

Sometime in the near future (post 3.0) we’re going to be releasing a High Availability edition of Octopus Deploy. We have customers using our product to automate the deployment of applications for hundreds of developers, to many hundreds of machines. For these customers, Octopus Deploy is a critical piece of their development infrastructure and downtime has a significant cost.
Currently with the architecture of Octopus Deploy we don’t have a good high availability scenario. We ship by default with an embedded RavenDB and have a lot of dependencies on the file system for message persistence. We do support moving to an external RavenDB cluster, but our networking and messaging stack means that having more than one Octopus Server just wouldn’t work.
With 3.0, our support of SQL Server means that we can support a SQL Server cluster. This is fantastic news for a lot of people who already have the infrastructure and support for SQL Server in a clustered environment. However we’re doing extra work to make the Octopus Deploy server cluster aware in it’s communications, and task management.
We’ve had various requests for different topologies to support in a high availability scenario, so in this post I’m going to talk about what we are and aren’t planning to support, and what we’ll probably support in the future.
So here goes.
The main scenario we want to support is a highly available and load balanced configuration with a SQL Server cluster and multiple Octopus Servers behind a load balancer.
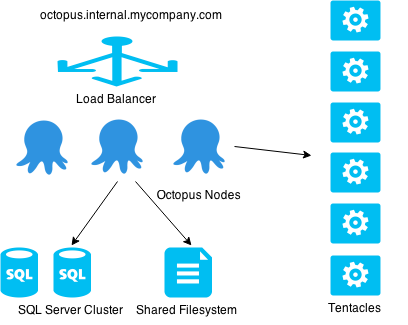
This will give you fault tolerance at the Octopus Server level, a machine failing would be picked up by the load balancer health check and all traffic would be routed to the other nodes. SQL Server availability will be taken care of via SQL Server and Windows Clustering services.
You’ll notice that as well as the SQL Server infrastructure, Octopus also needs a file share for packages, artifacts and log files.
Scenarios that don’t make sense to us.
We have some customers who want to keep data centers separate, either to keep their Production and Development environments segregated for security reasons, or have multiple regions and want to save on bandwidth or latency.
We think that the most manageable way to achieve this is via Octopus to Tentacle communication, routed via VPN if necessary. This scenario is secure (and by secure, I mean that any system is as secure as it’s weakest link, and the TLS security we use for Tentacle communication is not the weakest link in nearly all scenarios), and will perform well from a latency point of view.
For customers with multiple data centers in different regions who are concerned with the data transfer of large Nuget packages to multiple tentacles, we would recommend replicating or proxying your Nuget server into each region and through DNS aliasing have the tentacle fetch packages from geographically local package repositories. Or, an even simpler solution than that is have two separate but identical Nuget repositories and have the Feed ID as a variable.
Some of the requested configurations that we don’t plan on supporting are :
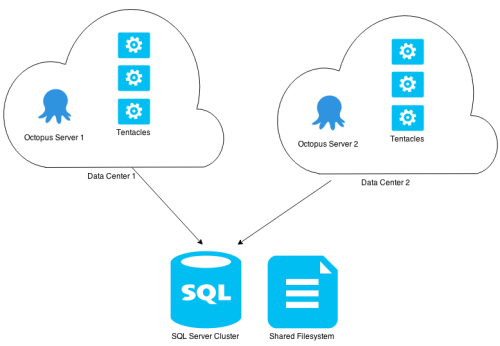
In this instance, Octopus Servers in different data centers share a common database and fileshare.
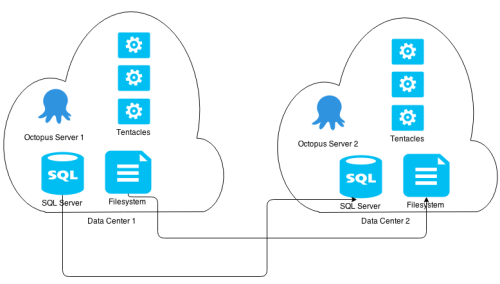
Independent Octopus Servers and Environments having local SQL Servers and Fileshares which are replicated.
Both of these won’t work properly as each Octopus Deploy server wouldn’t be able to see Tentacles in the remote environments meaning that health checks and deployment tasks will fail. Additionally, we believe that the latency of remote SQL Server communications and a replicated or shared filesystem will result in performance that is not as good as Octopus to Tentacle communications in those environments. These configurations also don’t cater to any security concerns customers have about visibility between environments.
Some alternative solutions
While not strictly High Availability solutions, for those customers who really want to have segregated environments, we do have two options which may work for them.
Migrator Tool
For 3.0 we needed to build a way to migrate a 2.6 RavenDB database to 3.0. What started as a database tool is turning into a general purpose Octopus Deploy migration and data replication feature. With this it would be possible to transfer project configuration and releases to an upstream Octopus Server.
Relay Tentacles
This isn’t something we have now, but something that is potentially on our radar for 3.1 or 3.2. The concept of a Tentacle that can act as a relay, gateway or proxy to other Tentacles on a private network.
It would look something like this:
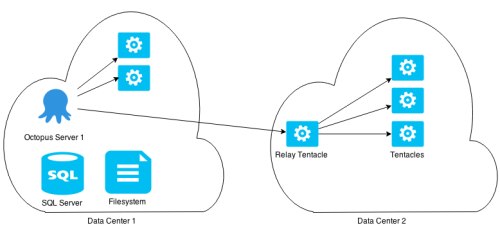
When you add a machine to an Environment, you’ll be able to specify how the Octopus server can route to it, and any task (Deployments and Health Checks) would go via this Relay.
A few closing thoughts
Octopus Deploy High Availability won’t be available for all editions. It is something we’ll release and sell as a new licensing tier and price point. To ensure we can support customers on this edition we’ll very likely provide some consulting and solution architecture to make sure it is running in a supported configuration to give us and our customers assurance that their Octopus Deploy infrastructure remains highly available.
