

The generative aspect of GPT has received a lot of attention. It’s easy to be impressed by the ability to create eye-catching images and videos or write sensible-sounding text from a few simple prompts. It’s also easy to understand how AI would augment the workflows of writing or drawing tools.
But how does AI benefit more traditional business processes? The answer is perhaps less exciting than being able to generate a highly detailed drawing of a kitten in a spacesuit eating rainbows from little more than that description. Still, it’s in these business-as-usual workflows that AI can have a significant impact.
I explored this question with GitHub to develop the Octopus Extension for GitHub Copilot. Satya Nadella announced Copilot extensions at this year’s Build conference. Octopus was 1 of 16 extensions for the initial launch:

In this post, I take you behind the scenes in building a Copilot extension.
The value of a Copilot extension
The sentiment behind the phrase “Code is written once but read many times” holds for Octopus deployments and runbooks. After you configure your Octopus space, most of your interaction is through initiating deployments, running runbooks, and viewing the results.
Most DevOps team members spend their days outside of Octopus. For example, developers spend most of their day writing and testing new features in their IDE. Octopus is a critical component of that workflow as it’s responsible for deploying changes to various environments for internal teams and external customers to access. But often, developers only need to know where their changes have been deployed or extract some useful entries from the deployment logs.
Here we see the result of the prompt @octopus-ai-app Show dashboard space "<space name>", which is a markdown version of the Octopus dashboard:
This prompt shows how the Octopus extension keeps you in the flow by removing the need to switch between applications to access the information you need. With a simple prompt, you can review the state of your deployments in the same chat window you use as part of your development workflow.
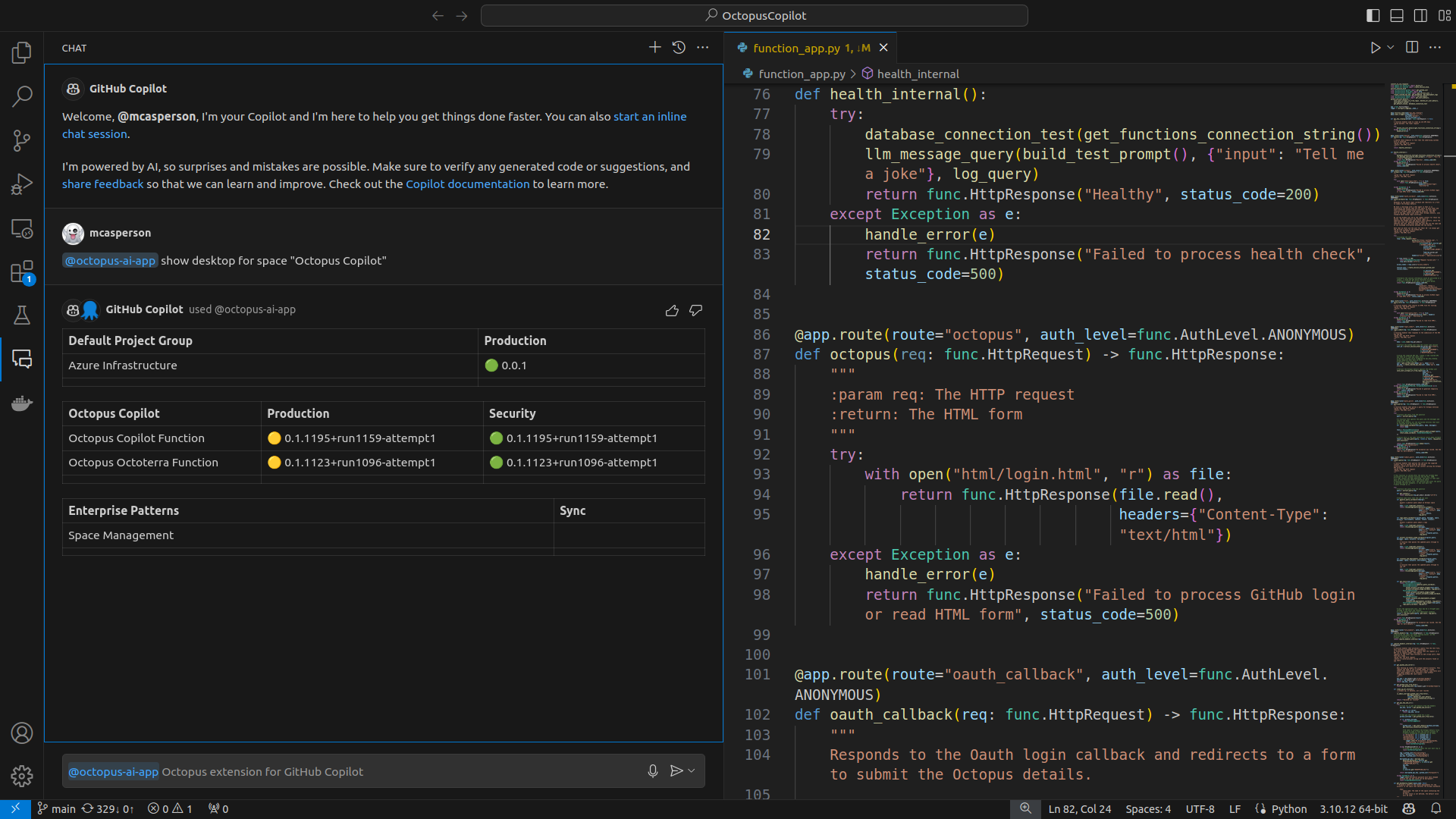
We can dig a little deeper with a prompt like @octopus-ai-app The status "Success" is represented with the 🟢 character. The status "In Progress" is represented by the 🔵 character. Other statuses are represented with the 🔴 character. Show the release version, release notes, and status of the last 5 deployments for the project "<project name>" in the "<environment name>" environment in the "<space name>" space in a markdown table.:
The cool thing about this prompt is that the extension has no special logic for mapping statuses to UTF characters or generating markdown tables. The ability to understand these instructions and generate the required output is inherent to the Large Language Model (LLM) that backs the Octopus extension.
This prompt also highlights how an AI agent improves on more traditional chatbots. The prompt is written in plain text rather than the fixed and often robotic instructions you have to formulate for a chatbot. The ability to understand complex prompts also means the Octopus extension can generate results far beyond the limited set of interactions that have to be hard-coded into a traditional chatbot.
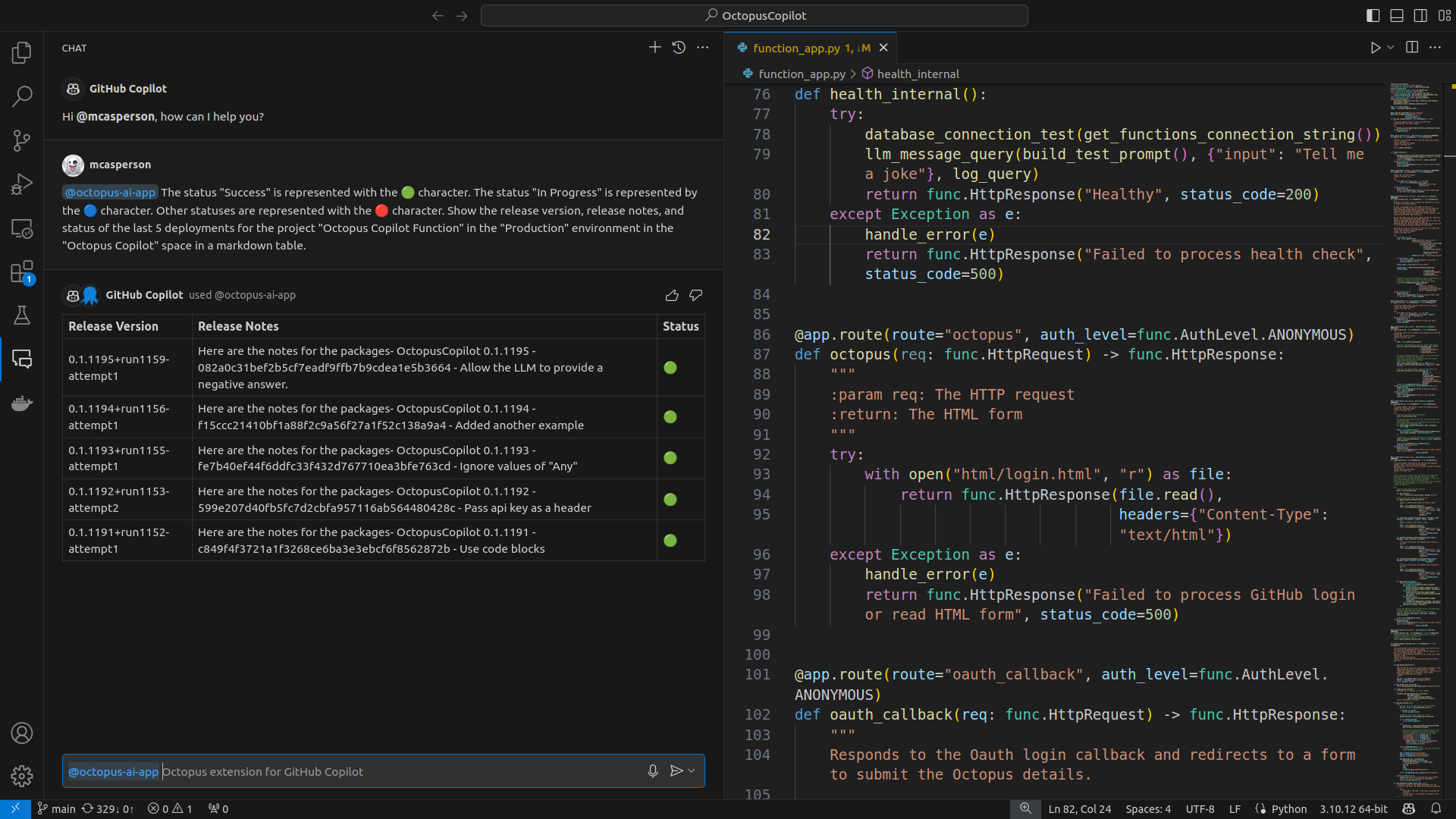
The prompt @octopus-ai-app Print any URLs printed in the last 100 lines in the deployment logs for the latest deployment for the project "<project name>" in the "<environment name>" environment in the "<space name>" space for step 1 is another example leveraging the ability of an LLM to understand instructions:
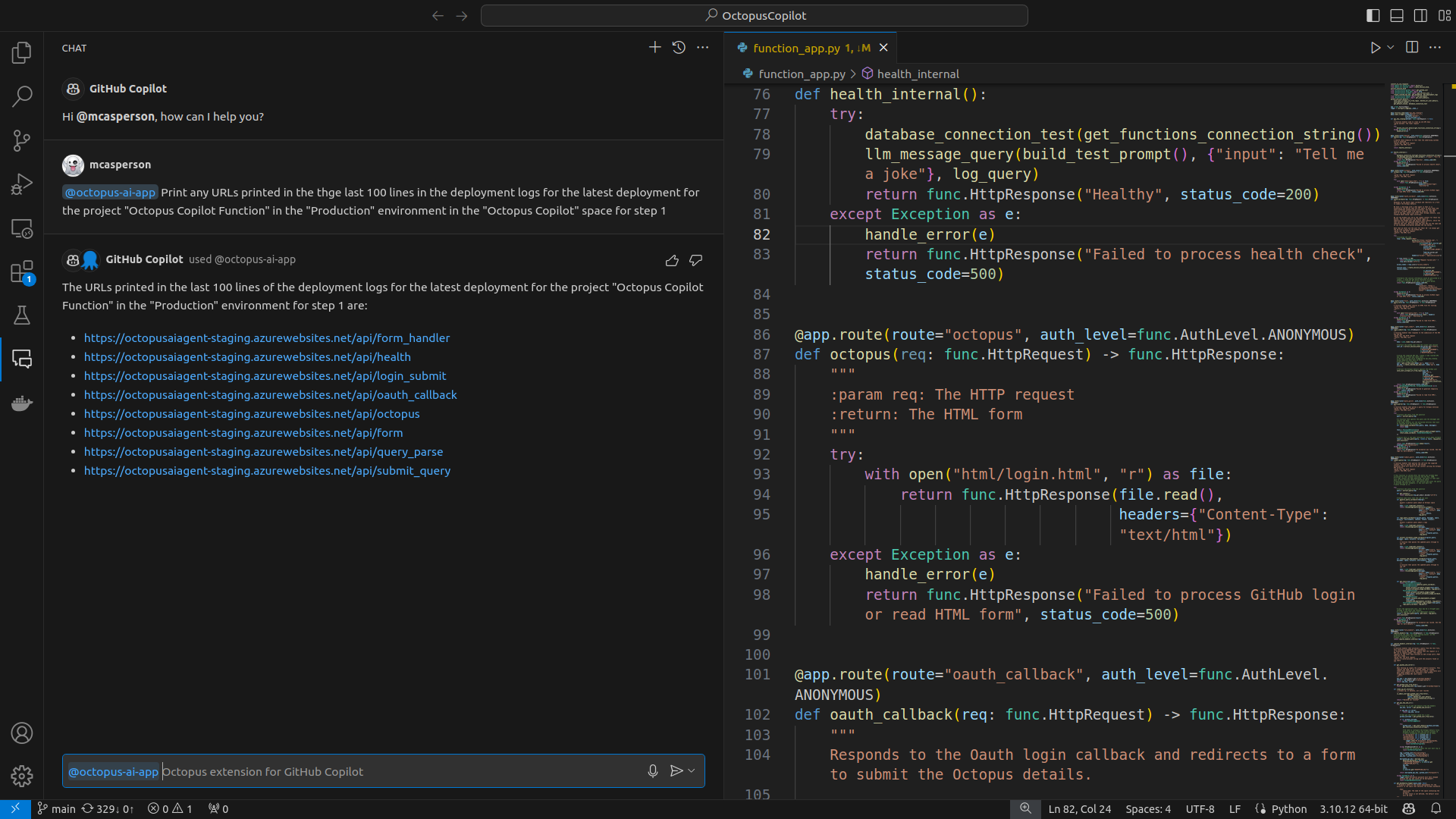
We rely on an LLM’s ability to understand what a URL is, find URLs in the deployment logs, and present the result in a helpful format. Again, there’s no special logic in the extension for extracting URLs. This ability is inherited from the underlying LLM.
The extension’s benefit is that it brings Octopus to the tools you already use. It keeps you in the flow by removing the need to jump between windows and tools. It also lets you use LLMs’ ability to comprehend plain text requests to generate custom reports or extract useful information.
Real-time AI
A challenge with AI systems is that they don’t inherently have access to real-time information. LLMs are essentially frozen in time and only know the state of the world at the point when they were trained. For example, GPT 3.5 was trained in 2021 and knows nothing about the world after that date.
Retrieval Augmented Generation (RAG) is a process that can overcome this limitation. It combines custom knowledge with a user’s prompt to generate more accurate answers or to answer questions about custom data.
For example, you may combine the contents of a recent news article with your question in the LLM prompt. The context and question get placed in the LLM’s context window, allowing it to consider content it was not trained against to provide an answer.
The challenge for an extension interacting with Octopus is that the data we want to inspect is generated in real-time. The extension must query the Octopus API for the current state of a space to ensure any prompts get answered with live information.
This challenge is two-fold: understanding what is being requested and serializing the requested information.
LLM context windows are increasing with each new LLM version, but today, you still have to be selective about the information you provide with a query. For example, the GPT 3.5 turbo model provided by Azure AI has a context window of 16K tokens. A token roughly equals 4 characters, although in practice, it appears structured data like JSON fits even fewer characters into a token. I could budget for 40K characters of context with any query without triggering token length errors. It’s impossible to naively dump the configuration of an entire Octopus space into this buffer, so only the relevant information can be included.
To understand what a query is referencing, we use the zero-shot capabilities of LLMs to extract entities from a query. For example, in the query Print any URLs printed in the last 100 lines in the deployment logs for the latest deployment of the project "Octopus Copilot Function" in the "Production" environment in the "Octopus Copilot" space for step 1, the LLM will extract the following entities:
- The project - “Octopus Copilot Function”
- The environment - “Production”
- The space - “Octopus Copilot”
- The number of lines - 100
- The steps - 1
The term “zero-shot” means we can ask the LLM to extract these entities without providing any examples or specifically training the LLM to identify the entities in the prompt.
The entities are then passed to API requests. In the example above, the latest deployment for the project to the environment in the space are found, and the logs are extracted and filtered to return only the last 100 lines for step 1.
Extracting entities and calling a function are all handled by Open AI function calling.
Log files are easy to handle with LLMs because they can be considered a stream of unstructured text, and LLMs are good at consuming such text blobs. However, questions about a space’s configuration require us to serialize and present the space’s state in a format that the LLM can reason about.
There are many formats for defining the configuration of a platform like Octopus as text, including JSON, XML, YAML, TOML, HCL, OCL (used by Octopus Config as Code), and more.
There are requirements for the selection of a format:
- It must support compound documents. This is important because we want to mix and match the resources in the context window without inventing new parent container objects. YAML uses 3 dashes to separate documents, while HCL and OCL allow resources to be added or removed from documents as needed. JSON, XML, and TOML typically require all related data to be placed in one structure.
- It must have an unambiguous method for relating resources. HCL excels here with its expression syntax, allowing one resource to reference a property of another resource, typically linking up IDs.
- It must be able to serialize all resources an Octopus space exposes. Again, HCL does a good job here as the Octopus Terraform provider already defines structures for Octopus resources. OCL is limited to describing projects and variables, making it unsuitable for this task. JSON is another option here, given all Octopus resources have a JSON representation in the API. There are no practical public examples of representing Octopus resources in XML, TOML, or YAML.
- Ideally, LLMs should have been given a chance to train on public examples of these structures. HCL is the clear winner here, with dozens of examples in the tests for the Octopus Terraform provider. The LLM has likely seen JSON representations of Octopus resources as well, although examples tend to be scattered in the wild.
Given these requirements, serializing Octopus spaces to HCL was the best choice. So, queries relating to the configuration of an Octopus space work by identifying the entities being requested, converting those entities into HCL, placing the HCL in the context, and having the LLM answer the question based on the context.
This results in a process that:
- Avoids the need for secondary storage and indexing of Octopus data because everything is queried from the Octopus API directly
- Respects the existing RBAC controls enforced by the Octopus API because all requests are made with the Octopus API key of the chat user
- Ensures prompts are answered with live data because all data is obtained as needed
- Does not require any additional capabilities to be built into the central Octopus platform
I suspect this “smart AI, dumb search” approach is something we’ll see more of in the coming years. Enterprise tools haven’t done a great job implementing search capabilities, and there’s no reason to think the situation will improve. But having an LLM identify the phrases or entities to search for, interact with an API on your behalf, and then provide an answer based on the search results means existing tools can continue to provide rudimentary search capabilities, and LLM agents can sift through broad search results. Ever-expanding LLM context windows only make implementing this approach easier (if potentially less efficient).
I’d even argue that this approach rivals solutions like vector databases. The primary purpose of a vector database is to co-locate items with similar attributes efficiently. For example, pants and socks would be co-located because they are both clothing items, while cars and bikes would be co-located because they are both vehicles. But there’s no reason an LLM can’t convert the prompt “Find me red clothes” into 5 API calls returning results for t-shirts, jeans, hoodies, sneakers, and jackets, thus relying on the capability of LLMs to generate high-quality zero-shot answers to common categorization tasks rather than having to build custom search capabilities:
Overall, this approach has worked well. It resulted in a lean architecture involving 2 Azure functions (one to receive chat requests and query the Octopus API directly, and one to serialize Octopus resources to HCL) that’s easy to manage and scale as needed without the burden of maintaining a custom data source.
Rethinking testing
Traditional automated testing is all about verifying that your code works. Test-driven development may encourage a small number of failing tests, but the expectation is that future work will focus on resolving test failures. So, failing tests are a sign of a bug or unimplemented features.
Working with LLMs requires rethinking this approach. LLMs are non-deterministic by design, which means you can’t be sure you’ll get the same result even with exactly the same inputs. This manifests most visibly when LLMs respond with different phrases to convey the same answer. However, the more serious concern for developers is that LLMs will sometimes provide incorrect results even when they previously provided correct results with the same inputs.
The non-deterministic nature of LLMs means developers must rethink the assumption underpinning automated tests that valid input and code result in valid output. Even common workarounds to intermittent events like retries assume that valid inputs and valid code will eventually produce valid output, with retries expressing the assumption that a failure must be due to some uncontrollable but detectable external factor that does not render the code being tested invalid. These failures can then be handled with the same retry logic in the application code or are assumed to be the responsibility of an external system.
Working with LLMs means assuming some of the tests always fail. This is not an intermittent external factor or a condition that can be easily detected but instead is an inherent property of the system.
Retrying tests is still good enough to work around non-deterministic LLMs for most tests. But it doesn’t quite capture the end user’s experience, which inevitably results in incorrect answers without the luxury of simply asking the question again until the correct answer is provided. (On a side note, I did experiment with Tree-of-Thought prompts, which is similar to asking the same question multiple times and picking the best response. However, I couldn’t generate reliable outputs with it.)
To capture the end user’s experience more accurately, you need to run tests multiple times to generate a useful sample set, and you base the success or failure of the test on a sufficient ratio of passing results. This is a subtle but significant shift in mindset that embraces the reality that LLMs bring uncertainty to any interaction, and it is our role as developers to be confident about what we mean by “uncertain.”
I used the term “experiment” to refer to code that validates application logic based on a passing threshold measured by several runs. This term is distinct from a “test” that passes if one run produces the correct result.
I couldn’t find an out-of-the-box solution for this kind of experimentation, but the tenacity library was flexible enough to provide this capability. Tenacity allows a custom function to be called with each retry. These hooks let you count the success or failure of each test and force a fixed number of tests to run rather than exiting on the first successful result. This is an example of such a function that can be passed to the tenacity library.
This new style of testing means developers can be assured that their example prompts reach a minimum threshold. It also embraces the reality that the threshold must be less than 100% and that retrying until success does not represent the end-user experience.
Dealing with hallucinations
LLMs are eager to please. They’ll almost always have an answer, but sometimes they could be better quality. When LLMs confidently provide incorrect or dubious answers, they’re said to be hallucinating.
Hallucinations manifested as weird and unexpected arguments passed to variables from the Open AI function calling feature. Most of the time, things work as expected, but you must always assume that some function invocations will have unexpected or inaccurate arguments passed on. These hallucinations will bite you at every point in your code.
Python has 2 styles of development:
- Easier to Ask for Forgiveness than Permission (EAFP)
- Look Before You Leap (LBYL)
EAFP is nice for developers as you can focus on the happy path and offer catch-all error handling. However, I had to lean more towards LBYL, where inputs get validated and errors get addressed as early as possible, simply because LLMs were essentially performing a kind of fuzz testing, where you couldn’t expect sensible values to be passed to your functions.
The functions in this file give you an idea of the kind of weird arguments the LLM provided. It offered catch-all regexes like .*, words like Any, All, or None, or “helpful” placeholders like My Project. None of these strings exists in the context of the prompt, meaning the LLM hallucinated them and passed them to the function.
Providing safety
A significant requirement for Copilot extensions is to provide a safe environment for your users. Everyone has heard stories about LLMs providing biased, insulting, silly, or dangerous answers to questions.
This is generally an unsolved problem with LLMs. The New Scientist article, Why curbing chatbots’ worst exploits is a game of whack-a-mole, highlights some of the limitations:
But these firms aren’t claiming that any model is perfectly safe, because they can’t. In just the past month, we have been told about three major new ways to jailbreak some of the largest chatbot models, including GPT-4 and Claude 3.
The constant back and forth between finding new ways to manipulate the models and fixes for them is a bit like a game of whack-a-mole.
That said, our extension still needed to pass testing to ensure it wasn’t generating content it obviously shouldn’t. As part of the testing to be accepted for the Copilot limited beta, the GitHub team prompted our extension with queries that resembled the titles of the least reputable online forums.
The good news is that building an extension that uses the Open AI function calling feature meant our extension only responded to a small number of queries related explicitly to the Octopus platform. When prompted to generate text for unrelated topics, none of our functions matched, and we displayed a generic apology. Combined with the built-in filters provided by the Azure AI platform, this strategy allowed us to pass the safety testing. This strategy proved to be an effective way to prevent extensions from being used to generate undesirable content.
Practical guidelines
AI is one of those topics on which everyone has an opinion. Like LLMs themselves, many of these opinions aren’t rooted in experience or reputable sources. Plus, much of the advice you can find online appears to have been written by LLMs in that they repeat ideas without adding much context.
I found the paper Principled Instructions Are All You Need for Questioning LLaMA-1/2, GPT-3.5/4 useful. It offers 26 principles for improving the quality of your prompts with evidence of their impact. Some are counterintuitive, like offering an LLM money to find a better solution. I found other principles, like instructing an LLM that it will be penalized instead of telling it what not to do, providing few-shot examples, and using chain-of-thought prompts, to be very helpful.
The Open AI best practices page also has several valuable tips. They’re high-level guidelines, but they’re practical and easy to implement.
Extending for interactivity
The initial release of our extension provides read-only access to an Octopus instance. The tight deadlines to be part of the initial beta meant we had to focus on a subset of the functionality users would eventually want. It would be nice to allow releases to be created and deployments to be executed from the extension though.
GitHub Copilot recently allowed extensions to confirm actions, which removes the most significant hurdle in performing operations that alter a target system. By presenting the details of the action to be taken and letting the user confirm it, the extension can address any misunderstandings before they lead to permanent changes.
We’re currently exploring what the next version of the extension will offer, and implementing the ability to perform tasks like deploying releases or running runbooks is something we’ll consider.
Conclusion
I’m excited about the future of chat-based interfaces. Previously, each chatbot forced you to learn an arcane syntax that limited its usefulness. The ability to interact with complex systems through natural language now means DevOps teams can treat their IDE as a single portal to their broader ecosystem. There’s still a lot of work to do to ensure the reliability of LLM-based extensions and better understand the kinds of questions and actions that DevOps teams want their extensions to perform. However, natural language chat extensions let you quickly iterate and adapt to new requirements in a way that’s almost impossible with traditional web or mobile interfaces.
You can learn more in our press release and find the source code for our Copilot extension on GitHub.
Happy deployments!





