In my previous life, I used CruiseControl.NET, and later TeamCity, as my deployment automation tool. The goal was to automate deployments, and since my build server was already compiling the code and running tests, it felt natural to make it deploy too.
I extended the build process by adding custom scripts that would deploy the software. Sometimes they’d be short scripts running RoboCopy and some XML transforms. Other times they’d be reams and reams of PowerShell with agents listening on remote machines; it all depended on how complicated the actual deployment process was. It was these experiences that led to Octopus being built.
That said, it’s a question that still comes up once a week: why should I use Octopus when I already have a CI server?
In fact, I asked it myself when writing some documentation on integrating Atlassian Bamboo with Octopus Deploy. Bamboo even has deployment concepts baked in; why would a Bamboo user need Octopus?
Here’s why:
Different focus
Build servers usually contain a number of built-in tasks with a focus on build. TeamCity and Bamboo come with a bunch of build runner types that are handy for building: they can call the build engines of many platforms (such as MSBuild), can deal with build-time dependencies (NuGet, Maven), have many unit test runners (NUnit, MSTest), and can run and report on code quality and consistency (code coverage, FXCop).
When you look at the task runner list in your build server from the perspective of deployments, you’ll notice a difference. Where’s the built in task to configure an IIS website? Or install a Windows service? Change a configuration file? Or the other 54 (as of today) deployment-oriented tasks that are available in the Octopus library?
Even in Bamboo, which has a whole deployment feature built-in, the deployment tasks available are pretty much limited to running scripts:
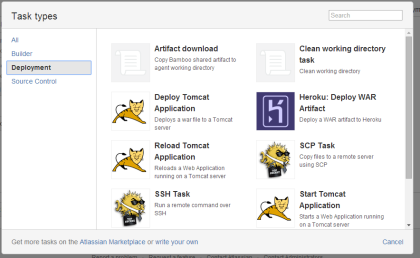
The reality is, when deploying from a CI server, the closest thing to built-in deployment tasks you’ll usually find is the ability to run a script. Which leads to the next issue:
Remote deployments
When a build server executes a job, the build agent isn’t usually the same as the machines that are ultimately being deployed to. This is because unlike builds, deployments involve coordinating activities across many machines.
When a deployment touches multiple machines, it’s up to you to figure out how to perform the entire deployment remotely, using tools like XCOPY, SSH or PowerShell remoting over the network. You can then wrap this in a for-loop to iterate over all the machines involved.
This brings up a number of challenges:
- Do you have the right permissions on all of those machines? 2) Can you make all the necessary firewall changes? 3) What if the machines aren’t on the same Active Directory domain? 4) How will you get the logs back? If something goes wrong, how will you diagnose it? 5) Is the connection secure?
I lost so much time solving these problems on different projects in the past, and it’s precisely why we invested so much time in designing the Tentacle agent system:
- Tentacles don’t need to be on the same AD domain
- We use SSL and two-way trust for security
- Tentacles can either listen or poll - it’s up to you
- When Tentacles run a command, they do so as a local user, so you can perform a number of activities that might not be possible via the network
Automatic parallelization
Related to the above, in all but the simplest deployments, there are usually multiple machines involved in a deployment: perhaps a couple of web servers, or a fleet of application servers.
A good deployment automation tool solves the problem of running all of the deployment activities in parallel across all of those machines. In Octopus, you register machines and tag them with a role, then you specify packages to be deployed to machines in a given role. Octopus ensures the packages are on the machine, then deploys them, either in parallel or rolling.
The distinction is obvious when you compare the flat build log that comes from a CI tool like Bamboo or Jenkins:
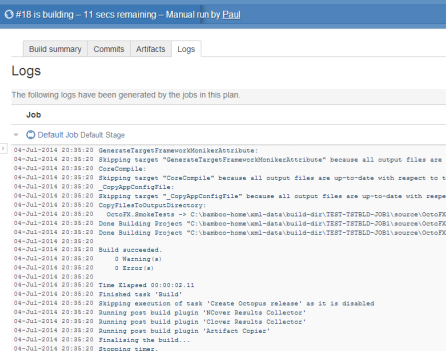
Against the hierarchical deployment log that comes out of Octopus:
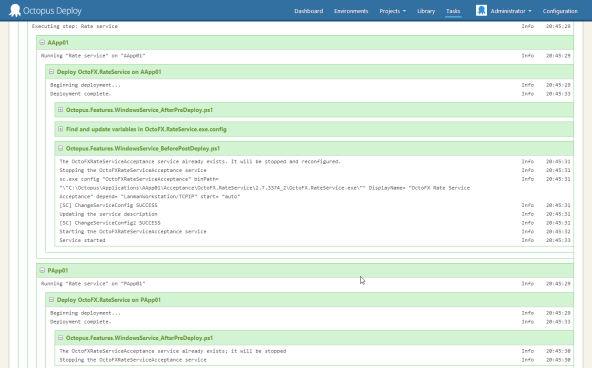
Octopus isn’t using the nesting for display purposes (like TeamCity): we use it because each of those steps are running at the same time. There simply is no other way to display it. If you have a script that needs to run on 10 machines, you’ll see the log messages as it executes on all 10 simultaneously, without them being jumbled together.
A customer last Friday used Octopus to deploy an application to over six hundred machines. It would have taken a long time to do this with a build server without writing all the coordinating scripts themselves, and the logs would have been impossible to decipher.
Configuration
All build servers have some level of build parameter/variable support. But the ability to scope them is very limited. If you have multiple target servers, and need to use different values for a setting for each one, how do you manage this?
In Octopus, we manage variables with different scopes, and can handle passwords and other sensitive settings securely. And as you would expect, we take snapshots between releases, and audit the changes made. Best of all, you can change configuration (which is really an operational concern) without having to rebuild the application.
Deployment can be messy
When your build server encounters an error - a failed unit test, or bad code, what does it do? Ideally, it fails fast. You wouldn’t want the CI server to pause, and ask what you want to do next.
When you’re performing a rolling deployment of a web site across 10 web servers, and server #7 fails, fail fast is probably the last thing you want. Perhaps you’d like to investigate the problem and retry, or skip that machine and continue with the rest. That’s why Octopus has guided failures.
In fact, a human intervening might be something that you require for all deployments, not just when something goes wrong. In Octopus, you can add manual intervention steps to a deployment, which can run at the start (for approval), at the end (for verification), or even half-way through (some legacy component that just has to be configured manually).
Summary
All of these issues - the built-in tasks available, remote execution and infrastructure problems, parallelism, and failure modes - point to a conclusion: build and deployment are fundamentally different beasts. In fact, the only characteristics that they really share is that they both sometimes involve scripting, and the team needs visibility into them.
As developers tasked with automating a deployment, this distinction isn’t obvious at first. Build and CI servers have been around a long time, and we’re familiar with them, so it’s natural to imagine how they can be extended to deployment. Even though we’ve been working on Octopus for years, when designing new features for Octopus I still find myself looking at CI tools. It’s only when you are very far down the rabbit hole with custom scripts to coordinate an increasingly complicated deployment do these differences become painfully obvious.
Build and deployment are different, but equally important. The rule of “best tool for the job” should apply to both of them. Our goal is to focus on being the best deployment tool; we’ll leave the problem of building to the build servers.
Tags: