Machine policies are groups of settings that can be applied to Tentacle and SSH endpoints to modify their behavior. They can be used to:
- Customize the interval between health checks.
- Run custom health check scripts.
- Ignore machines that are unavailable during health checks.
- Configure how Calamari and Tentacles, and SSH Targets are updated.
- Recover from communication errors with Tentacle.
- Automatically delete machines.
You can access the machine policies by navigating to Infrastructure ➜ Machine policies.
Getting Started - Machine Policies
Default machine policy
By default, Octopus Deploy comes with a default configured machine policy with the following rules:
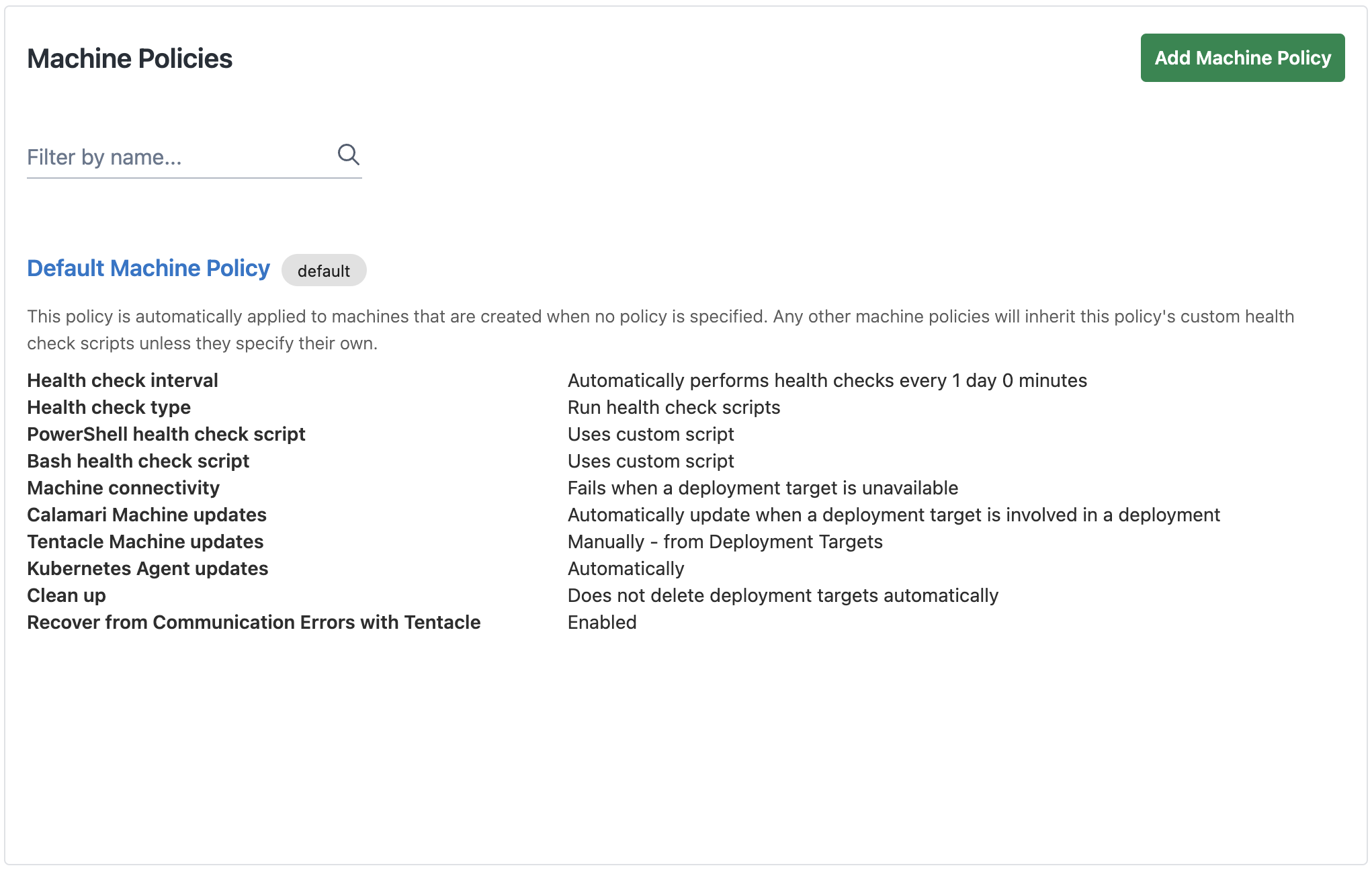
This machine policy cannot be deleted however it can be edited and any new deployment targets without an explicitly assigned machine policy will use the default one. Other machine policies will also inherit the bash/powershell scripts used for health checking from the default policy unless they have one explicitly set.
Health check
Octopus periodically runs health checks on deployment targets and workers to ensure that they are available and running the latest version of Calamari.
The health status of a deployment target can be set by custom health check scripts. Deployment targets can have four health statuses:
- Healthy
- Healthy with warnings
- Unhealthy
- Unavailable
A healthy deployment target completes a health check without any errors or warnings. A deployment target that is healthy with warnings completes a health check but encounters a non-critical failure during the health check. An unhealthy deployment target completes a health check but encounters a critical failure while running the health check script. An unavailable deployment target is not contactable by Octopus during a health check.
You can review the health status of you deployment targets by navigating to Infrastructure ➜ Deployment Targets.
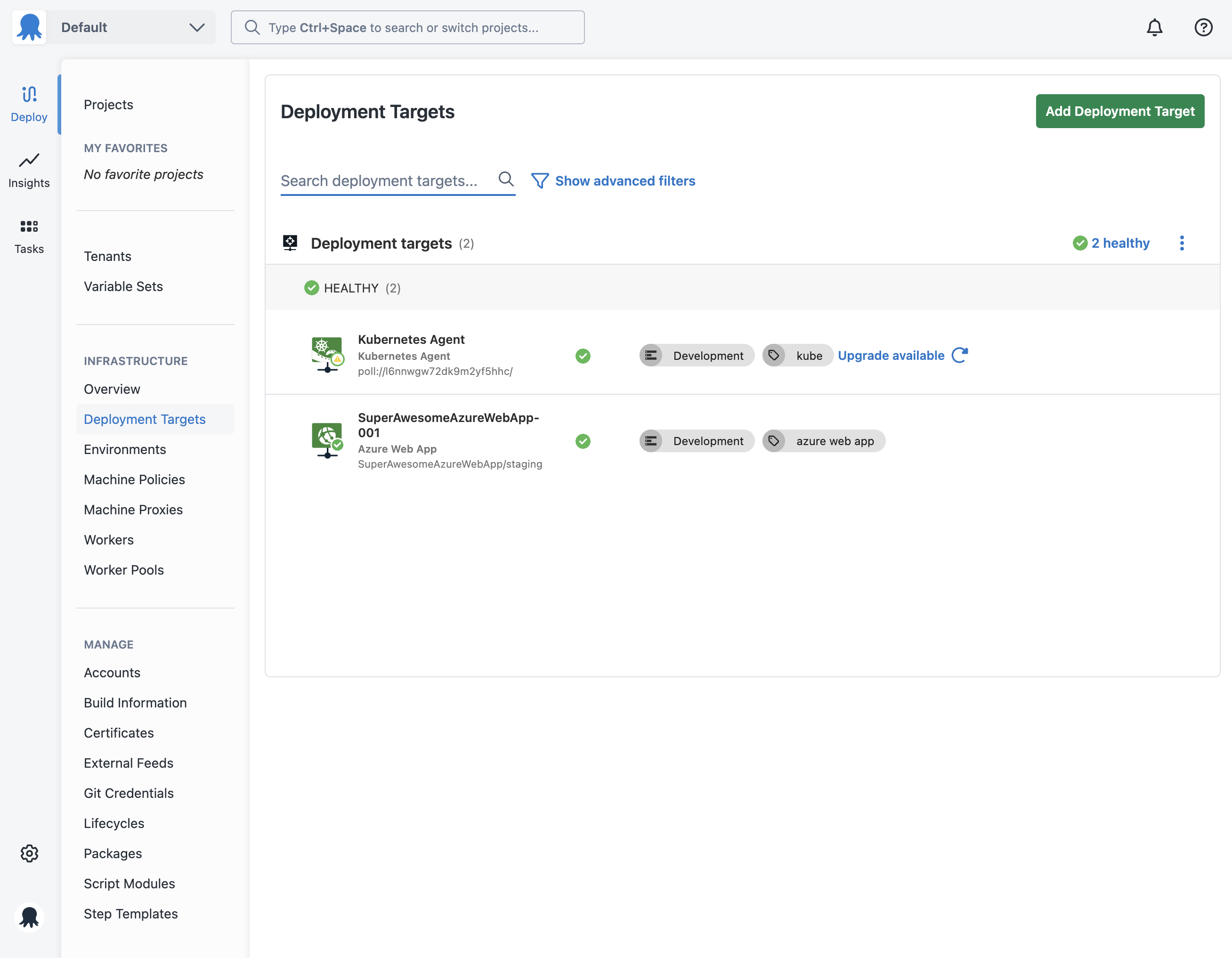
Health check step
It’s also possible to run a health check as part of a deployment or runbook using the built-in health check step.
This step allows a deployment target that was created in the currently executing deployment to be confirmed as healthy and then added to the running deployment for subsequent steps.
Similarly, it allows you to confirm that the Tentacle service on a deployment target is running prior to attempting to perform an action against it.
Initial health check
After creating a new Tentacle or SSH Target, Octopus Deploy will automatically schedule an initial health check, however if you desire you can manually start a health check by doing the following:
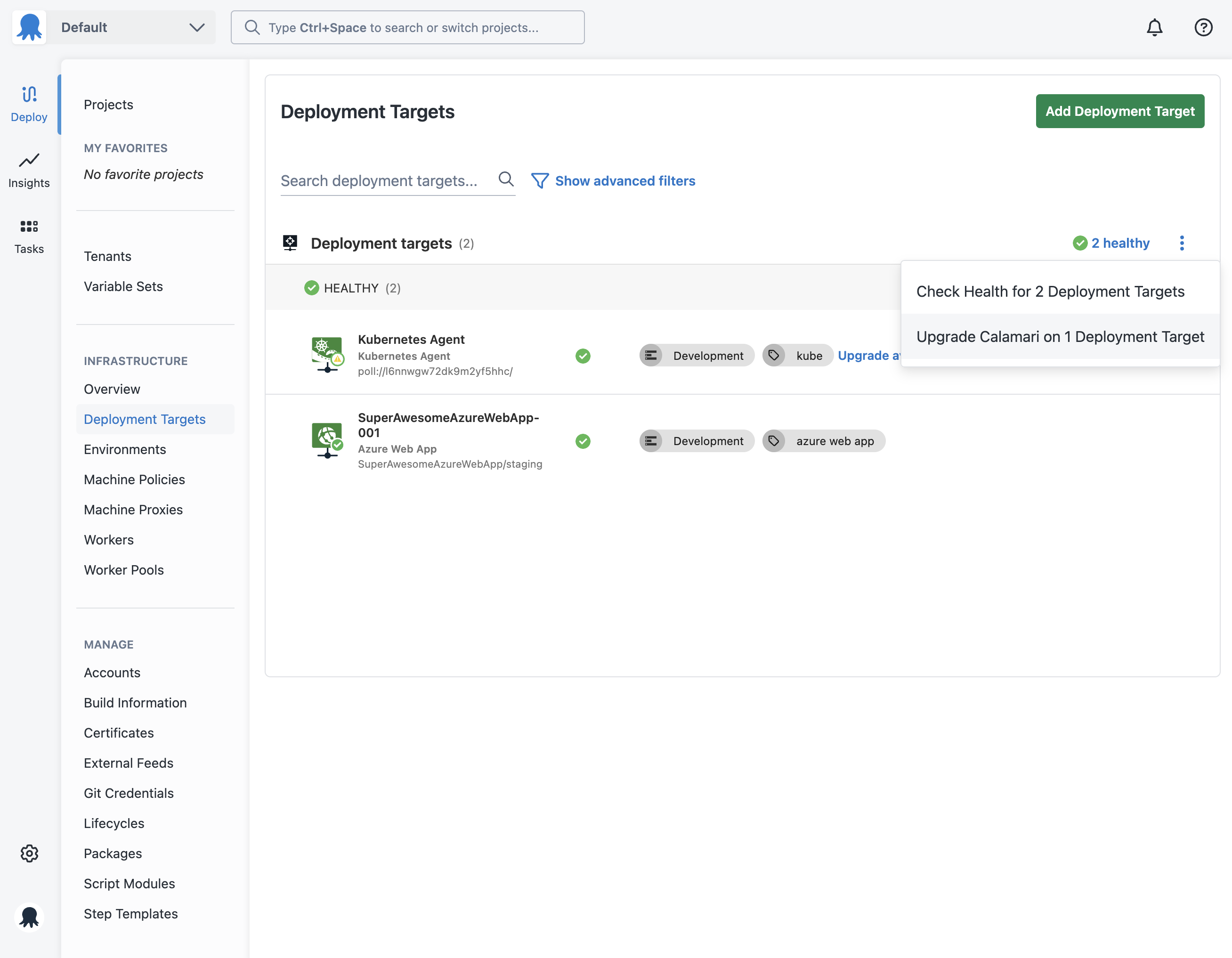
- From the Infrastructure tab, select deployment targets.
- Click the … overflow menu and select Check Health. If you have multiple deployment targets that support health checking it will start health checks for each of them.
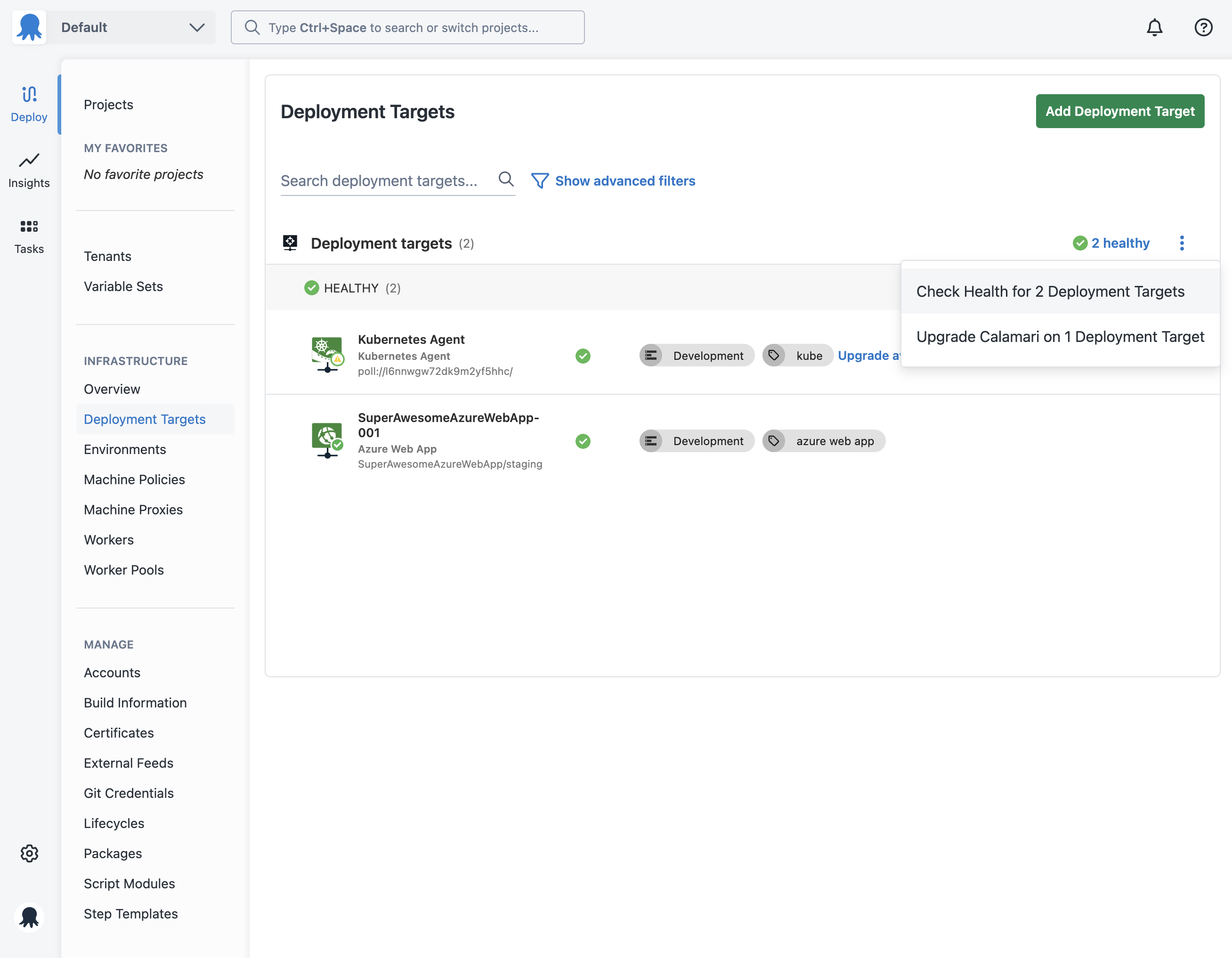
However if you would like to check the health of a single deployment target you can do the following:
- Select the deployment target you would like to health check.
- Click on the Connectivity tab then click on the Check Health button on the top right of the page.
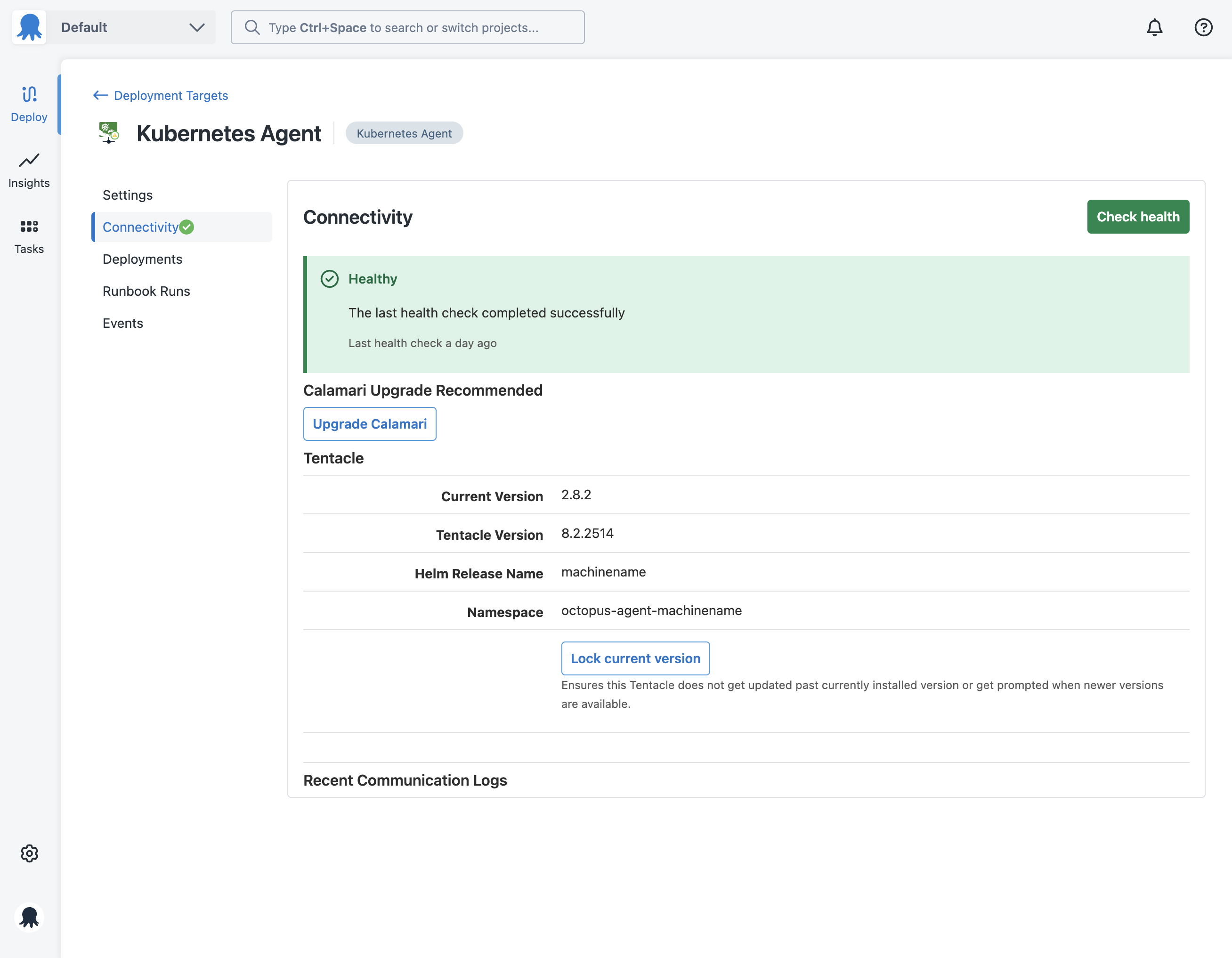
The first time you complete a health check on a Tentacle or SSH Target, you will see health warnings and that Calamari needs to be installed.
Learn more about Calamari.
Octopus will automatically push the latest version of Calamari with your first deployment, but you can do the following to install Calamari:
- From the Infrastructure tab, select deployment targets.
- Click the … overflow menu and select Upgrade Calamari on Deployment Targets.
Like with the health check if you would rather just update Calamari on a single deployment target you can achieve this by:
- Select the deployment target you would like to update Calamari on.
- Click on the Connectivity tab then click on the Update Calamari button.
Health check configuration
Health check schedule type
A health check can be scheduled in the following ways:
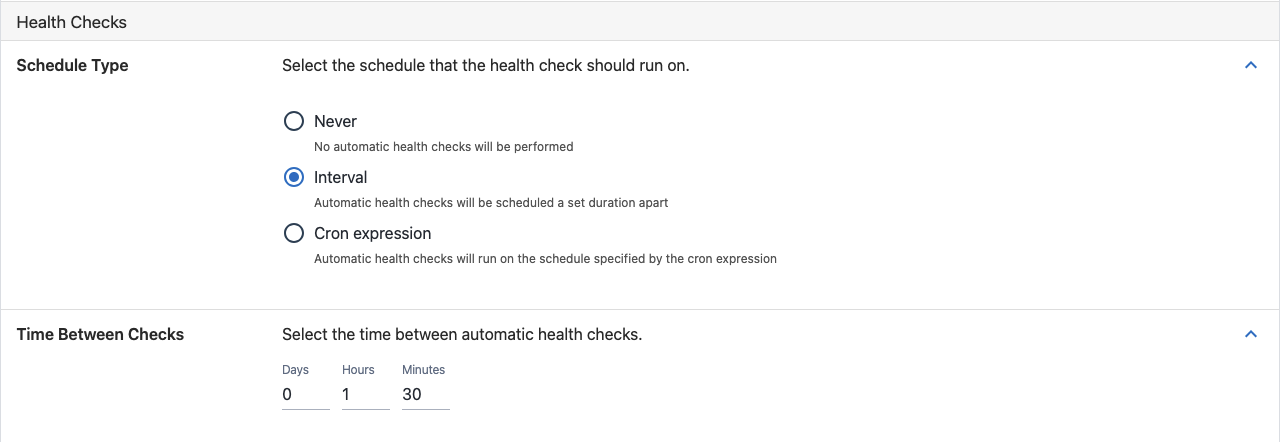
Never
No automatic health checks will be scheduled, when this option is selected. Manual health checks can still be run when desired.
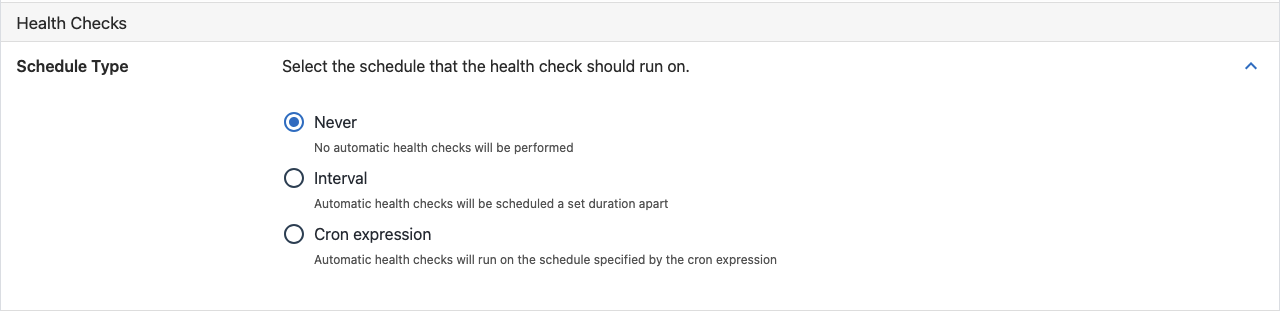
Interval
A health check will be scheduled after every X duration(X = days/hours/minutes)
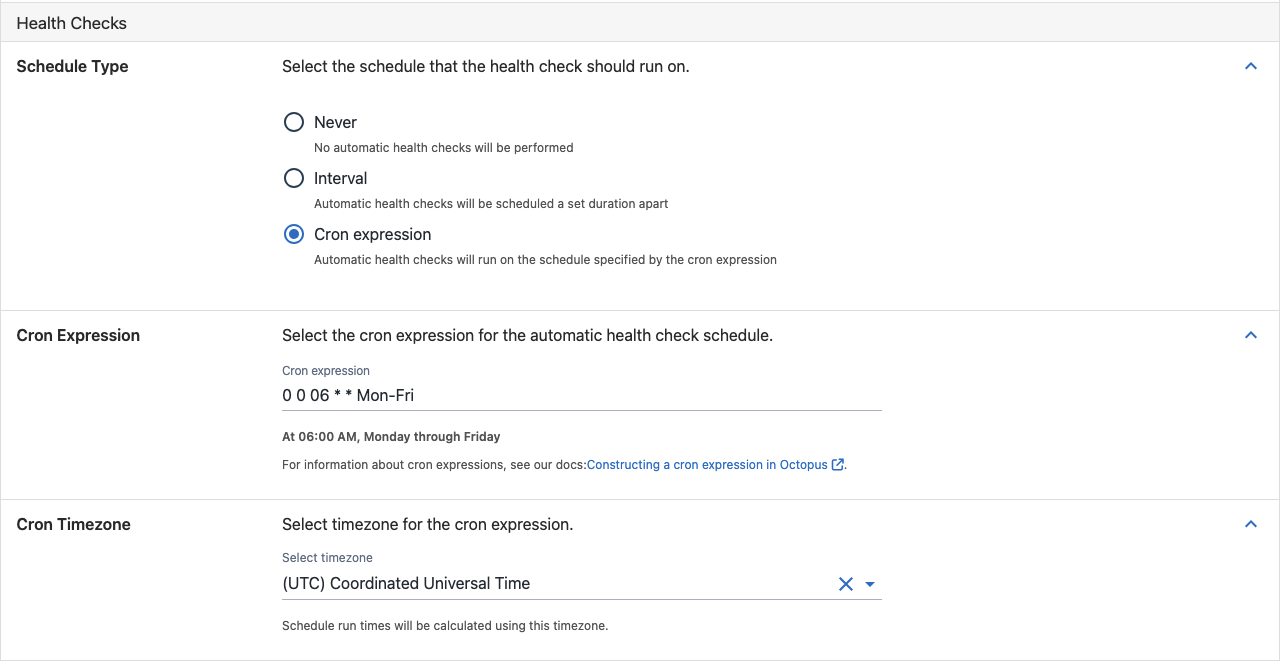
Cron expression
A health check will be scheduled in accordance to the valid cron expression. You can also choose the timezone the cron expression should adhere to.
Health check type
You can configure health checks to run scripts on Tentacle or SSH deployment targets, or just check that a connection can be established with the Tentacle or SSH deployment targets.
Run health check script
Machine policies allow the configuration of custom health check scripts for Tentacle and SSH deployment targets. While we do not expose the full underlying script that runs during health checks, we give you an entry point to inject your own custom scripts.
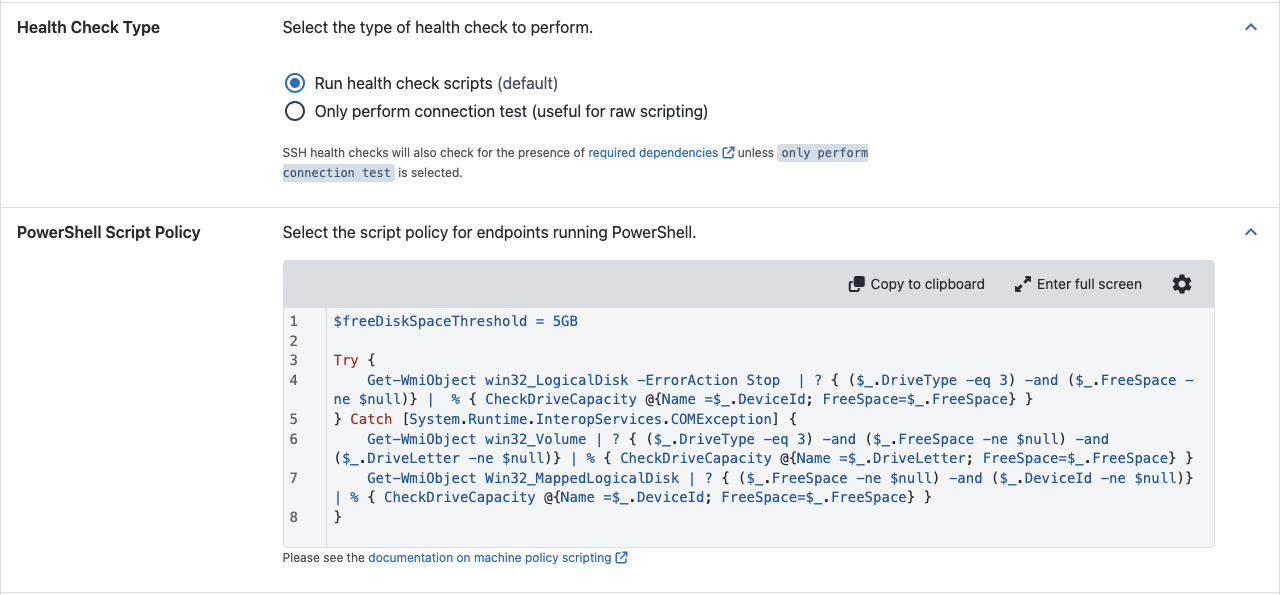
By default, machine policies will inherit the script from the default machine policy if one has not been defined. For more details on providing a custom script see the section Custom health check script
Connection test
The health check will only perform a basic connection test to see if the deployment target is reachable. This option is recommended if you are using the raw scripting feature.

Machine behavior during health checks
This setting controls what the expected behavior of machines should be during a health check.
Unavailable causes health checks to fail
If a machine is unavailable during an attempted health check it will cause the check to be failed.

Ignore machines that are unavailable during health checks
By default, health checks fail if any deployment targets are unavailable during the health check. Machine policies offer an option to ignore machines if they are unavailable during a health check:

By selecting Unavailable machines will not cause health checks to fail, any deployment targets that Octopus cannot contact during a health check will be skipped and the health check marked as successful. If the target is contactable but encounters an error or warning, the usual health check behavior will proceed (i.e., a warning will be reported or the health check will fail with an error).
Custom health check script
When the selected health check type is “Run health check scripts” you can provide script(s) that will execute during the health check.
Default PowerShell health check script
Here is the default custom health check script for PowerShell that checks disk space:
$freeDiskSpaceThreshold = 5GB
Try {
Get-WmiObject win32_LogicalDisk -ErrorAction Stop | ? { ($_.DriveType -eq 3) -and ($_.FreeSpace -ne $null)} | % { CheckDriveCapacity @{Name =$_.DeviceId; FreeSpace=$_.FreeSpace} }
} Catch [System.Runtime.InteropServices.COMException] {
Get-WmiObject win32_Volume | ? { ($_.DriveType -eq 3) -and ($_.FreeSpace -ne $null) -and ($_.DriveLetter -ne $null)} | % { CheckDriveCapacity @{Name =$_.DriveLetter; FreeSpace=$_.FreeSpace} }
Get-WmiObject Win32_MappedLogicalDisk | ? { ($_.FreeSpace -ne $null) -and ($_.DeviceId -ne $null)} | % { CheckDriveCapacity @{Name =$_.DeviceId; FreeSpace=$_.FreeSpace} }
}The function CheckDriveCapacity informs you about how much space is available on your deployment target’s local hard disk and will write a warning if the free disk space is less than this threshold. You can add additional PowerShell to this script to customize your health checks as you wish, modify or remove the disk space checking altogether. It’s entirely up to you! Just remember, you can copy and paste the original script above back into your machine policy if you run into any problems and wish to get back to the default behavior.
Set the status
A health check script can set the status of a target by returning a non-zero exit code or by writing a service message during the health check. PowerShell based deployment targets can use Write-Warning, Write-Error and Fail-HealthCheck to convey a healthy with warnings or unhealthy status:
PowerShell health check service messages
# For setting a health status of Healthy with Warnings:
Write-Warning "This is a warning"
# For setting a health status of Unhealthy:
Write-Error "This is an error"
Fail-HealthCheck "This is an error"Bash targets do not include a disk space check by default like PowerShell targets do. As such, there is no default Bash script listed in your machine policy for Bash targets by default. However, you may write your own, or choose to add additional Bash script to run against your Bash targets during health checks. Again, it’s entirely up to you. Unless you select the Only perform connection test option, there are some system prerequisites that are included as part of the standard health check.
Bash deployment targets can use echo_warning, echo_error and fail_healthcheck to convey a healthy with warnings or unhealthy status:
Bash Health Check Service Messages
# For setting a health status of Healthy with Warnings:
echo_warning "This is a warning"
# For setting a health status of Unhealthy:
echo_error "This is an error"
fail_healthcheck "This is an error"Agent-Level variables
When using a custom health check script, the script execution through Calamari is bypassed. This results in some behavioral differences compared with the normal scripting in Octopus that you would be accustomed to. You can still use the standard # variable substitution syntax, however since this is replaced on the server, environment variables from your target will not be available through Octopus variables.
Configure how Calamari, Tentacle and Kubernetes agents are updated
Brand new Tentacle, Kubernetes agent and SSH endpoints require the installation of Calamari to perform a deployment. Also, if Calamari is updated, the Octopus Server will push the update to Tentacle, Kubernetes agent and SSH endpoints. When there is a Tentacle or Kubernetes agent update, Octopus can automatically update Tentacle and Kubernetes agent endpoints. Machine policies allow the customization of when Calamari, Tentacle and Kubernetes agent updates occur.
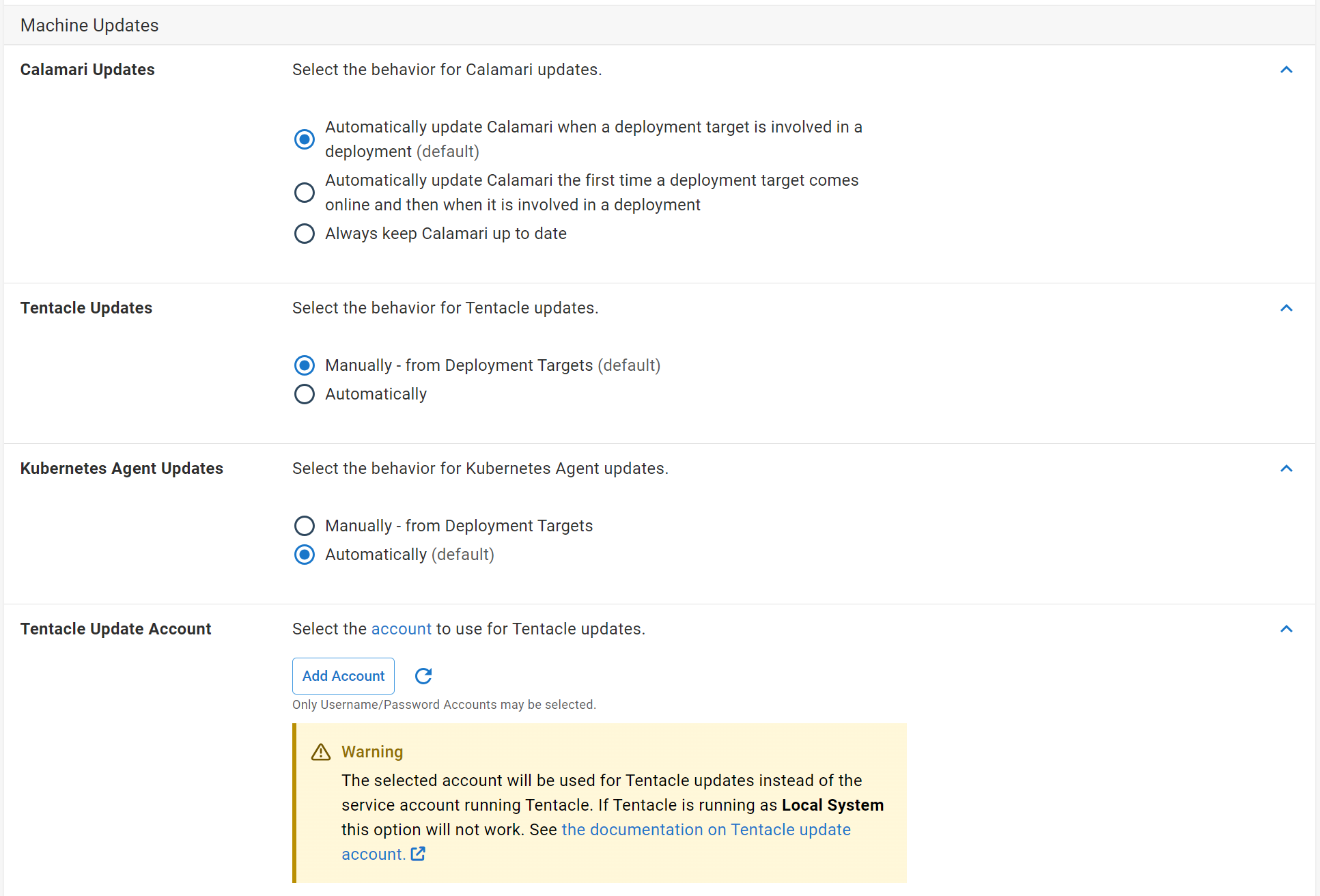
By default, Calamari will be installed or updated when a machine is involved in a deployment. The other two options will update Calamari:
- the first time a machine is added to Octopus and then subsequently when it is involved in a deployment.
- any time Octopus detects Calamari is out of date (after health checks for example).
Tentacle and Kubernetes agents can be toggled to manually or automatically update. If Automatically is selected, Octopus will start a task to update Tentacles and Kubernetes agents whenever Octopus detects that there is a pending Tentacle or Kubernetes agents upgrade (after health checks for example).
Conversely, Octopus will not automatically update Tentacle or Kubernetes agents but instead will display a prompt to begin a Tentacle and Kubernetes agents update on the Deployment Targets and Environments screens.
Kubernetes also has a 3rd option: Block which disables both automatic and manual updates to keep the Agent on a static version.
Maximum number of concurrent upgrades
There is a limit to the number of concurrent upgrades possible when choosing Always keep Calamari up to date. This ensures that upgrades do not adversely effect the performance of your Octopus Server.
The number of concurrent upgrades will be double the Octopus Server’s logical processor count which is a minimum of 2 and will not exceed 32.
Tentacle update account
You can select a username/password account to perform automatic Tentacle updates. When no account is selected, the account that the Tentacle service is running as will attempt to perform Tentacle updates. If this account is not an Administrator it will not have enough permission to perform Tentacle updates. In that scenario you will need to create a username/password account for a user with administrative rights to install software on your machines and select it from the drop down.
Note: This option can not be used when Tentacle is running as Local System.
Recover from communication errors with Tentacle
Recovering from communication errors with Tentacle is available from Octopus 2023.4 onwards.
You can configure whether Octopus Deploy should re-attempt failed communications with a Tentacle for a set duration when a network error occurs. This is particularly useful to reduce deployment failures that occur when Tentacle is on an unstable network connection.
-
With this setting Disabled, if a network error occurs while Octopus Deploy is communicating with a Tentacle, the deployment, runbook run, or health check will fail.
-
With this setting Enabled, if a network error occurs, Octopus will re-attempt communication with the Tentacle for the amount of time configured. However, continued network errors will cause a failure.
Using this setting with a Tentacle that runs on ephemeral storage will introduce the possibility that a script could run twice. For example, when running Tentacle in Docker without a mount. It is recommended to run Tentacle on a persistent file system.
Retry durations
You can configure the amount of time allowed for Octopus to re-attempt failed communication with Tentacle. There are two duration configurations available:
- Deployment or Runbook Run
- Health Check

Step Retries and execution timeouts
If you would like to retry a particular step within the deployment process for other types of temporary or transient errors, that can be configured separately.
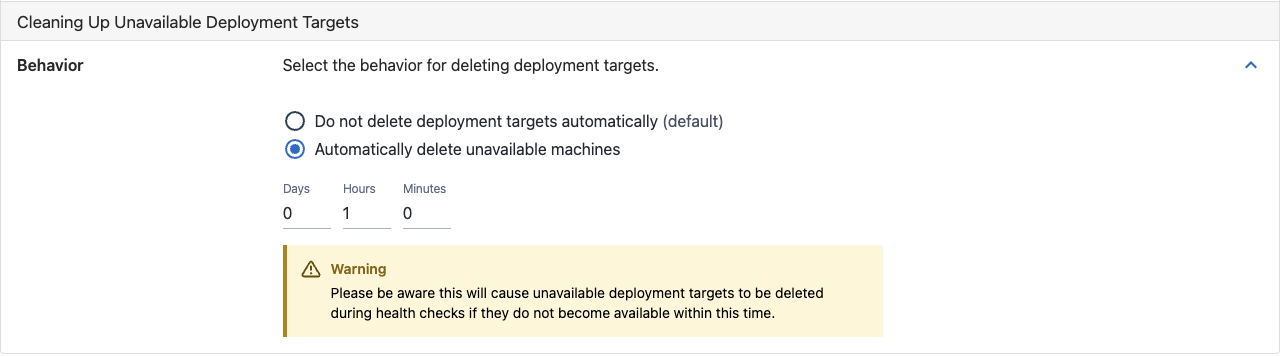
Automatically delete machines
Machine policies can be configured to automatically remove unavailable machines after a time period. When a health check runs, Octopus detects if machines are unavailable (cannot be contacted). When the Automatically delete unavailable machines option is set, Octopus checks how long a machine has been unavailable. If the specified time period has elapsed, the machine is permanently deleted from Octopus.
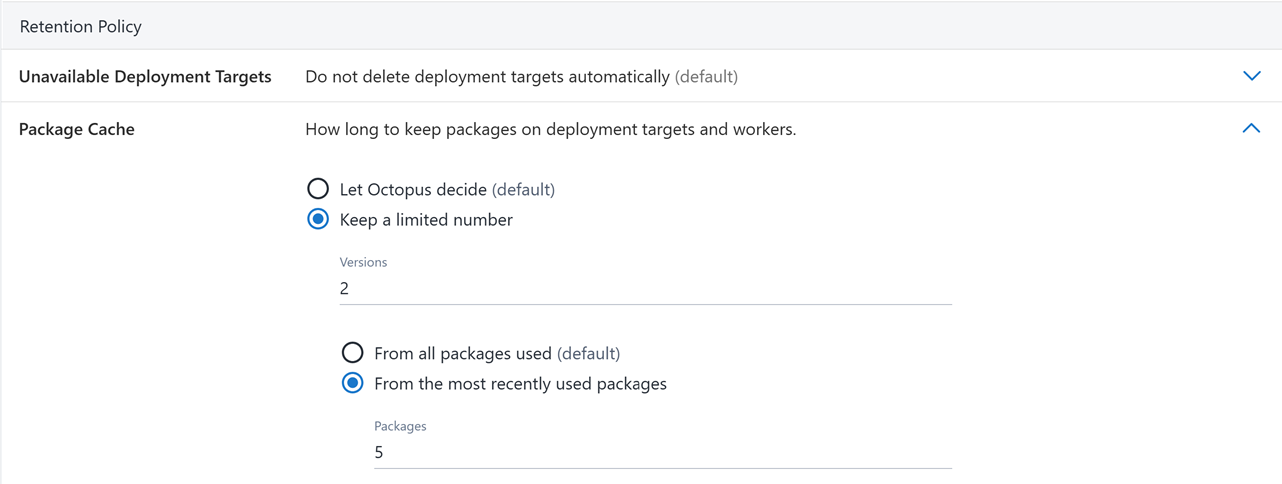
Package cache retention policy
Configurable machine package cache retention was introduced in Octopus 2025.3. This feature will roll out to Octopus Cloud customers first, and will be available to Octopus Server customers in Q4 2025.
The machine package cache retention policy ensures that packages are periodically removed from the machine cache. This is handled by Octopus by default, but can be configured per machine policy as required.
Machine connectivity configuration
Connection timeout and retries
For Tentacles, Retry Durations should be used instead.
Machine policies define rules for how long to wait for a connection to be established to a Tentacle or SSH target as well as how it should retry the connection if the initial attempts do not succeed.
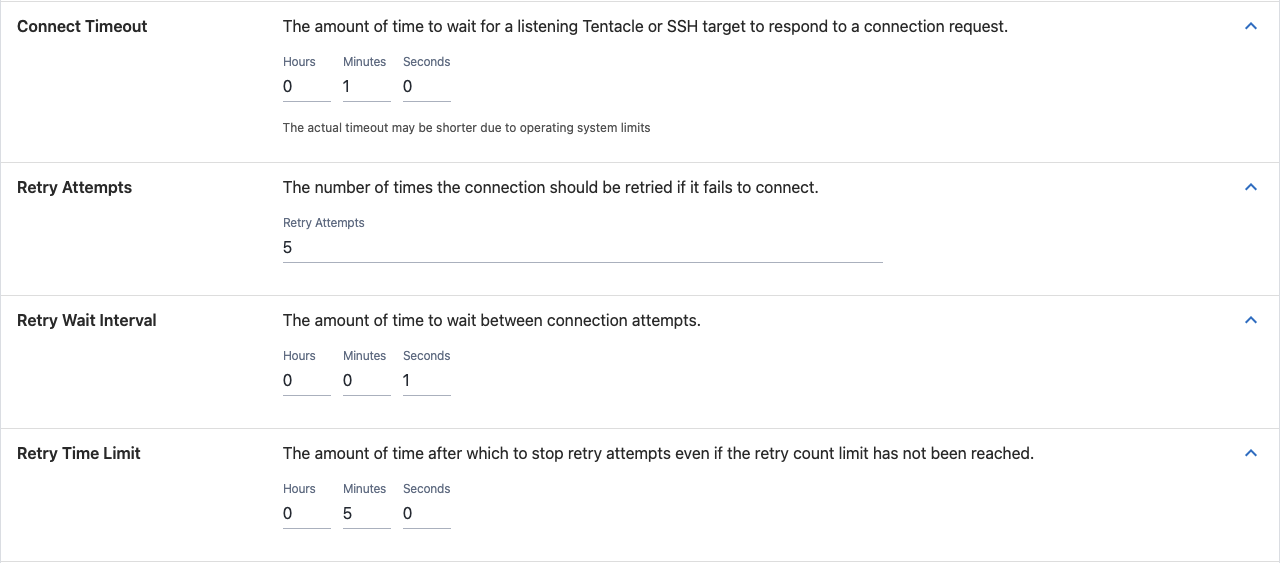
Connect timeout
How long in hours/minutes/seconds to wait for a Listening Tentacle or SSH target respond to a connection before timing out. Depending on what operating system the machine is running could potentially mean the timeout is shorter than expected.
Retry attempts
How many times the connection to the Listening Tentacle or SSH target should be retried before failing the health check.
Retry wait interval
How long to wait between connection retries.
Retry time limit
Maximum time limit for how long retries can be attempted for. For example, if you have the following configuration:
- Retry time limit: 1 minute.
- Retry attempts: 4.
- Retry interval: 30 seconds.
In this scenario only a maximum of 2 retries could be attempted before reaching the time limit.
Polling request queue timeout
This setting controls how long Octopus Deploy will wait before cancelling a task in a polling Tentacle’s queue. For more details on what the Polling Tentacle queue is see the documentation on Tentacle communication modes

Assign machine policies to machines
Assign a machine policy to a machine by selecting a machine from the Deployment Targets or Workers screen and using the Policy drop down to select the machine policy:
Machine policy can also be set from the command line by using the —policy argument:
Setting machine policy
Tentacle.exe register-with --instance "Tentacle" --server "http://YOUR_OCTOPUS" --apiKey="API-YOUR_API_KEY" --role "web-server" --environment "Staging" --comms-style TentaclePassive --policy "Transient machines"Help us continuously improve
Please let us know if you have any feedback about this page.
Page updated on Thursday, October 23, 2025