Introduction
This first part in the history of software delivery begins in the 1950s and looks at the first 4 decades of modern computer programming. Some specific examples will help to illustrate the development of models in this era:
- The Lincoln Laboratories model
- The waterfall model
- The spiral model
There’s also a description of software development in this era. This explains some reasons these models emerged as organizations attempted to manage larger software systems.
Phased software delivery models dominated software delivery throughout the first 40 years. These models were partly inspired by manufacturing and construction, where each stage was performed once and where the completed project was difficult to change. A different specialist would perform each step, and there would be control stages to validate the work.
Historical factors
Early programmers had a very different experience from modern software developers. These factors give us some empathy with the creators of these heavyweight software delivery models.
In the 1950s, high-level compiled languages were a brand new invention. While self-taught programmers were having success writing small programs on their own, they were now tackling far bigger problems. The software delivery world faced the new challenge of writing a program that was too large for a single individual to understand. Multiple people needed to contribute to the same code base, which required mechanisms for a programmer to share what they knew about the program with others.
Additionally, it wasn’t easy to create a team to produce software in the mid to late 20th century because there weren’t many programmers. Accurate statistics are hard to obtain, but the US Census Bureau tracks occupations by role. In 1970 there were fewer than 200,000 programmers in the US; this rose to 1.6 million by 2015. If you think it’s hard to find programmers now, imagine what it was like in the 1950s.
Modern programming languages are usually highly readable. Code is stored in version control, with fast search tools and instant access to the complete history of changes. We have IDEs (Integrated Development Environments) and advanced text editors that let us navigate the code. We have powerful auto-completion tools that make suggestions as we type. We can get the machine to perform accurate refactorings using simple keyboard shortcuts. When 2 people edit the same file, the tools help us merge our changes and integrate them into a single canonical version that will be packaged and deployed.
In contrast, early programmers used hand-written code listings, punch cards, print-outs, or had to time-share an expensive machine and its console. It was difficult to find code and update it, and no keyboard shortcut would instantly find all uses of a function throughout the application. There was no immediate feedback from compilers running in the background to check the code. There were no build or deployment tools, and many organizations had to write these compilers and tools to support their own development efforts.
The languages and tools available at the time had a titanic influence on the software delivery models that organizations created to tackle large complex programs.
There was also a contrast in software economics. Programmers were paid $15,000 a year, but computers cost $500 per hour to run. This made computers more than 50 times more expensive than programmers. Today, each programmer has their own computer, which costs 70 times less than their salary.
Lean manufacturing, though it existed, had not made it into the north-western hemisphere’s mindset yet. That would happen in the 1990s when the The Machine That Changed the World was published. In the West, manufacturing and construction had no references to the Toyota Production System when the newly formed programming industry searched for metaphors to guide them. US and UK government, military, and academia funded many notable early projects. Their demands would have been a pivotal influence on the process.
One of the biggest revolutions for information sharing is the Web. We can now read thousands of articles and case studies, watch videos, attend conferences, and participate in discussions through The Web. Many early models would have been published in trade journals or transcribed from presentations, limiting access to the information and to valuable real-world feedback from people trying to use them.
With these incredible differences in mind, we can view the following examples with some understanding and empathy for why they emerged. When selecting examples, the selections have been made based on the prevalence and influence of each model.
The Lincoln Labs phased model
MIT’s Lincoln Laboratory had been working on a secret project, later revealed to be the US SAGE (Semi-Automatic Ground Environment) air-defense system. This challenging project aimed to connect dozens of radars to a machine for analysis and relay. Like many early projects, there was a mixture of software and hardware. For example, the team invented magnetic core memory to solve speed and reliability issues found during the project.
The phased software model used to develop the system was described by Herbert D. Benington in a presentation in 1956 titled Production of Large Computer Programs. The process had 9 phases:
- Operational plan
- Machine and operational specifications
- Program specifications
- Coding specifications
- Coding
- Parameter testing
- Assembly testing
- Shakedown
- System evaluation
Many of these phases created or depended on specification documents that were used to design tests and share knowledge of the system.
The solid lines in the diagram describe the process used to design the system, with the dotted lines showing the relationship between the documentation and testing phases.
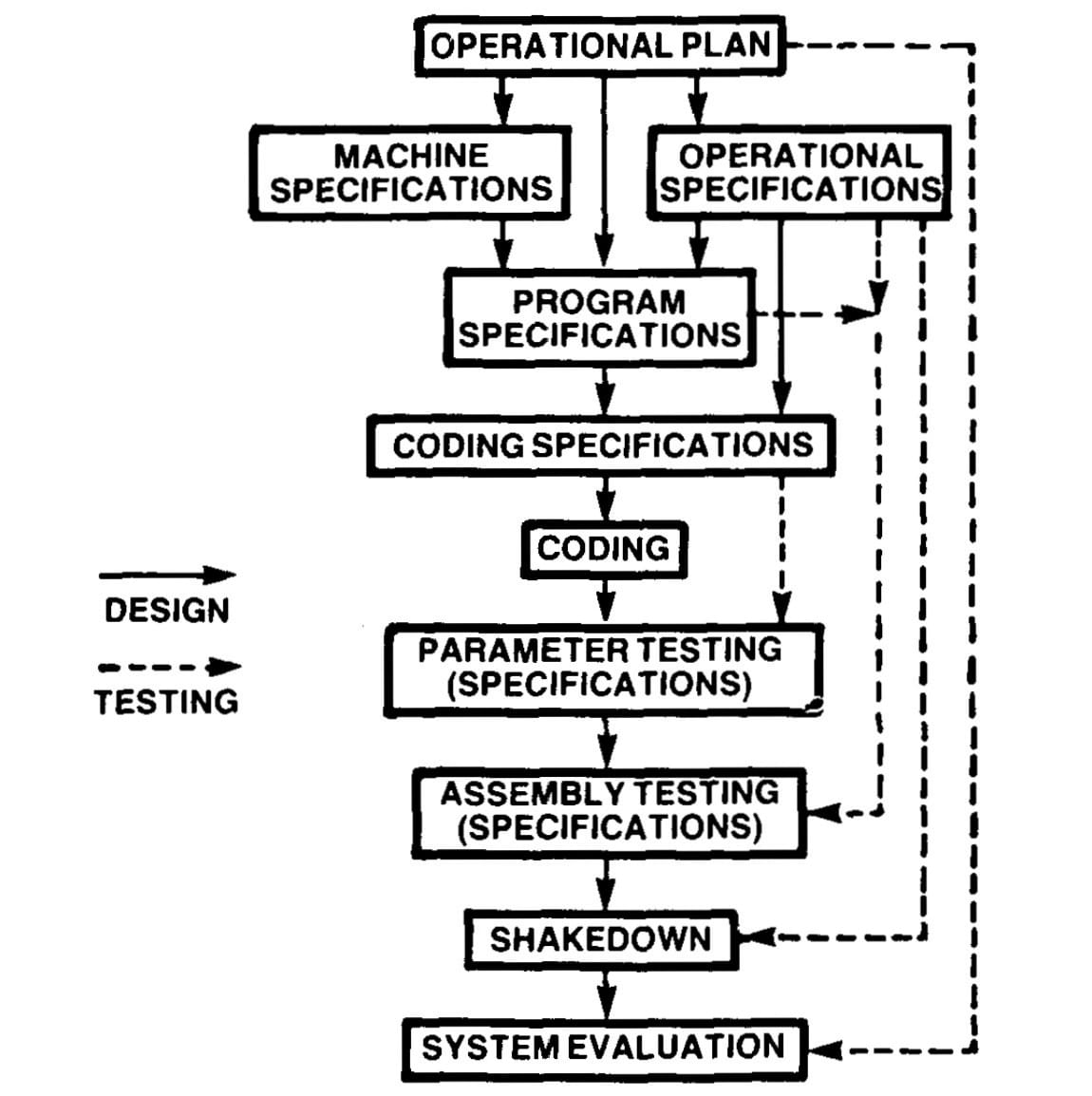
Source: Production of Large Programs. Herbert D. Benington. 1956.
The “parameter testing” phase is a form of isolated component testing where dependencies were simulated. All components were then assembled into a complete system and tested together in the “assembly testing” phase. These 2 phases were performed on the development machine, where the code was being integrated. The final testing phase, called a “shakedown”, tested the system on the production machine.
The purpose of Benington’s paper is essentially a call to action. He saw a great opportunity for the industry to use computers to reduce the cost of programming, documentation, and testing: “How can we reduce this cost?” he asked, referring to the enormous expense of changing the documentation, tests, and code once the system was in use. “Obviously, as we have done already, by more extensive use of the computer.”
About half of the code written as part of the SAGE project was for supporting utilities, compilers, and instrumentation.
Though this approach became the de-facto reference for software delivery, Benington didn’t recognize the Lincoln Labs approach in how the industry was applying the ideas. He didn’t like the interpretation of the phased approach as top-down programming where the initial specification was fully completed before the code was written. In 1983 he said this was “misleading and dangerous,” yet many organizations would continue to run large fully-specified projects. Instead, he told the industry to create a working prototype and use it to evolve a system.
This criticism was a possible influence on the spiral model, one of the examples featured shortly. First, though, we need to tackle the big one: Waterfall.
Waterfall
When Winston Royce wrote about phased software development in his 1970 paper Managing the Development of Large Software Systems, his diagram looked like a staircase waterfall. Royce didn’t give his model a name; the “waterfall” moniker was first applied to Royce’s approach in 1976 by T. E. Bell and T. A. Thayer, in their paper Software Requirements: Are They Really a Problem?.
In his paper, Royce says there are 2 essential steps for software development: analysis and coding. He said that this was ”… all that is required if the effort is sufficiently small and if the final product is to be operated by those who build it.” He also warned that attempting to create a more extensive system using this two-step model was “doomed to failure.”
Royce’s full waterfall model is shown below. This isn’t the version that is usually shared, as the majority of people preferred the simpler stepped diagram, where each stage only feeds back to its predecessor. Royce warned that this purely sequential approach would be “risky and invited failure.” Despite this warning, the allure of the sequential approach made it the basis for most software delivery approaches for 2 decades.
The complete model had 8 phases, a prototype, 4 kinds of reviews, and 6 documents.
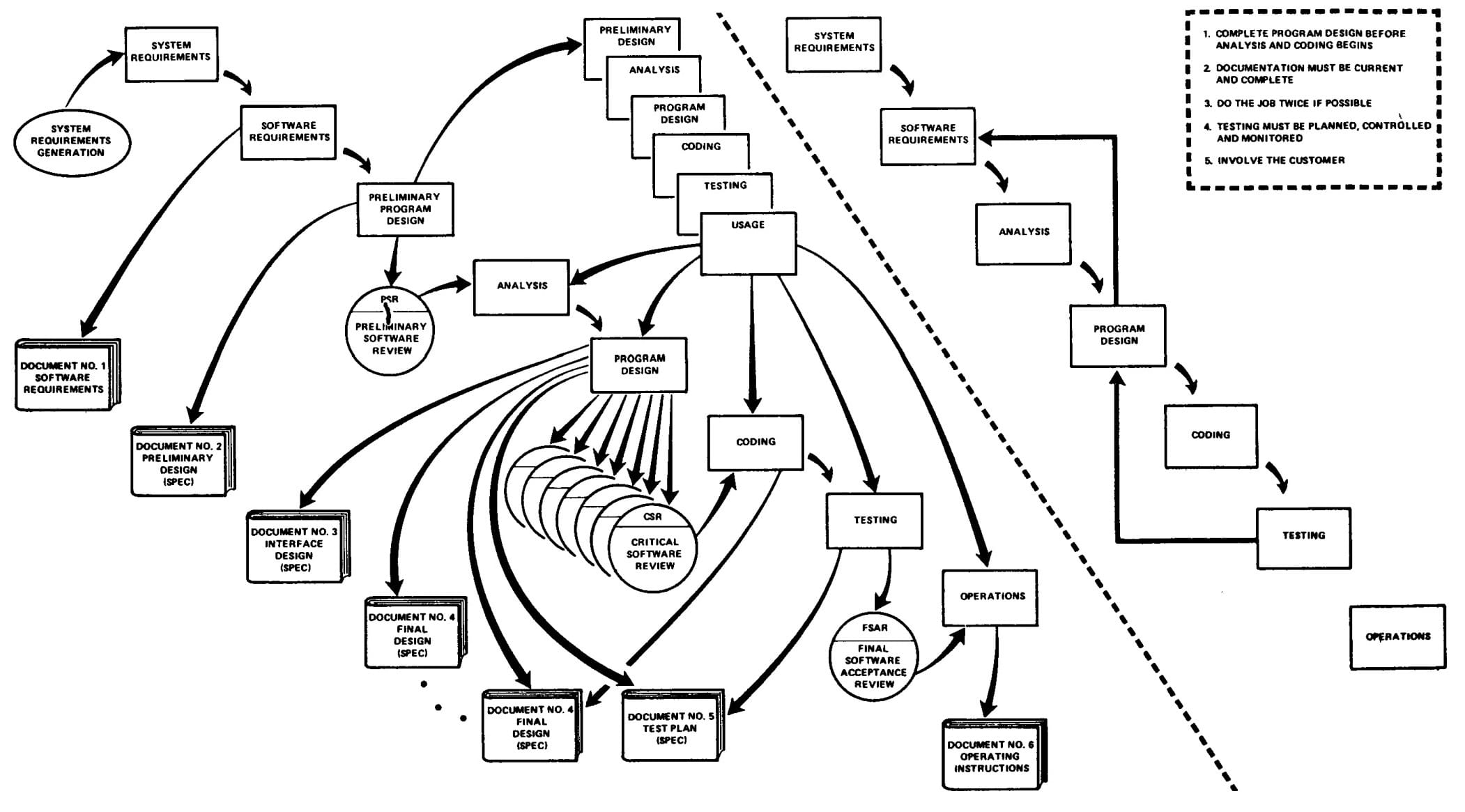
Source: Managing the Development of Large Software Systems. Dr. Winston W. Royce. 1970.
One of Royce’s gifts to the future is his suggestion that the key to working with a more complex multi-stage phased delivery model was to work in small incremental changes. He thought this would reduce the complexity and allow an organization to return to an earlier baseline if there was an unforeseen difficulty creating the new version.
Most suggestions in the paper involve introducing more documents and adding review stages. While there was a call to involve the customer, this was described as a formal commitment rather than a collaborative working partnership. The signature-driven customer relationship was symptomatic of the contractual approach used by government departments and businesses for software acquisition at the time.
The waterfall model recognized many of the problems that had emerged in phased software delivery, but as with Benington, most organizations ignored Royce’s warnings. It was primarily the documentation and control aspects of his proposal that were added to the phased approach. This made things slower and more expensive without realizing the benefits that might have been obtained from Royce’s recommendations on using prototypes and working in small increments.
The problems with phased delivery continued for a further decade, prompting Benington to claim the problems were being caused by organizations failing to follow the Lincoln Labs model correctly. Royce - and almost every other process author since - could have made similar claims about their ideas being incorrectly used.
Though not the intention, the legacy of waterfall was to solidify the phased model and increase reliance on formal documents.
The spiral model
By 1988, when Barry Boehm wrote A Spiral Model of Software Development and Enhancement, variants of waterfall were the dominant mechanisms for controlling software projects. Boehm noted that waterfall had helped to solve some problems. Still, he challenged the order of phases and the emphasis on fully elaborated documents as the basis for moving between stages. This echoed some of Benington’s challenges to top-down document-driven approaches.
The spiral model arranged the phases of software delivery in an infinitely expanding spiral. The diagram itself contains several elements that are commonly missed.
There are x and y axes dividing the chart into 4 quadrants that represent specific categories of activity:
- Determine objectives, alternatives, and constraints
- Evaluate the alternatives, identify and resolve risks
- Develop and verify the next-level product
- Plan the next phase
The exact phases that would form the development and testing quarter were to be determined in the risk analysis stage that preceded them. This meant the approach could be tailored based on the risks identified.
The x axis also indicates the cumulative cost of the initial development and the subsequent enhancements. The model included a pre-flight round 0 to set up the project and assess feasibility, followed by a series of rounds to produce incremental working prototypes. The initial software cycles delivered an operational product, and further cycles would be used for enhancements and maintenance. The spiral could continue indefinitely and was only terminated when the product was retired.
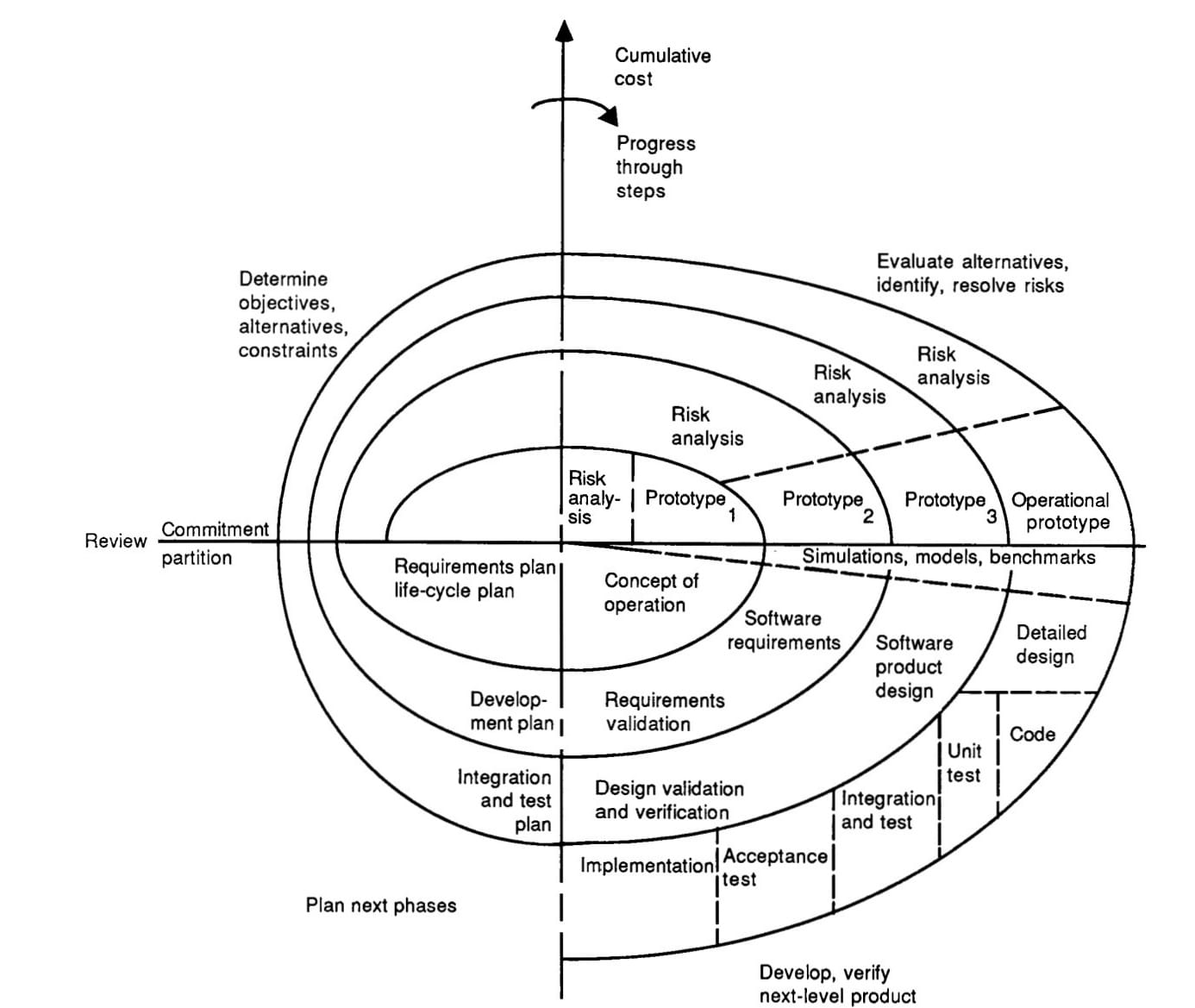
Source: A Spiral Model of Software Development and Enhancement. Barry W. Boehm. 1988.
The spiral model encouraged incremental delivery against a set of options. Each cycle would be small enough to deliver an agreed outcome against a selected option, using a process that was proportionate to the risks. It was possible to use feedback from the prototype to change direction by selecting one of the alternate options, or to stop funding it altogether.
Some of the goals of the spiral model included finding and fixing errors earlier, generating and eliminating different options, and performing maintenance and enhancements the same way as the initial development.
In the original paper, Boehm identified that one of the challenges to this approach was the nature of contracts used in software acquisitions. To use incremental and adaptable approaches to software delivery, contracts would also need to become more flexible.
These goals and challenges directly influence the next era of lightweight methods, which you’ll find in part 2 of the series.
Summary
Before models, software delivery was an ad-hoc code and fix process. The phased model was a response to the problems found in this approach. Each time a weakness was identified, a phase was added in an attempt to mitigate it. Systems written using code and fix became hard to change, so a design phase was added to try and reduce the cost of these changes. If the system didn’t meet the users’ needs, an analysis phase would be added to understand the requirements better.
When there were still problems after phases were added, it was considered a control issue. Organizations tried to solve control issues with documents and formal reviews. The amount of time to take a requirement through the phased approach increased, so it took longer to discover problems. The cost of handovers encouraged organizations to do them less often, which meant the size of a batch of work increased.
It turned out that all of the phases, documents, and controls introduced by heavyweight processes failed to reduce the rate of failure in software delivery. Many of the reported failures were undoubtedly caused by naive adoptions of phased delivery, something the authors were keen to assert in the 1980s.
Some organizations spotted the danger of ever-increasing project size and started to experiment with evolutionary approaches, but in many cases this was a return to code and fix delivery with all the associated issues.
The spiral model was created in response to the problems of both phased and evolutionary delivery. The solution wasn’t to increase batch sizes and add more control steps, or to go to the opposite extreme and have no process at all. Instead, the spiral model encouraged organizations to work in smaller batches and tailor the process for each increment according to the risks.
Although modern software developers dismiss the heavyweight era, plenty of revolutionary seeds were planted during this time. Royce warned of the dangers of feedback being delayed. He also noted that risk increases in line with project size and that control steps would add to project costs. The concept of prototypes features in all the examples. The spiral model assimilates Benington’s suggestion about incrementally evolving the prototype towards the operational product rather than building an extensive system in one big boom-or-bust attempt.
The second part of this history investigates the rise of lightweight, adaptive, and agile methods.
Help us continuously improve
Please let us know if you have any feedback about this page.

