Octopus Deploy supports two hosting options:
- Windows Server
- Linux Container
There are three components to an Octopus Deploy instance:
- Octopus Server nodes These run the Octopus Server service. They serve user traffic and orchestrate deployments.
- SQL Server Database Most data used by the Octopus Server nodes is stored in this database.
- Files or BLOB Storage Some larger files - like packages, artifacts, and deployment task logs - aren’t suitable to be stored in the database and are stored on the file system instead. This can be a local folder, a network file share, or a cloud provider’s storage.
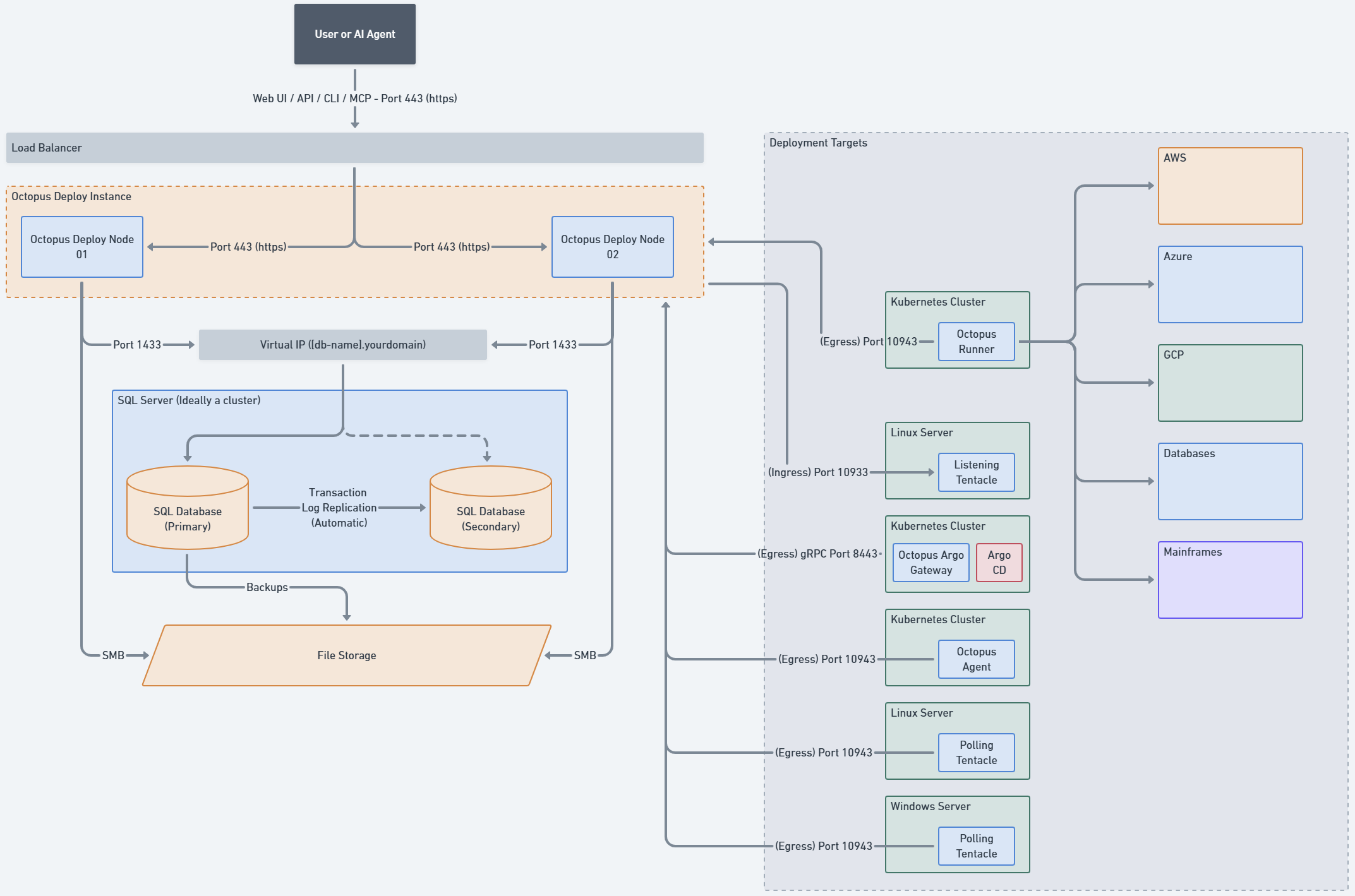
This document will provide you with guidelines and recommendations for self-hosting Octopus Deploy.
Supported Octopus Deploy Server Versions
Each self-hosted major.minor release of Octopus Deploy will receive critical patches and support for a period of six months. For example, 2025.4 was released in December 2025 and will be supported through May 2026.
All new releases of Octopus Deploy will run in Octopus Cloud first for at least one quarter. As a result, Octopus Cloud is always at least one version ahead of the self-hosted version.
Because of that, we always recommend using the latest available release for your self-hosted installation of Octopus. Please see the Octopus.com/downloads to download the latest version of Octopus Deploy.
For more details, please refer to our blog post announcement from 2020, when we introduced this release cadence.
Host Octopus on Windows Server or as a Linux Container
Our recommendation is to host Octopus Deploy Windows Server over the Octopus Server Linux Container unless you are okay with all these conditions:
- You plan on using LDAP, Okta, Microsoft Entra ID, Google Workspace, or the built-in username and password to authenticate users. The current version of the Octopus Server Linux Container only supports Active Directory authentication via LDAP.
- You are okay running at least one worker to handle tasks typically done by the Octopus Server. The Octopus Server Linux Container doesn’t include PowerShell Core or Python.
- You are familiar with Docker concepts, specifically around debugging containers, volume mounting, and networking.
- You are comfortable with one of the underlying hosting technologies for Docker containers; Kubernetes, ACS, ECS, AKS, EKS, or Docker Swarm.
- You understand Octopus Deploy is a stateful, not a stateless application, requiring additional monitoring.
Due to how Octopus stores the paths to various BLOB data (task logs, artifacts, packages, imports, event exports etc.), you cannot run a mix of both Windows Servers, and Octopus Linux containers connected to the same Octopus Deploy instance. A single instance should only be hosted using one method.
We are confident in the Octopus Server Linux Container’s reliability and performance. After all, Octopus Cloud runs on the Octopus Linux container in AKS clusters in Azure. For more information, please see Octopus Server Linux Container.
Create a single production instance
One question we get asked a lot is “should we have a single instance to deploy to all environments or have an Octopus Deploy instance per environment?” Unless there is a business requirement, our recommendation is to have a single instance to deploy to all environments and use Octopus Deploy’s RBAC controls to manage permissions. We recommend this to avoid the maintenance overhead involved with having an instance per environment.
Of the customers who opt for an instance per environment, we see them have an instance for development and test environments with another instance for staging and production environments.
If you chose this instance configuration, you would need a process to:
- Clone all the variable sets and project variables, and notify you when a new scoped variable is added.
- Sync the deployment and runbook processes, but skip over steps assigned to development and test.
- Update any user step templates to the latest version.
- Ensure the same lifecycle names exist on both instances but not have the same phases.
- Copy releases but not deployments.
- Clone all the project channels.
- And more.
Using the Octopus Deploy API, all of that is possible; however, it will require diligence and maintenance on your part. Unless there is a specific business requirement, such as security team requirements or regulatory requirements, we don’t recommend taking that on.
Run the Octopus Service, SQL server, and files on separate infrastructure
It is possible to run the Octopus Deploy service, SQL Server, and file storage on the same Windows Server or container orchestrator. That is not recommended for production instances of Octopus Deploy. Aside from having a single point of failure, it can lead to performance issues.
The database should run on a dedicated SQL Server, or using a managed SQL Server like AWS RDS, or Azure SQL. The files should be stored on a NAS, SAN, or on a managed file storage platform like Azure File Storage that supports SMB/CIFS. Shared services like these are managed by dedicated individuals, such as DBAs or Network Admins. They provide common day 2 maintenance such as backups, restoring, and performance monitoring.
While it is possible to run SQL Server in container, we do not recommend it for production use. Whenever possible use a managed SQL Server like AWS RDS or Azure SQL, or use a SQL Server already managed by DBAs.
Use a load balancer for the Octopus Deploy UI
The Octopus Deploy UI is a stateless React single-page application that leverages a RESTful API for its data. We recommend using a load balancer for Octopus Deploy as soon as possible. This will make it much easier to move to high availability. In addition, it’ll be easy to rebuild or change the underlying Windows Server or to move to Linux Containers in the future.
Any standard load balancer, be it F5, Netscaler, or provided via a cloud provider, will work. If you need a small load balancer, NGINX will provide all the functionality you’ll need.
The recommendations for load balancers are:
- Start with round-robin or “least busy” mode.
- SSL offloading for all traffic over port 443 is fine (unless you plan on using polling Tentacles over web sockets).
- Use
/api/octopusservernodes/pingto test service health.
Octopus Deploy will return the name of the node in the Octopus-Node response header.
If you plan on having external polling Tentacles connect to your instance through a load balancer / firewall you will need to configure passthrough ports to each node. Our high availability guides provide steps on how to do this.
Compute Recommendations
The compute resources for your Octopus Deploy instance are dependent on the number of concurrent deployments and runbook runs. By default, Octopus Deploy processes five (5) deployments and runbooks concurrently. That is known as a task cap, and it is configurable. The higher the task cap, the more compute resources your instance will need.
The Octopus server will process additional tasks, such as applying retention policies, health checks, processing triggers, syncing community library step templates, and syncing Active Directory users and groups. Generally, deployments and runbook runs are the most computationally expensive tasks, which is why we use them to determine how many compute resources you need.
Use the following table below as a starting point for your compute resources. You are responsible for monitoring the resources consumed and ensuring your Octopus Deploy infrastructure isn’t under or over-provisioned.
| Task Cap Per Node | Windows Compute Resources | Container Compute Resources | Database on Virtual Machines | Azure DTUs |
|---|---|---|---|---|
| 5 - 10 | 2 Cores / 4 GB RAM | 150m - 1000m / 1500 Mi - 3000 Mi | 2 Cores / 4 GB RAM | 50 DTUs |
| 20 | 4 Cores / 8 GB RAM | 1000m - 2000m / 3000 Mi - 6000 Mi | 2 Cores / 8 GB RAM | 100 DTUs |
| 40 | 8 Cores / 16 GB RAM | 1250m - 2500m / 4000 Mi - 8000 Mi | 4 Cores / 16 GB RAM | 200 DTUs |
| 80 | 16 Cores / 32 GB RAM | 2000m - 4000m / 5000 Mi - 10000 Mi | 8 Cores / 32 GB RAM | 400 DTUs |
| 160 | 32 Cores / 64 GB RAM | 3500m - 7000m / 6000 Mi - 12000 Mi | 16 Cores / 64 GB RAM | 800 DTUs |
Use High Availability at scale
While it is possible to configure a single-node instance to process 100+ deployments concurrently, it is not something we recommend. Once you go beyond 40 concurrent deployments, we recommend using Octopus Deploy’s High Availability to scale horizontally. 40 to 80 concurrent deployments per Octopus Deploy node tends to the “sweet spot” for the maximum number of concurrent deployments.
Please see our implementation guide for High Availability for more details.
Further reading
For further reading on installation requirements and guidelines for Octopus Deploy please see:
- Installation
- Requirements
- Permissions for Octopus Windows Service
- Octopus Server Linux Container
- Configuring the Octopus Task Cap
Help us continuously improve
Please let us know if you have any feedback about this page.
Page updated on Wednesday, May 15, 2024