Octopus has a data migrator that can help with specific scenarios, such as exporting configuration for storage and audit with a source control repository and single-direction copying of projects from one Octopus Server to another.
If you want to migrate data between Octopus instances, we recommend the Export/Import Projects feature rather than the data migrator.
Suitable scenarios
Since the Export/Import Projects feature was added, the number of suitable scenarios for the data migrator has reduced to the following:
- Copying projects and their dependencies from one Octopus Server to another periodically in a single direction where there is a single source of truth.
- Wanting to exclude tenants, releases, or deployments from the migration.
The same version of Octopus must be running on the source and destination servers.
Unsuitable scenarios
The data migration tools are only suitable for some scenarios. In most cases, there are better tools for the job:
- To split a single Octopus Server into multiple separate Octopus Servers in a one-time operation, use the Export/Import Projects feature.
- To sync projects with disparate environments, tenants, lifecycles, channels, variable values, or deployment process steps, see syncing multiple instances
- To consolidate multiple Octopus Servers into a single Octopus Server, use the Export/Import Projects feature.
- To audit your project configuration, see configuration as code.
- To split a single space into multiple spaces, see the Export/Import Projects feature.
- To migrate data from older versions of Octopus see upgrading old versions of Octopus.
- For general disaster recovery, learn about backup and restore for your Octopus Server.
- To move your Octopus database to another server, see moving your database.
- To move your Octopus Server and database to another server, see moving your Octopus Server and database.
- To move your entire Octopus Server from a self-hosted installation to Octopus Cloud, see migrating from self-hosted to Octopus Cloud.
Unsupported scenarios
Sometimes, using the data migration tool may seem like it could solve a problem, but in fact, it will make things worse. Here are some scenarios we’ve seen that are explicitly not supported.
- Export ➜ Modify ➜ Import
Unfortunately, since the import isn’t running the same validation checks as the API, using an export ➜ modify ➜ import can modify your data in such a way that is invalid for the API. Some scenarios might work but because, at this point, you’re effectively hand-editing your data, this isn’t something we support.
Tips
- Data migration is an advanced topic. You should take time to understand the tools, what they can do, and what they are unsuitable for.
- You cannot migrate data between different versions of Octopus Server - they must be exactly the same version to ensure the integrity of the data.
- The data migration tools are optimized for one-time operations or for flowing data in a single direction with a single source of truth.
- The data migration tools generally overwrite data in the target server without merging.
- Data is matched by name instead of ID.
- There are no built-in conflict resolution tools.
- You can commit the exported files to source control and track changes over time.
- Treat data migration as an offline operation. You want to avoid exporting changing data or importing over the top of changing data.
- Perform a backup before importing data.
- All changes made during data import are batched into a single SQL transaction. The entire import will succeed or roll back as a batch.
The Basics
Exporting
It’s a good idea to ensure that your Octopus Server doesn’t change data while exporting. Learn about making your Octopus Server read-only using maintenance mode.
You can export data using the Export Wizard built into the Octopus Server Manager or the command-line interface Octopus.Migrator.exe. You can export your entire Octopus Server configuration or certain projects and their dependencies.
The wizard is a good way to get started, but the complete feature set is only available using the command-line interface.
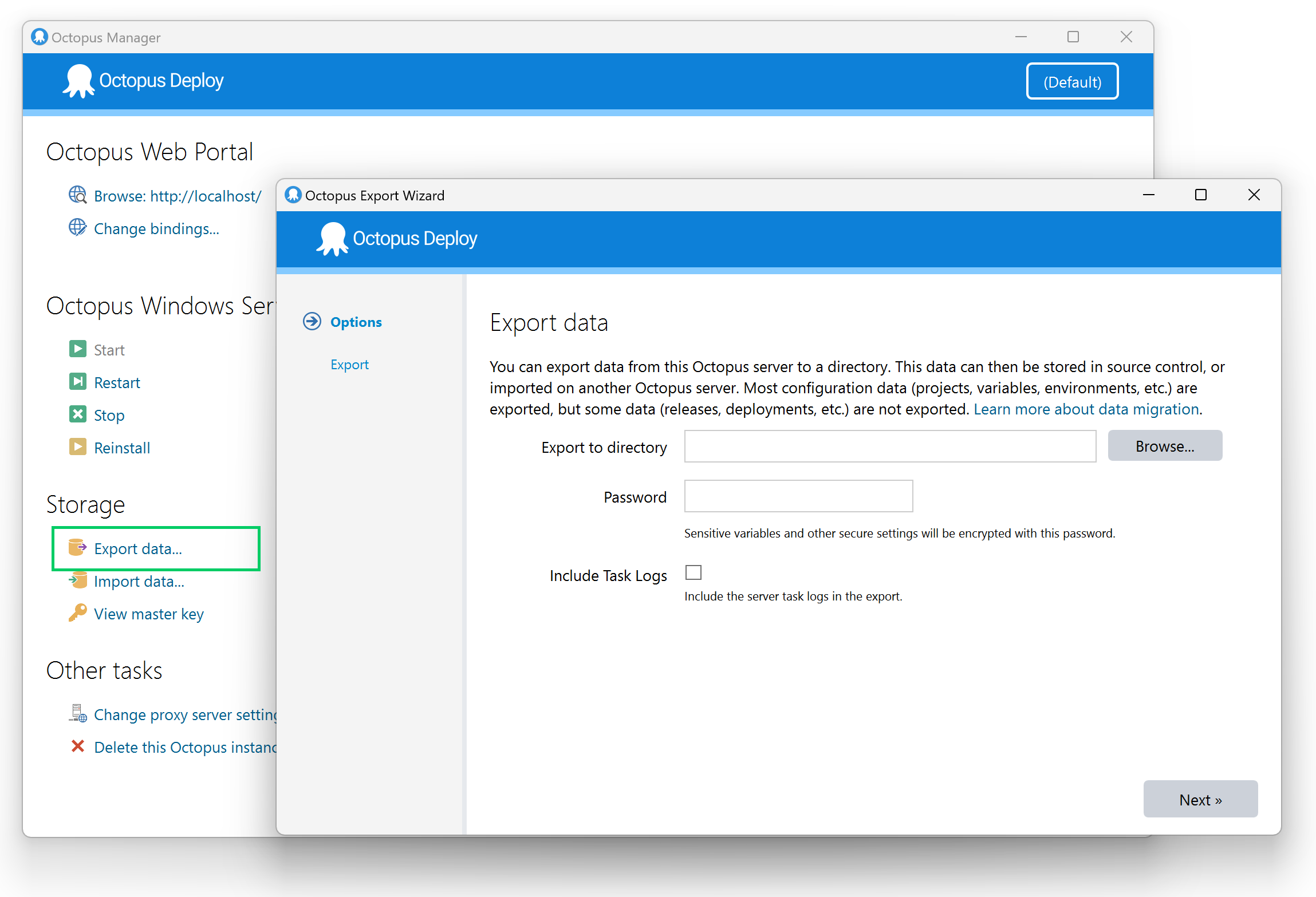
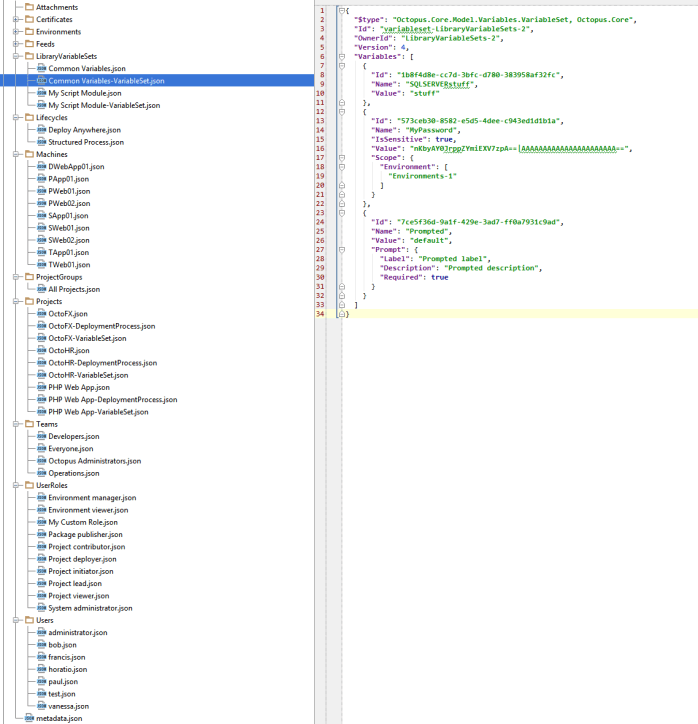
We have made the exported file structure predictable and easy to navigate.
Importing
It’s a good idea to perform a backup before attempting an import.
You can import data using the Import Wizard built into the Octopus Server Manager or the command-line interface Octopus.Migrator.exe import. Similarly to exporting data, the wizard is a good way to get started, but the complete feature set is only available using the command-line interface.
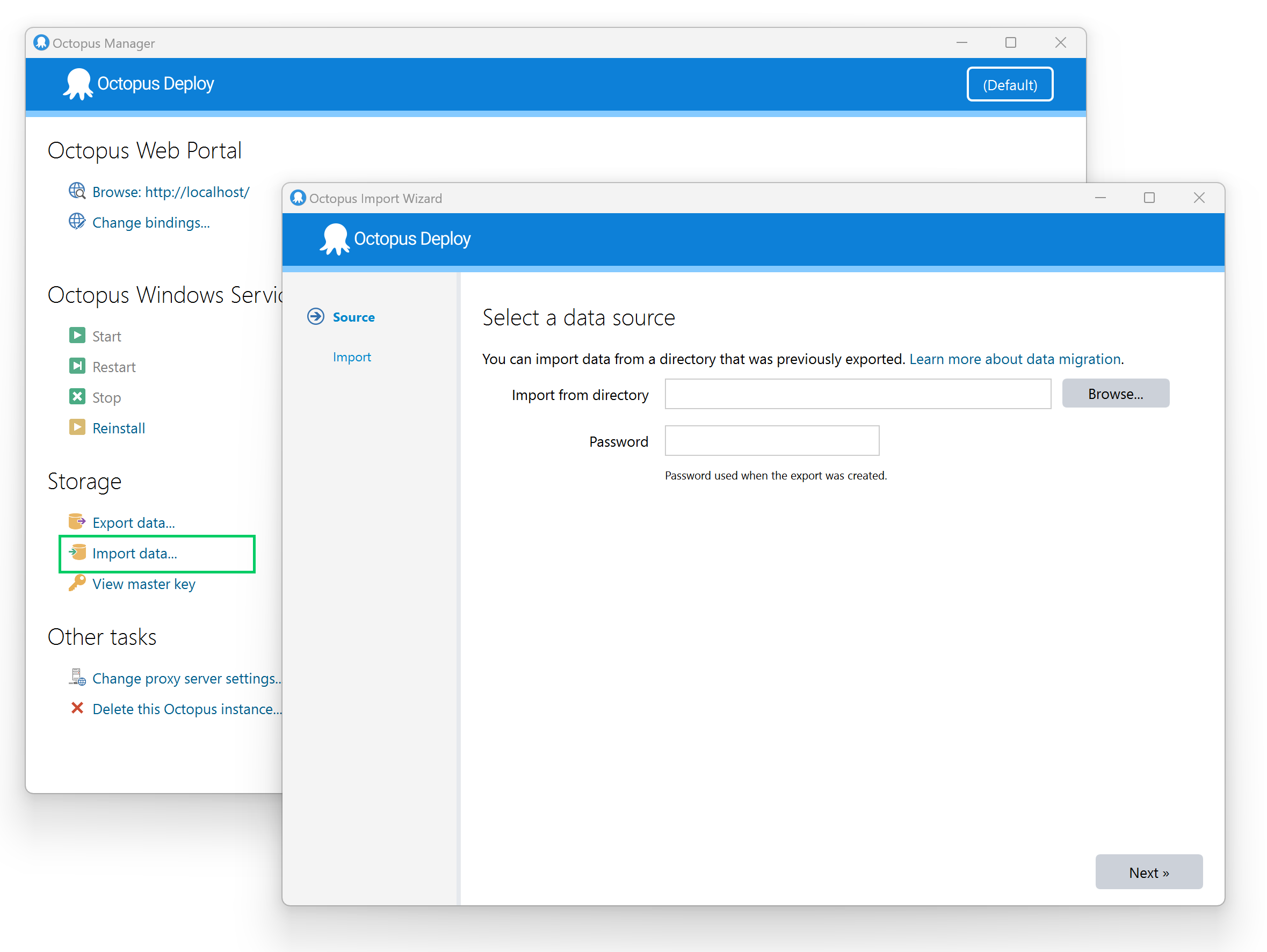
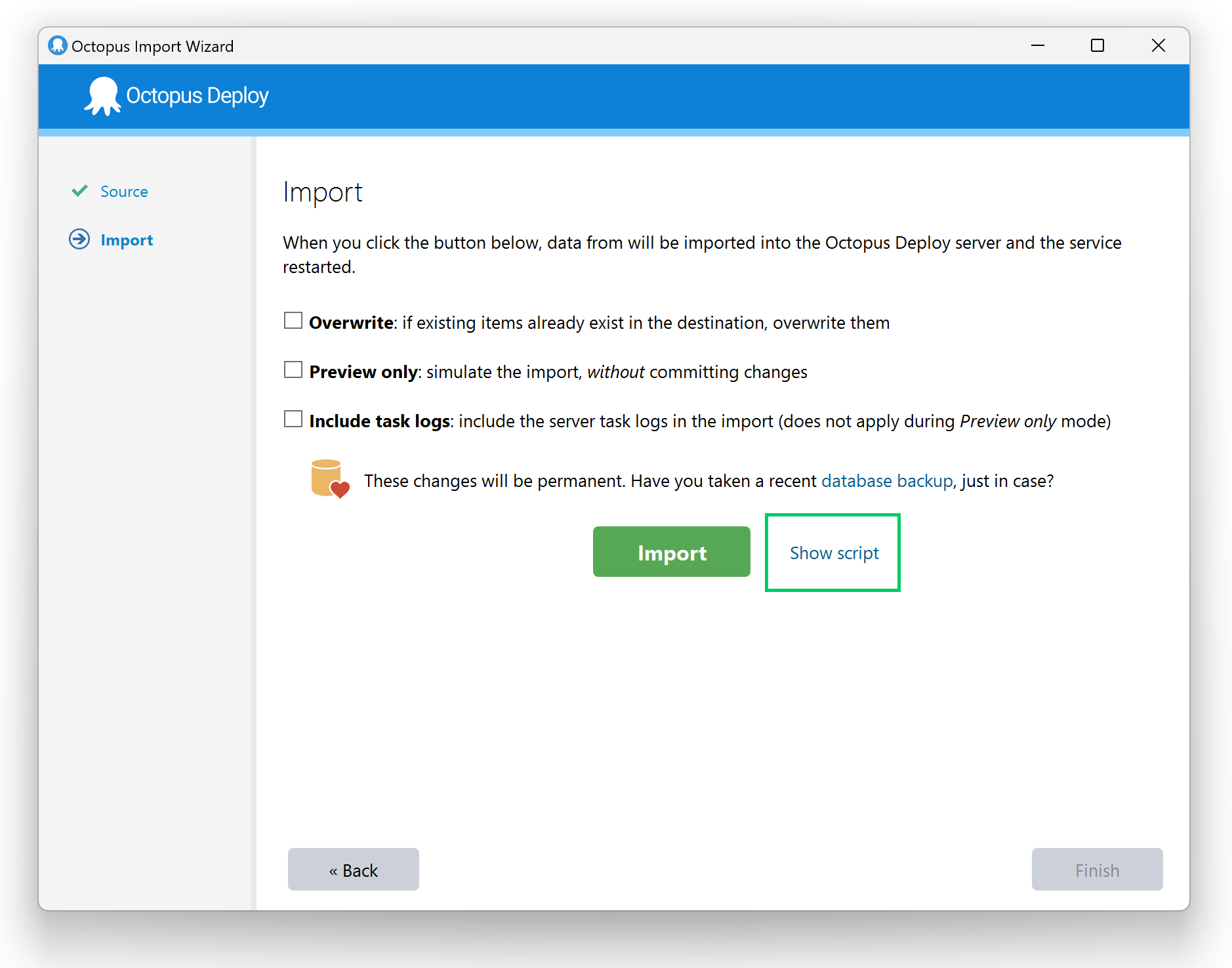
You’ll get a chance to preview the changes first, and you can tell the tool to either:
- Overwrite documents if they already exist in the destination (e.g., if a project with the same name already exists, overwrite it).
- Skip documents if they already exist in the destination (e.g., if a project with the same name already exists, do nothing).
Learn about how conflicts are handled.
All changes are batched into a single SQL transaction; if any problems occur during the import, the transaction will be rolled back, and nothing will be imported.
FAQ
What is exported?
You can choose whether to export your entire Octopus Server configuration using the Octopus.Migrator.exe export command. Alternatively, you can export a set of projects and their dependencies using the Octopus.Migrator.exe partial-export command. The best way to see what is exported is to try it out and look at the resulting files.
How do you handle sensitive values?
Sensitive values are always encrypted at rest.
When you export data, you will be asked to provide a password. Your secrets will be decrypted using the source server’s Master Key and then re-encrypted into the exported files using the password you provided as the key.
When you import data, you must provide the same password so your secrets can be decrypted from the files and imported into the target server to be encrypted using its Master Key.
Can I track my Octopus configuration using source control?
Yes, though it is an advanced scenario, you will need to take care of yourself. We are looking into other methods for defining your deployment processes as code.
In the meantime, you can use this process for advanced auditing of your Octopus configuration:
- Export your data to a known location.
- Commit those files to source control.
- Set up a scheduled task to repeat the process periodically, using the same encryption password each time.
The JSON is as predictable as possible, so if you commit multiple exports, the only differences that will appear are the actual changes that have been made, and comparing the changes will be obvious.
How do you match existing data?
The import process matches on names instead of IDs. If an exported project has the same name as a project in the target server, it is considered the same.
How are conflicts handled?
The incoming data is viewed as the source of truth during the import, and existing documents will be overwritten.
For example, when importing a project that already exists in the destination server, all deployment steps that belong to the project in the destination server are overwritten, including any new deployment steps that may have been added.

There is no out-of-the-box way to “merge” deployment steps, or other more granular changes when importing.

There are certain cases where we can automatically merge data, like variable sets where you have specific values that only make sense in the target server or teams where certain users only make sense in the target server.
Can I manually resolve conflicts?
There is no tooling to help you resolve conflicts in a more granular way. The data migration tooling is optimized for data flowing in a single direction with one source of truth.
Why do the exported files contain IDs?
We use the IDs to map references between documents into the correct references for the target server. We use the names to determine if something already exists. This means you can export from multiple Octopus Servers, combine them, and then import to a single Octopus Server.
Is there a command-line interface?
Yes! Most features are only available via the command line, so it is the most common way to perform data migration. Use Octopus.Migrator.exe help to see the full list of commands available. To see an example of the command syntax, you can use the Wizard in the Octopus Server Manager and click the Show script link.
Help us continuously improve
Please let us know if you have any feedback about this page.
Page updated on Monday, July 15, 2024