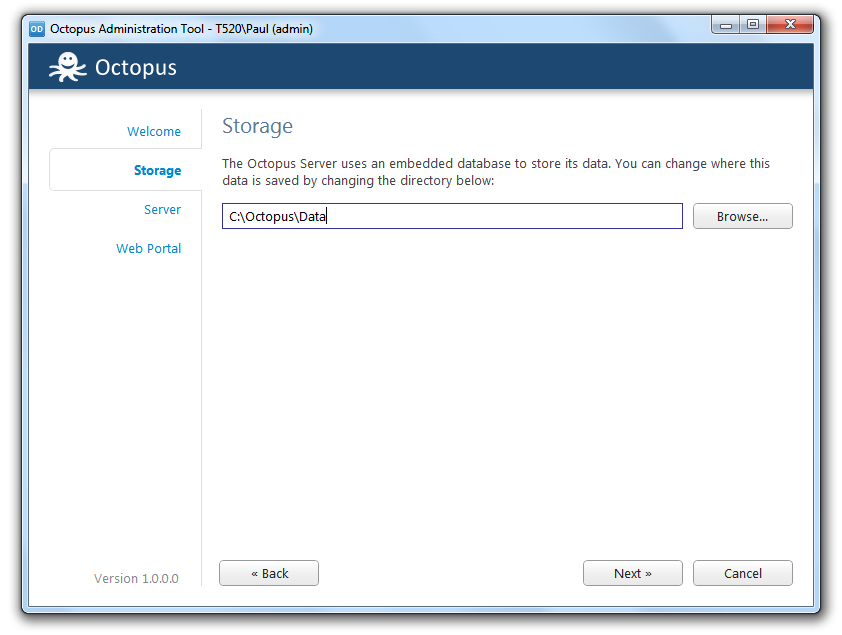
This set up vastly simplified our installation process too. Now, when you install Octopus, the only mention of a database is a “Storage” tab where you can choose where the data is stored:
Document design
The biggest adjustment I had to using a document database like RavenDB was figuring out how the documents would look. In Octopus we have the following main documents:
- Environment: Name, description, machines, health check results
- Project: Variables, steps
- Release: Variable and steps snapshots, release details, selected package versions
- Deployment: Target environment, options
- Task: Started, ended, duration, output log
- User: Name, email
- Group: Name, child groups, member users
The advantages of this design are obvious - for example, when we are dealing with a release, we often need to know the steps (packages to install, scripts to run, etc.). So instead of inner joins, we get that information in a single document. That makes it much nicer to work with.
Documents also make it much easier to model inheritance relationships. For example, Octopus will have many types of “steps”: deploy a package, run a PowerShell script, wait for a user to manually intervene, and so on. These are modelled using an abstract base class. This is certainly possible to represent in a relational database, but it certainly isn’t fun. In RavenDB, it is fun. I’m free to build features exactly as I want, without worrying about crazy joins or cascade deletes. I feel liberated.
How we use RavenDB
I have a theory that 90% of performance problems in applications aren’t caused by bad algorithms, but by bad architecture - having layers of services and managers and repositories between a controller and an ORM, for example.
In Octopus we keep things simple - ASP.NET MVC controllers interact with the RavenDB IDocumentSession directly:
public class GroupsController : OctopusController
{
readonly IDocumentSession session;
public GroupsController(IDocumentSession session)
{
this.session = session;
}
public ActionResult Index(int skip = 0)
{
var groups = session.Query<Group>().OrderBy(g => g.CanBeDeleted).OrderBy(g => g.Name).ToList();
return View(new GroupsModel(groups));
}
}Or at most, a controller calls a command or a builder, which interacts with the session directly. For example, this command saves a NuGet feed:
public class SaveFeedCommand
{
readonly IDocumentSession session;
public SaveFeedCommand(IDocumentSession session)
{
this.session = session;
}
public void Execute(EditFeedPostModel input)
{
var feed = string.IsNullOrWhiteSpace(input.Id) ? new Feed(input.Name, input.FeedUri) : session.Load<Feed>(input.Id);
feed.Name = input.Name;
feed.FeedUri = input.FeedUri;
if (input.ChangePassword || !input.IsExisting)
{
feed.SetCredentials(input.Username, input.Password ?? string.Empty);
}
session.Store(feed);
}
}We use the standard ActionFilter pattern for opening the document session when the request begins, and saving changes when the request completes.
Queries
I was speaking to a friend who just started using MongoDB on a project, and one of the things he’s struggling to come to terms with is the need to define map/reduce indexes. One of my favorite RavenDB features is that generally, you can just use the LINQ support and RavenDB will create the indexes implicitly.
We do make use of a small number of custom indexes though, and these are mostly used for projections. For example, in Octopus, a Group contains a list of ID’s of users who are in that group - for example, the “Team Leaders” group might contain the ID’s of “Bob” and “Alice”. Often, we need to query that relationship in reverse, to answer questions like “what groups is Alice a member of”? This is achieved using a map/reduce index:
public class UserGroups : AbstractIndexCreationTask<Group, UserGroups.Result>
{
public UserGroups()
{
Map = groups => from g in groups
from u in g.Users
select new Result {UserId = u, GroupIds = new[] {g.Id}};
Reduce = results => from r in results
group r by r.UserId into g
select new Result { UserId = g.Key, GroupIds = g.SelectMany(i => i.GroupIds).ToArray() };
}
public class Result
{
public string UserId { get; set; }
public string[] GroupIds { get; set; }
}
}At the moment we only have three custom indexes - the vast majority of our queries use the implicit indexes created via LINQ queries.
Caching
Some people, when confronted with a performance problem, think “I know, I’ll use caching”. Now they have two performance problems.
Cache invalidation is notoriously hard to get right, and so in Octopus we actually avoid it - there’s only a couple of places where we explicitly use caching, and neither of them are for caching database results (they’re actually NuGet feed lookups).
Now, this feature is often brushed over in RavenDB, but RavenDB actually gives you caching out of the box. No really, read that again. RavenDB gives you caching out of the box. This is HUGE! And even more importantly, it doesn’t have invalidation problems.
Ayende explains the feature on his blog, but let me explain it as if SQL Server implemented the feature. First, you issue a query like this:
SELECT * FROM User where IsActive = true100 results are returned.
A few seconds later, maybe in another HTTP request, you issue the same query:
SELECT * FROM User where IsActive = trueOnly instead of executing the query and hitting the disk again and streaming the results a second time, imagine if SQL simply returned a message telling you nothing has changed since the last query, and you should re-use the original results if you still have them.
Can SQL Server do this? No, it can’t. You could issue a query that takes SQL Server 10 seconds to execute, and then issue it again immediately after, and it’s going to spend another 10 seconds computing the same result that it already did, even though surely it ought to know that nothing has changed.
With RavenDB, if you already have the results in memory, you can submit the ETag from the original HTTP result, and RavenDB will tell you whether the results would have changed by checking the index status. And the Raven client library does this for you. This is a brilliant feature that deserves more publicity.
Automatic backups
I once worked on a team that used TeamCity running on a VM. One day, the VM crashed. We’d been using the embedded database, and never set up any kind of backup system. So the data was lost, and we lost a couple of days just getting everything set up again.
When you install Octopus, it automatically backs up its own database every two hours. By default it’s backed up underneath the same folder as the RavenDB database, but we make it really easy to change - for example, you’ll probably point this to a file share which is backed up:
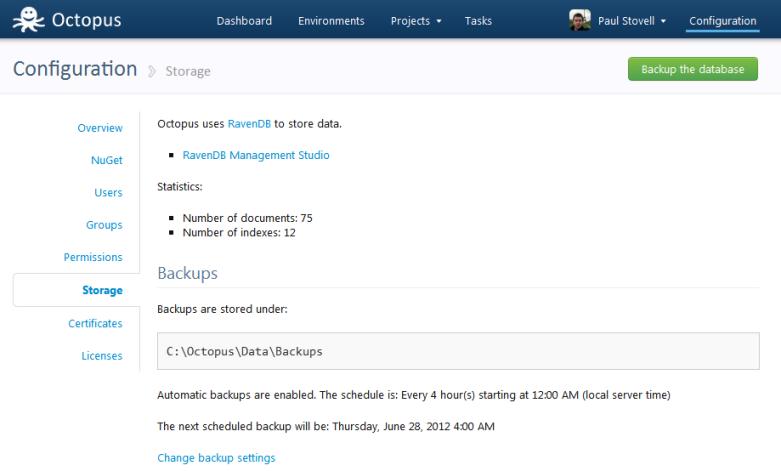
We do this by embedding the RavenDB Smuggler library, and having a scheduled Octopus task that automatically performs an “export” of the database to a configured folder.
RavenDB does have a backup/restore feature, which has some benefits (index results are backed up, for example) but also some downsides (it is more strict about OS compatibility between the machine the backup was created on and the machine it is restored to). Since a backup that can’t be restored isn’t very useful, for the sake of safety I chose to use the import/export feature instead of backup/restore as the default.
Should we support both?
One question I was asked was:
Could you the data store a choice? For example, users could choose whether to use RavenDB or SQL Server during installation.
If I had chosen an alternative relational model this would have been a possibility - for example, NHibernate supports plenty of database providers. But NHibernate doesn’t support RavenDB, and that’s not because it just hasn’t been implemented, but because they are fundamentally different models. Trying to support both would have meant being unable to really take advantage of the features of either, and I’d end up with the worst of both worlds.
Besides, while requiring SQL Server put the data storage front-and-center for users installing the product, I’m hoping that the choice to use RavenDB will fade into he background. When the application maintains itself, who cares which technology is used? It’s an implementation detail.
Conclusion
Switching to RavenDB took a little time, most of which was re-writing the application to make the most of the advantages offered by a document-oriented persistence model. RavenDB’s embedded nature has made our installation process simpler, and I feel like the application is much less constrained.
RavenDB is an awesome product, and while SQL Server still has its place, I feel like RavenDB has hit a real sweet spot. Apart from a reporting solution, I can’t actually think of a single SQL Server-based application I’ve worked on in the past that wouldn’t have worked better as a document store.
Time will tell how the NoSQL movement will pan out, but personally I feel much happier using a document database than I ever have using a relational database, and especially for this application.
Tags:


