

Very soon we’ll be launching Octopus: High Availability (HA) edition. In May, Damian wrote about the kinds of scenarios High Availability is designed to support. Lately, Shane’s been pushing Octopus servers to their limits to ensure nodes distribute load and to find bottlenecks. To prepare for High Availability, we’re making a few changes which will make it easier to manage Octopus server workloads.
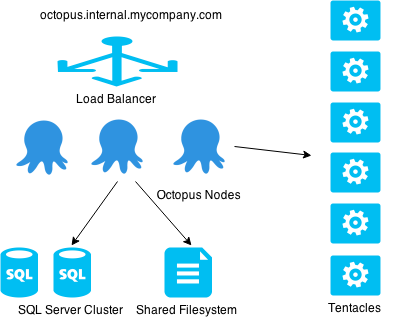
First, a quick recap: With Octopus: HA, a load balancer splits requests between multiple Octopus servers. Each Octopus server handles web requests, but will also execute background tasks (such as deployments and health checks). Behind the Octopus servers are shared storage - a shared SQL Server database and a shared filesystem used for task logs, artifacts and NuGet packages.
Deployment speed vs. latency
Octopus servers do quite a lot of work during deployments, mostly around package acquisition:
- Downloading packages (network-bound)
- Verifying package hashes (CPU-bound)
- Calculating deltas between packages (I/O and CPU bound)
- Uploading packages to Tentacles (network-bound)
- Monitoring Tentacles for job status, and collecting logs
When performing very large deployments (many large packages going to hundreds of machines), it’s pretty clear that at some point, the hardware is going to limit how many of these things a single Octopus server can do concurrently. If a server overcommits itself and hits these limits, timeouts (network or SQL connections) will begin to occur, and deployments can begin to fail.
Of course, Octopus: HA helps to solve this by having multiple Octopus servers. Note that the shared storage isn’t actually much of a bottleneck during a deployment - it’s the local hardware on the Octopus server that’s impacted much more heavily during deployments.
An ideal situation would be an Octopus server that’s performing as many parallel deployments as it can, while staying just under these limits. In practice, this is very difficult to predict. We tried various experiments to try and tell whether we should continue to consume new tasks, or to back off, by looking at system metrics, but it’s hard to do this reliably. There may be plenty of CPU/memory/I/O available right now, so we pick up one more task, and suddenly the other tasks that we were running begin a step that needs to run on hundreds of machines, and suddenly we’ve overcommitted ourselves again.
To make this “auto-tuning” approach work, we realized we’d need to continually readjust how many tasks were running in parallel. If deployment A suddenly steals all the CPU to calculate SHA1 hashes, deployment B might need to wait a little bit before it proceeds. Various approaches exist that could have worked here - dedicated worker threads for certain activities, or throttling up or down the threads performing the parallel activities. It would at least end up being nice and fair, like this:
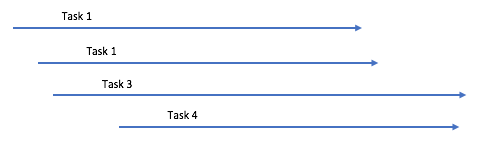
At first glance, it seems better than this, right?

The more we went down this path, we realised that this was the wrong tradeoff - we’re running the risk of making deployments slower just to try and do more of them in parallel. Given that Octopus is a deployment automation tool, downtime during deployments is an important consideration! If you’re doing a production deployment to ten machines, we want them to finish quickly, not slowly trickle out because someone else queued a deployment. We should sacrifice overall latency for speed.
Running task cap
The simplest and most reliable way we’ve come up with so far is to just limit the number of tasks that can run on a node at any one time, and make it user configurable. To manage this, we have a new setting that you’ll be able to configure on a per-node basis.
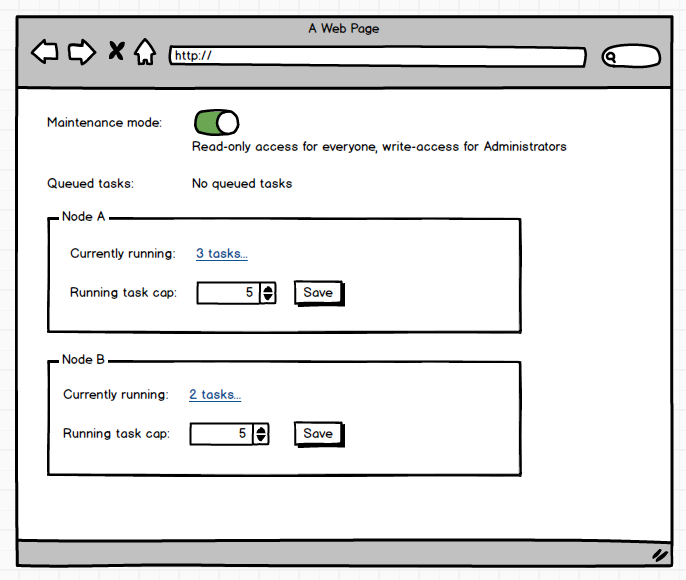
This running task cap will be set to a default value, and you’ll be able to bump it up or down to whatever works for you. It may not be a “smart” solution, but given that deployment speed is probably more important in more scenarios than concurrency, I think it’s a good tradeoff. The setting will be on a per-node basis, and it will be available for non-HA setups too.
Server draining
This setting also provides another feature for free. When it’s time to restart an Octopus server, or to install Windows Updates, it’s nice to be able to shut the server down gracefully, and allow other nodes to pick up the slack.
For this to work, we need to:
- Stop running any newly queued tasks, but let already-running tasks continue running until they finish
- Continue serving web requests
- Remove the server from the pool
- Once traffic is no longer going to the server, and all running tasks have finished, stop the service and apply any changes
The same running task cap setting can be be used to perform this “drain” - all we need to do is set it to 0! Tasks that are already running will continue to run, but tasks that are queued will remain queued unless another server picks them up.
Tags:
