This post is a part of our Octopus 3.4 blog series. Follow it on our blog or our Twitter feed.
Octopus Deploy 3.4 has shipped! Read the blog post and download it today!
As a new feature, we wanted auto-deploy to be something we’d be confident and proud to release; something that matched the ease-of-use and intuitiveness of Octopus currently. Basically, it had to just work and leave you nodding your head with a smile. We held onto that vision, even though the waters were unclear on several occasions. This post is a look back at some of the decisions leading up to the feature we’ve established as elastic and transient environments.
We started trying to solve this problem by listing out all the functionality we wanted in a giant checklist and drawing up some mockups in Balsamiq (because, who doesn’t love Balsamiq?). There were presentation meetings at the office, with everyone brainstorming and contributing ideas and concerns. This was initially going to be a much smaller feature-set where we would include some cool elastic features to the much bigger multi-tenancy release. However as both features developed, they quickly became much more complex than we’d anticipated and any internal schedules we’d been planning started creeping out (to the point where we stopped assigning due dates altogether and just focused on the work). This was a race of self-honesty, where only we would know when we’d truly reached the finish line.
Our functionality checklists went something along these lines:
- it shall automatically deploy as new machines come online
- it shall know which release should be on a given machines
- it shall know which release is on a given machine
- it shall automatically clean up old environments
- etc.
Sounds pretty simple. Can’t be that hard, can it?
We madly started pinning checkboxes and radio-buttons on the existing environment and deployment target screens, eager to start giving users the option to opt-in to these new elastic and transient behaviors.
Some early mockups show the simple beginnings of this feature:
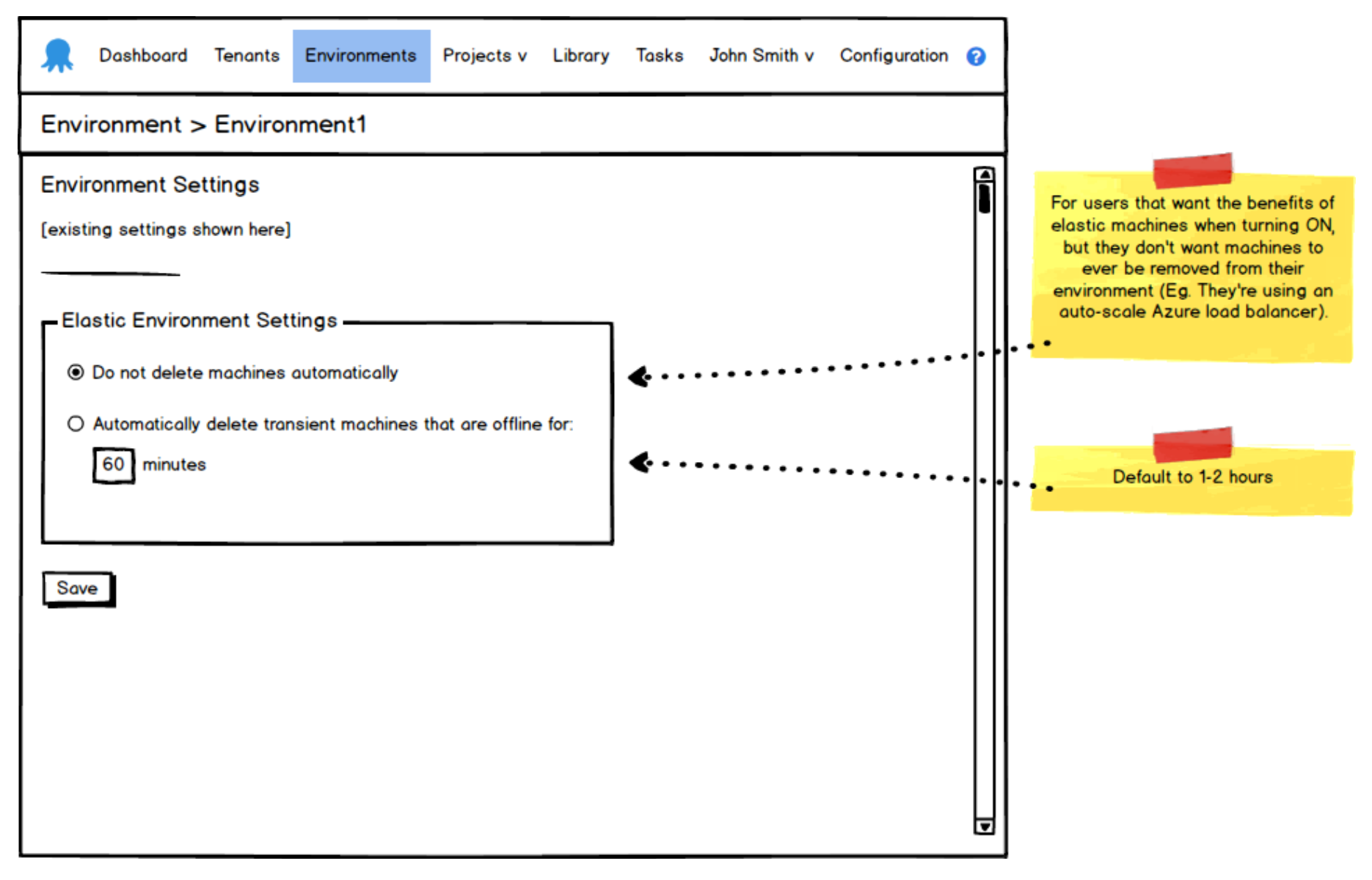
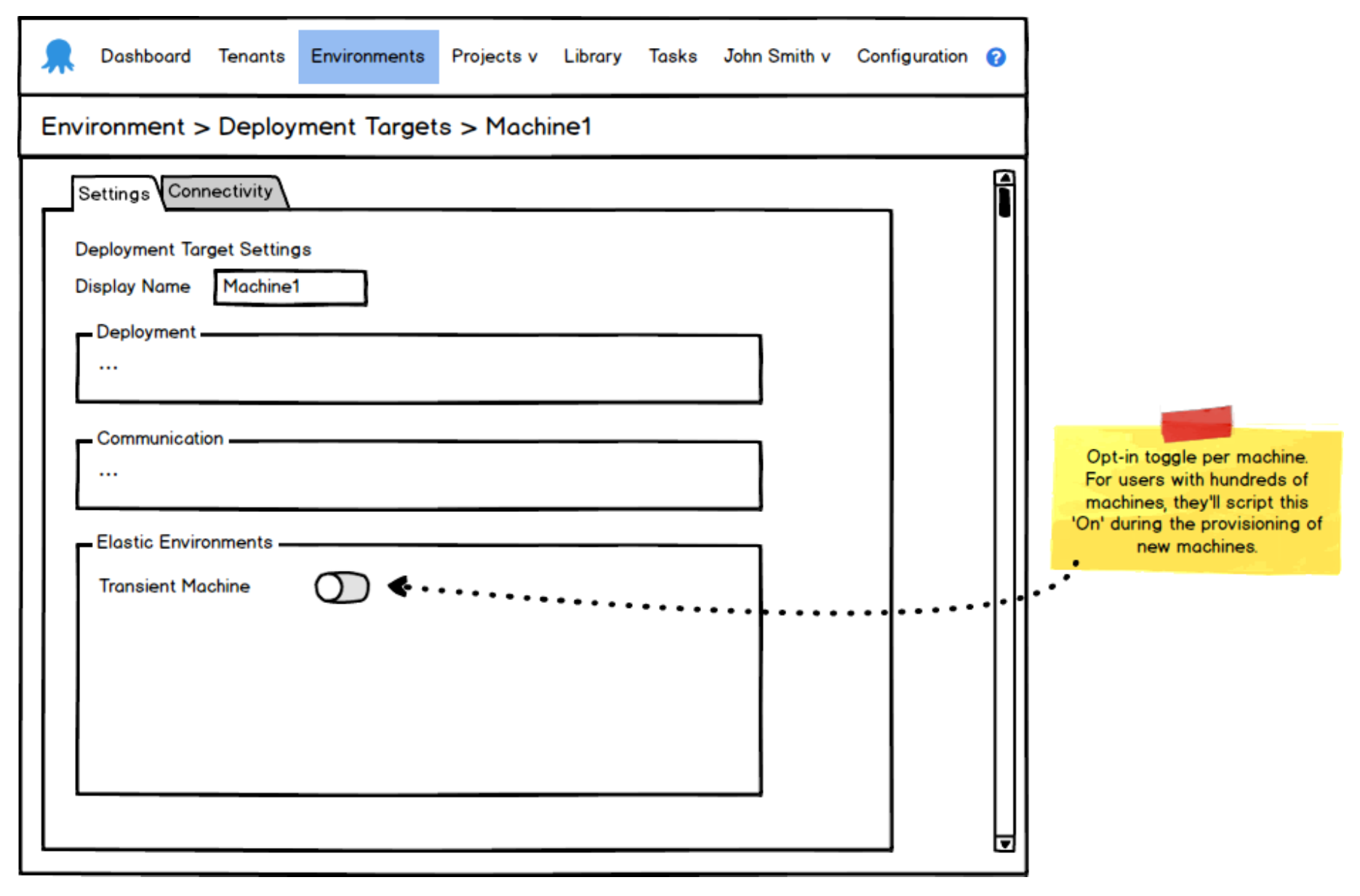
As the weeks went on, we churned out more mockups as we refined UI decisions and we developed a build to match the mockups. Then I noticed something interesting start to happen…
People finally got to play with the feature inside Octopus for real. And they weren’t happy. Neither was I. Something didn’t feel right (even though the features were developed 1:1 with the mockups that everyone thought was a good direction). To me at least, it felt like we were suddenly complicating the existing environment and deployment target screens that we loved using for their simplicity. There was also this lingering feeling that it would be hard to expand these features in the future, without just adding further bloat to these existing screens. We’d lost our way, but decided to continue developing the back-end functionality in the meantime, while giving ourselves time to arrive at an answer for our UI issues.
Enter Machine Policies
It wasn’t long before Paul came to the rescue by reminding us of an older idea that had been kicking around called machine policies. Suddenly there was this idea that you could attach a policy to a machine. It abstracted and isolated the elastic and transient logic away from the environment and deployment target screens, which also made working with the data-model much easier from a programming perspective. This was perfect for what we needed.
Some fresh mockups + some fresh hope! We were on our way.
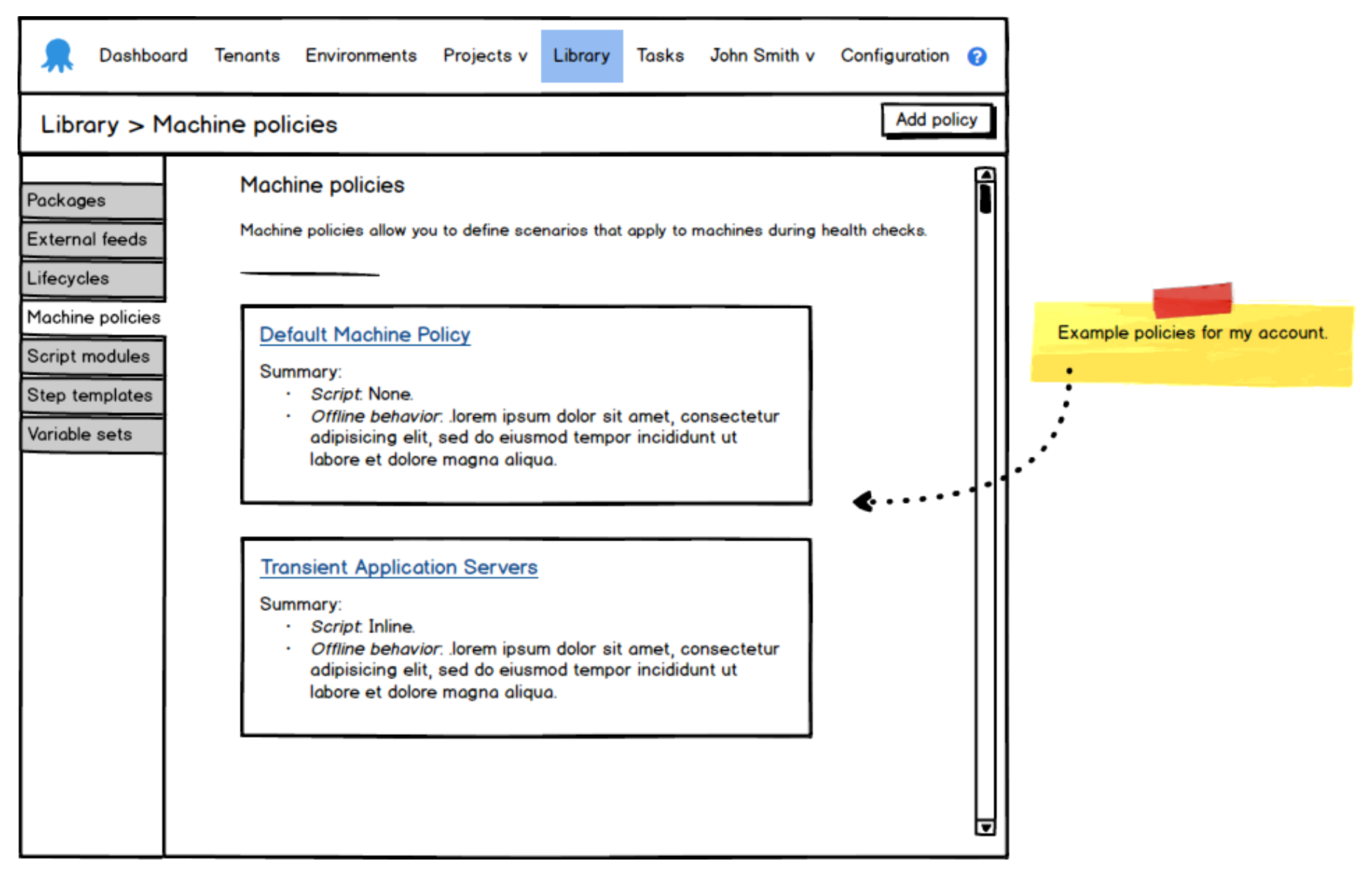

We explored this idea for several weeks and it was mostly doing what we needed. As we got closer to that finish line however, there was still this lingering feeling that something wasn’t quite right. We all knew it, we all said it in several meetings, but we couldn’t pin-point it for some time. Can you spot it by looking at those machine policy mockups?
It was the ‘Deploying missing releases’ section of the mockup. We had made the mistake of blindly accepting machine policies as a universal solution to all of our elastic environment needs. The deployment part of the machine policy was like trying to put a round peg in a square hole. And while I’m usually all for the round pegs in square holes, in this case it just wasn’t working, because deployment-related conditions belong with projects, not with machines. Paul had identified the missing piece and described the vision in a simple scribble:
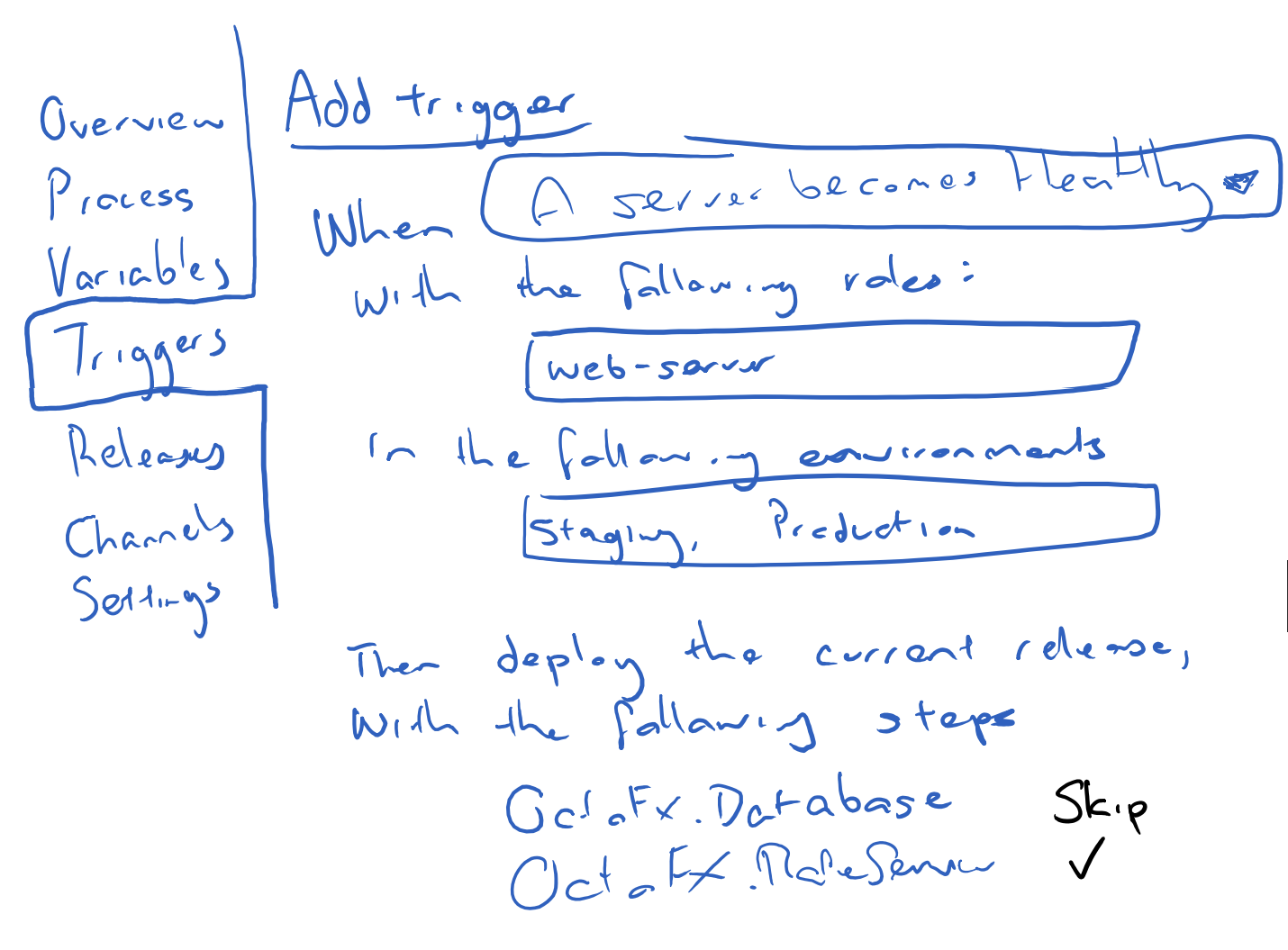
The number of smiles that this little scribble gave is hard to describe. It cleared away all the noise (that voice in the back of your head that’s been saying something’s not right) and we suddenly knew where the finish line was.
Enter Project Triggers
This is when things got exciting…
Project triggers allowed us the same flexibility and separation that machine policies had facilitated several weeks earlier and gave focus solely to auto-deployments. It also expanded the possibilities for auto-deploy. We could restrict auto-deployments to certain criteria, like roles or environments. We could have multiple triggers facilitating different purposes (one for your Development environment, one for your Staging environment etc). This was awesome!
So now we had the vision. The implementation however, was still unsure.
The ‘How’
We investigated several approaches to implementing auto-deploy. Some of these got completely thrown out after being 90% implemented (not exaggerating). It was like a final branch in the road. Only one branch leads to the actual finish line, but all of them look like they lead to the finish line from where you stand.
Personal note: This was an interesting and very new experience for me. Before Octopus, I’ve been used to working to a strict schedule and budget, so you can only choose one road (and if it doesn’t end up being great, tough, you’re now stuck with it). But Octopus encourages us to explore all possibilities so we get the best outcome for our customers, and this was one of those times.
We started by exploring a notification system we termed domain events (just like NSNotifications for those iOS junkies like me out there). The idea was that we could register for events within Octopus (such as MachineEnabled, MachineDisabled, MachineAdded etc.) and we’d listen for those events and respond with an auto-deployment when necessary.
Eg pseudocode. if (event == MachineAdded) then ForwardThisMachineToAutoDeployForProcessing()
The auto-deploy engine would run on a schedule (every 15 seconds) and would make a decision about which machines to deploy to (based on some flags we had on various tables). After a couple of concentrated days and nights, the basic concept was up and running. Unfortunately this architecture fell over in high availability (HA) setups and we needed to make a decision:
- Press forward with this domain-event architecture and patch it to work under HA, or
- Try a different approach.
The concept of event sourcing was floated as an idea to avoid the architectural problems we were encountering. We already use a table called Event in Octopus to create an audit history whenever significant events happen in the system. So extending on this Event table allowed us to explore an event-sourcing architecture very easily.
Combining all the hard work
We didn’t want to completely throw away the domain-events architecture that we’d worked so hard on (literally weeks of work and testing). We also liked the idea that the domain-events could still be useful for other areas of Octopus in the future. So we chose to re-use domain-events in a way that didn’t expose them to the problems of high-availability. We now use them to populate the events that we need for elastic and transient environments.
For example, when a machine is added, we post a domain-event for MachineAdded. The domain-event listener then populates the Event table on our behalf. This is quite nice, because it means we have a single class (the domain-event listener) that controls which events are being populated for auto-deploy.
Our auto-deployment engine is then simplified to a pure event-sourcing architecture, which makes it more isolated and easier to test (and works under HA). It runs every 15 seconds and scans the Event table to see what events have occurred since it last passed. It then analyses and balances these events in terms of positive events (machine was added, came online, was enabled) and negative events (machine was deleted, went offline, was disabled) and can then decide on what releases to auto-deploy.
Currently in Beta
With all that said, I’d like to say a personal thank you to the whole team and especially the community for reaching out and sharing their thoughts and feedback. This has been a massive effort and it all leads to what we have today, currently in 3.4.0-beta0001: Elastic and transient environments with a clear distinction between machine policies and project triggers.
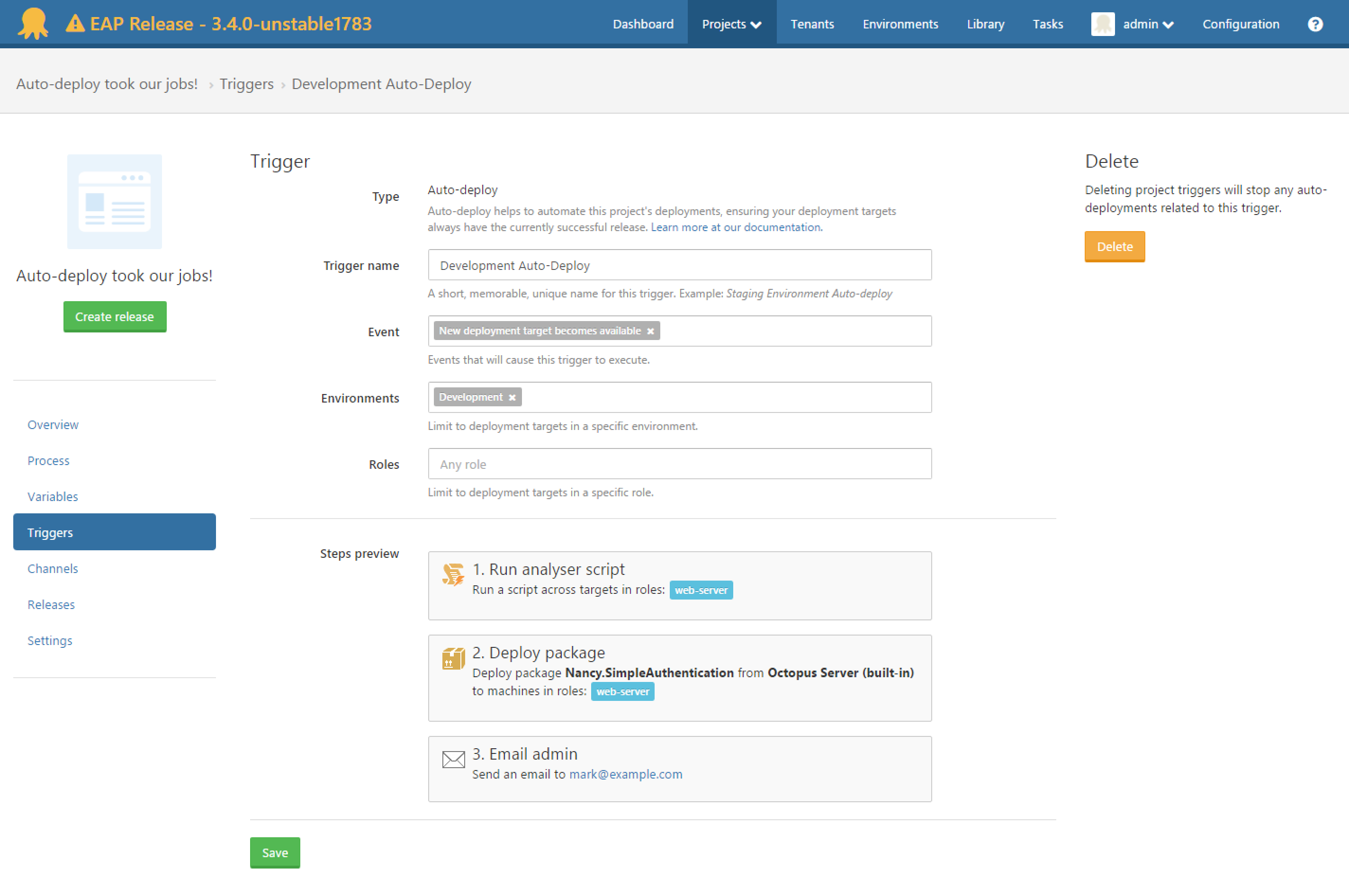
Over the coming weeks we’ll be exploring these new features with some short blog posts. We look forward to your feedback and hope this gives you some insight into how these features came to be.
Tags: