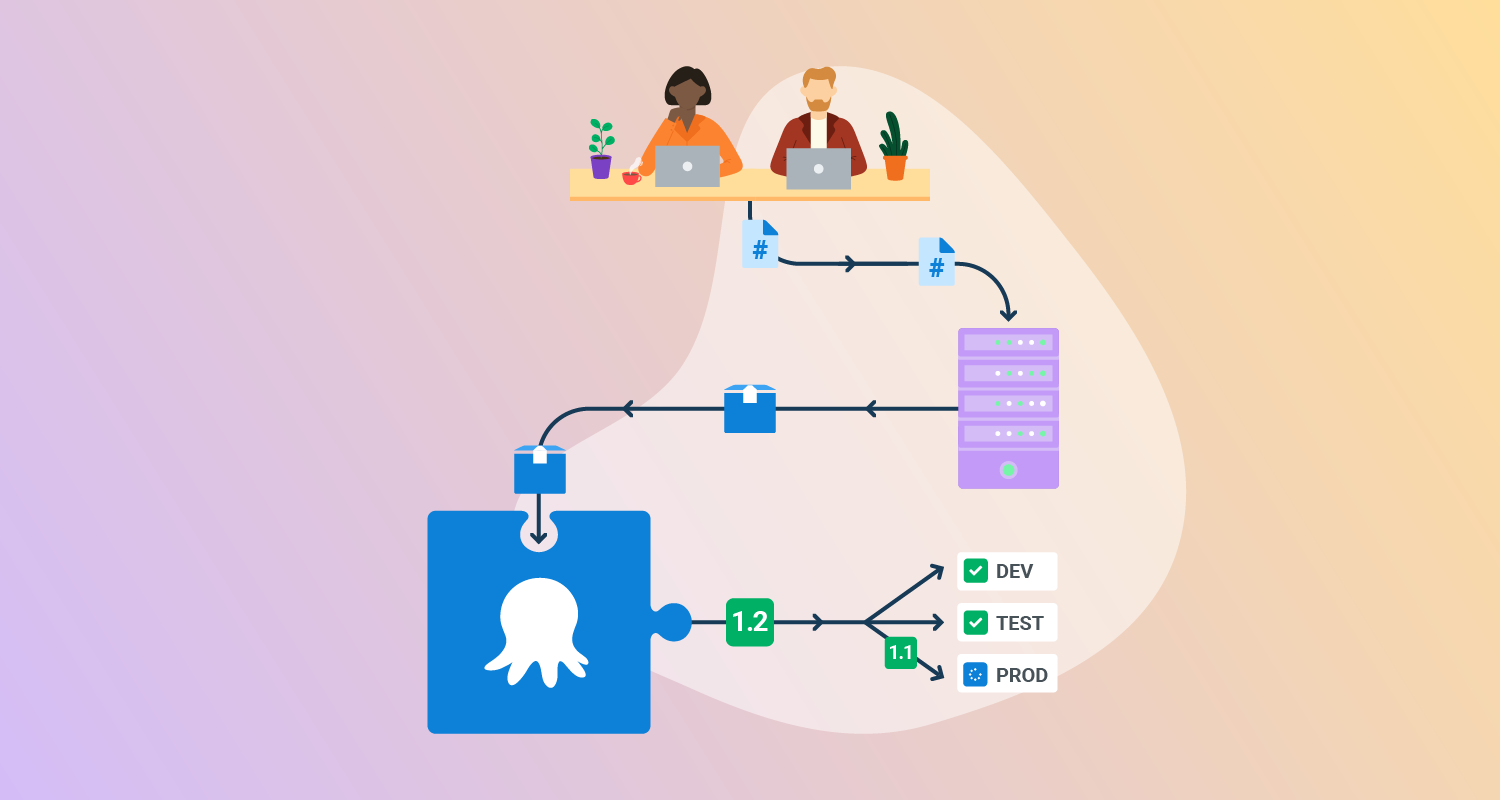
Continuous Delivery (CD) often requires significant up-front investment and it takes time to create a high-performance deployment pipeline. You need to put tools in place to maximize the impact of Continuous Delivery on your software delivery performance. At times, it might seem like it’s too difficult without enough tangible benefits.
On this page we explain why you should adopt Continuous Delivery, the pain it removes, and the concrete benefits you can expect in return. We show you a:
- Reinvestment strategy you can use to create a self-funding continuous improvement budget
- Model that shows you’re likely to make the returns faster than you might think
Reasons to adopt Continuous Delivery
Here are some common scenarios that cause friction for teams. Building the team’s Continuous Delivery skills will help remove this friction.
Painful deployments
You’re not alone if your deployment process causes a sense of fear or anxiety. There are many signs your deployments are more challenging than they should be:
- Manual deployments: You follow a checklist or document to perform the deployment, and sometimes miss steps or perform them out of order.
- Long deployments: Your deployment process takes more than a couple of minutes, sometimes hours.
- Out-of-hours deployments: Your deployments must happen during unsociable hours and sometimes take all night.
- Infrequent deployments: You only deploy once a month, quarter, or even less frequently.
- Change freezes: You can’t deploy during the peak season, usually because of a past blow up.
Repeatable, reliable, and predictable deployments remove this pain, helping you focus on making the best software you can, without dreading deployment time.
Painful onboarding
When new developers join a team, they can feel accomplishment and relief by making their first change to an application. If they can’t start quickly by getting the latest version of the code from source control, the day-one nerves continue until they feel productive.
Some signs that your onboarding is painful include:
- Needing to install tools, frameworks, and dependencies on their local machine
- Having to check out and run other services locally that your application depends on
- Needing to restore a database locally that contains test data, or sharing a development database that keeps changing
- Needing to update the version-controlled config files to reflect their local environment
- Waiting for weeks or months for their first change to go live
Painful pre-live environments
Pre-live environments often present several kinds of pain. There’s often contention over who uses an environment at any given time, and they can often be very different to production infrastructure.
For example, it’s common to find applications designed to scale horizontally, with many instances of the application deployed to handle the load. If the pre-live environment doesn’t represent this, there are whole classes of faults you can’t detect until you go live.
Testers often find they can’t use a new software version due to a critical issue, like the sign-in page not working. They sometimes have to wait in a queue for an environment or get surprised by a new version of the software that another tester deployed while they were still testing a previous version.
Making it possible for testers to pull a version of the software on-demand to a temporary environment created only for their use is a much better solution.
Painful batches of work
Often made worse by infrequent deployments, batches of work can quickly become painful as good changes get stuck when they’re in the same software version as bad changes.
If you continue to add changes while you wait for fixes, you often add a new bad change while resolving a previous one. This usually gets so bad the organization declares a change freeze where developers can only fix those bugs.
One sign of painful batches is a list of known faults arranged into categories. These show whether they’ll get fixed before the software deploys.
A better approach is for each change to the software to create a new version. The new version flows through the deployment pipeline independently, making it possible to fix issues for a single change when detected.
Painful operations
Operations tasks tend to become painful over time. Configuring infrastructure might be easy initially, but keeping the configuration in sync across environments and services becomes more challenging as things scale. The application architecture may become more complex as the organization grows, making it difficult to understand the impact of infrastructure changes.
You can detect operations pain by looking for signs like:
- Manual changes to infrastructure either by accessing machines directly or through web portals (often called ClickOps)
- Problems managing configuration and configuration drift
- Bugs caused by subtle configuration differences between environments or instances
- Infrastructure changes take a long time, as you need to repeat them many times
- No way to roll back to a previous infrastructure configuration
- Emergency changes to resolve a live issue, followed by wondering which of many speculative changes fixed the fault
A better approach is to version control infrastructure and configuration the same way you control software versions. That way you can quickly review changes and automatically deploy specific versions.
Painful process
Often caused by other pains, things can go terribly wrong in software delivery. A common reaction to past hurt is to introduce bureaucratic stages to prevent the problems happening again. Change freezes, sign-offs, and advance deployment scheduling are all signs someone tried to reduce other sources of pain.
The problem is these interventions bloat processes without improving software delivery performance. Any stage that delays software releases tends to increase the batch size of the deployment, making it more likely things will go wrong.
Benefits of Continuous Delivery
Continuous Delivery solves these common software delivery pains. By building a deployment pipeline with an appropriate set of tools and automation, you can create a release process that’s repeatable, reliable, and predictable.
You can make work easier and more fulfilling across all roles involved in software delivery.
Alongside the reduction of pain, there are also several benefits.
Human benefits
There’s far less stress once a solid deployment pipeline and related practices are in place. Deployments no longer create widespread anxiety, and the organization has confidence the team can deliver software safely and reliably.
Frequent high-quality releases are the best way to increase trust between development, operations, and the rest of the business.
When deployments are no big deal, everyone can relax and focus on doing their best work.
Software delivery benefits
In terms of software delivery, the lead time for changes will be shorter. You can deliver features and bug fixes sooner. You have fewer merge conflicts, and small batch sizes will stop changes cyclically blocking each other.
Automation reduces configuration and deployment errors. Your deployment automation ensures the correct code version deploys using the proper process. You miss no steps and those you perform have no errors, and your infrastructure will be in the right state.
You can handle issues by creating an environment with the suspect software version to recreate the problem quickly.
Learn more in our detailed guide to Continuous Delivery tools.
Business benefits
Continuous Delivery provides tangible business benefits, with organizations using the tools and practices:
- 2x more likely to meet or exceed commercial goals
- 2x more likely to meet or exceed non-commercial goals
- 2.2x more likely to be recommended as a good place to work
- Growing their market cap 50% higher
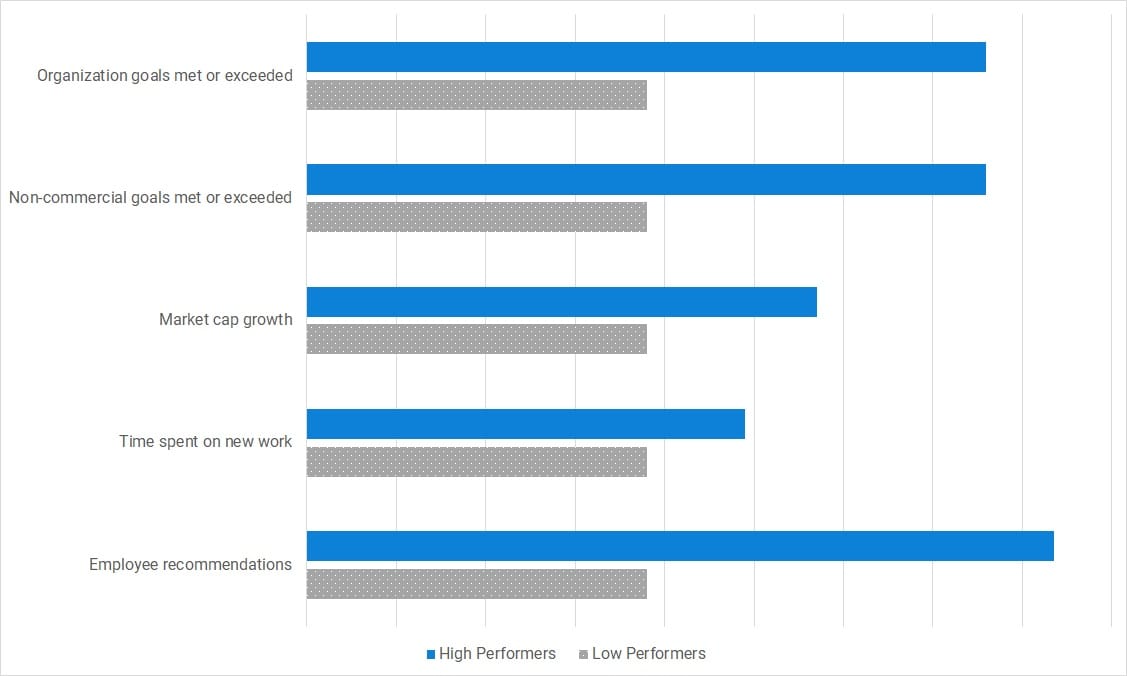
Teams using Continuous Delivery spend more time on features and less time on bug fixes. They deploy more often, and their software is more reliable.
Not sure where to begin? Read getting started with Continuous Delivery
Challenges of adopting Continuous Delivery
Adopting Continuous Delivery provides both technical and cultural challenges. Both are equally important. You may also want to form a strategy for how you invest in the work needed to build the deployment pipeline.
Technical challenges
Although you will likely already some necessary tools, you need to identify gaps. Get the missing tools and related skills to create a reliable and automated deployment pipeline.
Most teams have version control and a build server, but you may need to use the more advanced features of these tools to test and package the software. You need to look at artifact repositories, deployment automation, infrastructure automation, and monitoring and alerting.
As well as tools, the technical practices of Continuous Integration, test automation, architecture, security, and observability may represent areas you need to strengthen.
Cultural challenges
You may need to make cultural challenges. If your operations team is at arm’s length from your development team, you need to resolve some classic development and operations conflicts so the teams can work together on Continuous Delivery. Culture is one of the critical capabilities of DevOps, and there’s plenty of evidence that links positive culture to actual business outcomes.
For example, if your ops team won’t allow automated deployments to the production infrastructure, you’re unlikely to get the full benefit of Continuous Delivery. You still get some benefits, like automated on-demand deployments to other environments, but you find the live deployments remain difficult and infrequent.
You could avoid this challenge by proving the benefits to stakeholders in pre-live environments, but the operations team will likely see this as a move to undermine them. Instead, collaborate with the operations team and take the time to build trust.
It’s best to tackle cultural issues head-on as early as possible.
An investment strategy
The main challenge is investing the time into building your deployment pipeline. You will gain this time back quickly as you reduce the manual effort involved in deployments. We recommend a reinvestment model to resolve this challenge.
Invest a fixed amount of time in automating one part of your deployment pipeline. Use the time saved by this automation to create a weekly budget for further automation.
Each time you automate another part of your Continuous Delivery pipeline, you create more time in your automation budget. This limits the spending to whatever fixed period you originally invested.

Tony Kelly is a DevOps marketing leader who drives innovation and awareness of the latest trends in Continuous Delivery.
Cost-benefit analysis of Continuous Delivery
Google Cloud, along with DevOps Research and Assessment (DORA), created a model for investment in DevOps transformation. By accounting for several factors across business sizes, their model demonstrated that it’s possible to pay back investment within a month of completing the transformation. The total return can be ten times the original investment.
With this in mind, you may want to accelerate your investment in building your deployment pipeline and adopting Continuous Delivery practices. These are key DevOps capabilities.
Learn more in our detailed guide to the benefits of Continuous Delivery.
Summary
Continuous Delivery removes a great deal of pain from your software delivery process. Along with other DevOps practices, it can bring high-impact benefits, not just for your software but for your whole organization.
Further reading
These resources will help you find out more about Continuous Delivery:
- Continuous Delivery by Jez Humble and Dave Farley (2011)
- Continuous Delivery Pipelines by Dave Farley (2021)
- An overview of Continuous Delivery
- Continuous Delivery principles
- Getting started with Continuous Delivery
- Our white paper on the importance of Continuous Delivery
- Continuous Delivery vs Continuous Deployment
Help us continuously improve
Please let us know if you have any feedback about this page.