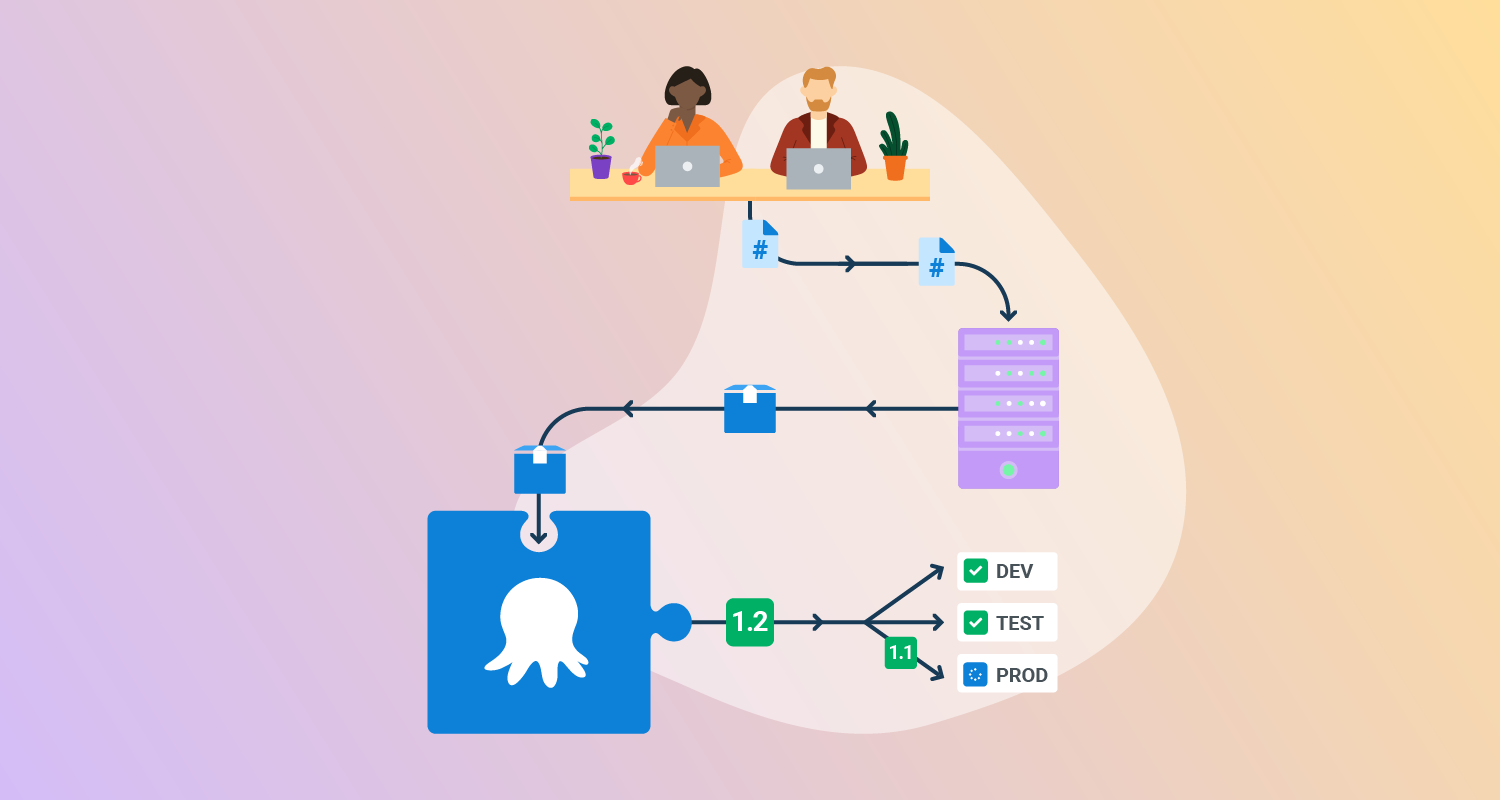
What is Continuous Integration?
Continuous Integration is the practice of merging your code into the main branch in version control frequently. Kent Beck described this process in Extreme Programming Explained, but it’s still a core practice of Continuous Delivery and DevOps.
The process works like this. After a few hours of work, you commit your changes to the main branch, resolving any conflicts you have with changes other people have made.
Continuous Integration works even better when other practices like test-driven development, pair programming, and regular refactoring are also used. When you merge into main, you want to know as early as possible if there’s a problem with the changes. A good Continuous Integration process will have automation that runs a build and tests so you know within 5 minutes if your new software version is bad.
You can think of Continuous Integration as a human process, assisted by computers.
This is part of a series of articles about Continuous Delivery.
What are Continuous Deployment and Continuous Delivery?
Continuous Delivery is far broader than Continuous Integration. In fact, Continuous Integration is just one of the practices that form the definition of Continuous Delivery in the book by Jez Humble and Dave Farley. The practices can be grouped into three areas:
- Practices a developer applies when writing and changing code.
- Continuous Integration, where the developer merges their changes into the main branch.
- The deployment pipeline, where automation assists with everything that happens after the merge to get the new software version into production.
When you merge your changes into the main branch, your CI tools will compile the code and create an artifact for each successful build. This artifact is passed into your deployment pipeline, which defines all the steps needed to accept the new software version and make it available to users. You should automate as much of your deployment pipeline as possible.
To satisfy the definition of Continuous Delivery, every merge should leave you with a deployable software version. To keep your software deployable at all times, you need to work in small batches and make sure that each commit is atomic enough that it can be deployed to production. You can’t make batches small by committing half-finished changes, as this would mean the software can’t be deployed.
As you work towards Continuous Delivery, you’ll automate most, if not all, of the steps required to test and accept the new software, and to deploy it to your test and production environments.
If you manage to automate the entire process, you may decide you no longer need manual intervention in the deployment pipeline. In this case, you can use Continuous Deployment, which results in every code change being deployed to production if the automated tests pass.
The only difference between Continuous Delivery and Continuous Deployment is whether human approval is required as part of the deployment pipeline.
There are many valid reasons to want human approval, such as:
- You want to choose when a new version is deployed.
- You require a sign-off from a product owner, database administrator, or other specialist.
- You want to run new versions through a usability or user experience lab.
- It’s easier to satisfy regulatory and compliance requirements.
- You don’t yet have confidence in the automation.
Though Continuous Integration is a human process, assisted by automation Continuous Delivery and Continuous Deployment are automated processes, assisted by humans.
Continuous Delivery versus Continuous Integration: Key differences
1. Scope
Continuous Integration (CI) focuses on integrating code changes from multiple developers into a shared repository several times a day. It reduces integration issues and merge conflicts and validates each version is in a deployable state. If there’s a problem with a software version, this is resolved before further feature work is done.
Continuous Delivery (CD) encompasses the entire software release process. It extends beyond the build and test stages handled by CI to include deployment to staging and production environments. CD aims to make the release process as automated as possible while allowing for manual intervention at predefined checkpoints.
2. Process
The CI process automatically builds and tests code whenever changes are committed to the repository. This includes compiling the code, running unit tests, and generating build artifacts. The goal is to catch issues early and provide rapid feedback to developers.
The CD process includes the CI steps and adds stages for deploying the build artifacts to production or staging environments. This often involves integration testing, user acceptance testing, and performance testing. CD processes may include manual approval steps where stakeholders can review and approve releases before they go live.
3. Environment
CI environments are equipped with all the necessary tools and dependencies to compile and test the code effectively. The focus is on quick feedback cycles, so these environments are optimized for speed and reliability.
CD environments need to be more realistic. They must be representative of the production environment to ensure that the software behaves as expected when deployed to users. CD environments often include additional monitoring and rollback mechanisms to handle deployment failures gracefully.
4. Metrics and KPIs
CI metrics focus on the efficiency and reliability of the integration process. Key performance indicators (KPIs) include build frequency, build duration, test pass rates, and the number of issues detected. These metrics help teams identify bottlenecks in the development process and improve code quality.
CD metrics focus on the throughput and stability of the deployment pipeline. KPIs include deployment frequency, lead time for changes, time to recover, and change failure rate. These metrics provide insights into how quickly and reliably new features and fixes can be delivered to users.
5. Team Involvement
CI processes primarily involve developers and DevOps engineers, who are responsible for writing and integrating code. These teams focus on maintaining code quality and ensuring that the codebase remains deployable.
CD processes involve a broader range of stakeholders, including developers, testers, product owners, and release managers. While much of the deployment process can be automated, decisions about when and what to release often involve input from various team members. This ensures that the software meets business requirements and is ready for production use.

Tony Kelly is a DevOps marketing leader who drives innovation and awareness of the latest trends in Continuous Delivery.
Why use separate tools for Continuous Integration and Continuous Delivery?
With all-in-one tools for CI/CD, the process is typically mapped as an end-to-end flow including the build, tests, and deployments. The same pipeline tools for builds are often extended to manage deployments, which means writing your own scripts that are run within the all-in-one tool.
A dedicated CD tool will make good deployment practices easier to apply and will support roles beyond developers with an intuitive user interface and dashboards.
Learn more in our detailed guide to Continuous Delivery tools.
CD tools handle manual intervention and approvals
You often need human assistance either to approve a step in the deployment pipeline or to handle something unexpected. While a Continuous Integration build should fail when there’s a problem, it’s often not desirable to fail a deployment in the same way, as it can leave your production environment in an unknown state. For example, if a database has been upgraded and an application installation fails, you need someone to decide how to proceed, and you’ll often want to re-try a step rather than roll back changes.
CD tools have features to reduce complexity
A dedicated Continuous Delivery tool will have features that assist you with variable substitution. This ensures the correct values are applied to different environments, machines, or tags, or let you apply client or location-specific values through tenanted deployments. This prevents configuration-based errors, which are a common cause of deployment failures, and reduces the duplication of the deployment process across many workflows.
Dedicated CD tools will also manage environments, ensure a software version progresses through the appropriate phases, and handle scheduling and deployment freezes.
CD tools extend beyond development teams
Having a dedicated CD tool lets you increase the collaboration beyond developers, as they provide a user interface that can be used by stakeholders to see the current state of deployment, or by product owners to approve a deployment. Being able to provide push-button actions to non-technical users means you can create a platform that reduces toil for technical team members. For example, you can give testers access to a push-button operation to clear caches on the staging environment, so they don’t need to raise a ticket.
Making the move from Continuous Integration to Continuous Delivery
Transitioning from Continuous Integration (CI), or a monolithic all-in-one tool CI/CD process, to full Continuous Delivery (CD) involves several key steps and considerations to ensure a seamless, automated deployment process. Here’s a step-by-step guide to help your team move towards Continuous Delivery:
- Enhance test coverage and quality: Ensure that your test suite is comprehensive and reliable. This includes unit tests, integration tests, end-to-end tests, and performance tests. High test coverage helps catch issues early and provides confidence in the code’s stability.
- Automate deployment pipelines: Build deployment pipelines that automatically promote builds through different stages (e.g., development, staging, production). In complex environments, use dedicated deployment automation tools. Each pipeline stage should include appropriate tests and checks to validate the software.
- Implement robust monitoring and alerting: Set up monitoring and alerting systems to track application performance and errors in real time. Tools like Prometheus, Grafana, and ELK stack (Elasticsearch, Logstash, Kibana) are commonly used for this purpose.
- Feature flags and canary releases: Use feature flags to turn new features on or off without deploying new code. This allows you to release features to a subset of users and gradually roll them out. Canary deployments involve deploying the new version to a small group of users first, monitoring its performance, and then rolling it out to all users.
- Adopt Infrastructure as Code (IaC): Manage your infrastructure using code with tools like Terraform, Ansible, or AWS CloudFormation. IaC ensures that your environments are consistent and can be recreated or modified through version-controlled scripts, reducing the risk of configuration drift and human error.
- Establish a rollback plan: Define a clear rollback strategy for when deployments fail. This commonly involves using blue/green deployments, where two identical environments (blue and green) are maintained. Traffic is switched to the new version (green), and in case of issues, switched back to the old one (blue).
- Encourage a DevOps culture: Foster a culture of collaboration between development and operations teams. Encourage shared responsibility for deployment processes and system reliability. Regularly review and refine your CI/CD practices based on team feedback and changing product requirements.
- Continuous feedback and improvement: Continuously gather feedback from all stakeholders, including developers, testers, and end-users. Use this feedback to improve your CI/CD pipelines, test coverage, monitoring systems, and deployment strategies. Regularly review and update your processes to adapt to new challenges and technologies.
By following these steps, your team can achieve a fully automated Continuous Delivery process, enabling faster and more reliable software releases.
Building a world-class Continuous Delivery pipeline with Octopus
For complex deployments, the specific features of CD tools are needed to reduce process duplication and manage the intricacies of the deployment process. You may be aiming to deploy more often, increase deployment reliability, or handle more complex deployment needs. While this may be possible with a CI tool, it’s likely to be far from ideal. It often means writing your own scripts to handle the details that all-in-one tools can’t assist with.
Combining a best-in-class Continuous Delivery tool with your CI tools will remove the need for DIY shadow CD, which involves large volumes of custom scripts, stored in YAML files, and executed by your CI tool.
You can give it a try by building with GitHub and deploying with Octopus.
Get started with Octopus
Make complex deployments simple
Get insights into the culture and methods of modern software delivery
Sign up for our fortnightly Continuously Delivered email series to learn from our experiences with Continuous Delivery, Agile, Lean, DevOps, and more.
Sign upHelp us continuously improve
Please let us know if you have any feedback about this page.