What are rolling deployments?
Rolling deployments are a software release strategy where new versions of an application are incrementally deployed to a subset of servers or instances. This process allows for a gradual rollout, reducing the risk of widespread issues caused by new releases. Instead of updating all instances at once, a rolling deployment updates a few at a time. This ensures that some instances continue running the old version while the new version is being deployed.
This is part of a series of articles about software deployment.
How a rolling deployment works
Rolling deployments typically follow these steps:
- Preparation: The new version of the application gets prepared and validated in a staging environment to ensure it is ready for production.
- Incremental update: The deployment starts by updating a small subset of instances, usually one or a few at a time. These instances get taken out of the load balancer pool to avoid serving traffic during the update.
- Health checks: After updating the subset, health checks run to ensure the instances are functioning correctly. This may involve monitoring specific metrics or running automated tests.
- Update load balancer: After the updated instances pass health checks, they’re added back to the load balancer pool.
- Repeat: The process repeats for the next subset of instances until the new version is running on all instances.
During each step, careful monitoring is essential to detect any issues early. If you find a problem, you can pause the deployment, and roll back the problematic instances to the previous version.
Rolling deployments versus blue/green deployments
In a blue/green deployment, you maintain 2 identical production environments:
- One active (blue)
- One idle (green)
The new version gets deployed to the green environment while the blue environment continues to serve live traffic. After the deployment is complete and verified, traffic switches to the green environment, making it the new active environment. This strategy minimizes downtime and lets you quickly roll back by switching traffic to the blue environment if there are any issues.
Learn more in our detailed guide to blue/green deployments.
Rolling deployments update instances gradually in the same environment. This ensures continuous availability of the application. However, rollbacks can be more complex as you have to revert changes on individual instances rather than switching environments.
What are rolling deployments in Kubernetes?
In Kubernetes, a rolling deployment is a built-in deployment strategy, facilitated by the Kubernetes deployment controllers. These controllers manage the process of gradually updating the instances of an application. Kubernetes automates many of the manual steps in rolling deployments, making the process more efficient and reliable.
When you deploy a new version of a containerized application, Kubernetes updates a few pods at a time while ensuring that the rest of the application is available to handle traffic. The deployment controller continuously monitors the status of each pod and only updates the next batch if the previous ones pass health checks.
A key feature of Kubernetes rolling deployments is the seamless integration with the cluster’s scaling and self-healing capabilities. Kubernetes can automatically scale the number of pods up or down based on resource use and predefined policies. If any pod fails during the update, Kubernetes can roll back the changes or replace the failed pod, maintaining the application’s desired state.
Pros and cons of rolling deployments
Here are some of the main advantages of rolling deployments:
- Reduced downtime: Rolling deployments ensure that at least some instances of the application are always running. This minimizes downtime and maintains availability for users.
- Incremental rollout: By updating a few instances at a time, rolling deployments allow for a gradual introduction of the new version. This makes it easier to identify and resolve issues without affecting the entire user base.
- Easy monitoring: The incremental nature of rolling deployments simplifies monitoring and troubleshooting. You can detect problems early, and take corrective measures before they impact more instances.
- Continuous deployment: This method supports Continuous Deployment practices, as it allows for frequent and smaller updates. This aligns with agile methodologies and DevOps principles.
- Resource optimization: Rolling deployments make efficient use of existing infrastructure, as there is no need to double the environment like in blue/green deployments.
You should also be aware of some important limitations of rolling deployments:
- Complex rollback: Rolling back changes in a rolling deployment can be complex. You need to revert updates on individual instances rather than simply switching environments. This can lead to inconsistencies if not managed carefully.
- Longer deployment time: Since updates happen incrementally, the overall deployment process can take longer compared to strategies like blue/green deployments where the switch is more instantaneous.
- Potential for inconsistent states: During the deployment, different instances may run different versions of the application. This can lead to inconsistent behavior, especially if there are significant changes between versions.
- Load balancer configuration: Continuous updating of load balancer configurations to add or remove instances can introduce complexity and potential points of failure, particularly in large-scale environments.
- Higher operational overhead: The need for constant monitoring, health checks, and incremental updates increases the operational burden on the deployment team. You need robust automation and orchestration tools to manage this effectively.
Best practices for implementing rolling deployments
1. Define success criteria
Before initiating a rolling deployment, it’s crucial to define clear and measurable success criteria. You should include specific metrics like response time, error rates, resource use, and user experience benchmarks.
You should also set thresholds for acceptable performance levels and outline what a successful deployment looks like. For example, you might decide that error rates must remain below a certain percentage, or response times shouldn’t exceed a defined limit. These benchmarks let you evaluate the deployment process objectively. They also ensure you can quickly identify and address any deviations from expected performance.
2. Use a staging environment
Using a staging environment that closely mirrors the production environment is essential for mitigating risks associated with new deployments. This step involves deploying the new version to the staging environment first. Here it undergoes rigorous testing. The staging environment should replicate production conditions as closely as possible. This includes the same configurations, data sets, and traffic patterns.
Comprehensive testing in staging helps you find functionality, performance, and compatibility issues. By resolving these issues before the actual deployment, you can significantly reduce the risk of disruptions during the rollout. Additionally, the staging environment provides a safe space to experiment with deployment strategies, automation scripts, and rollback procedures.
3. Incremental rollout
To implement an incremental rollout strategy, you update a small subset of instances at a time, rather than all at once. You start with one or two instances, to limit the impact of potential issues. Gradually, you increase the number of instances receiving the update, continuously monitoring health and performance, to isolate and address problems before they affect the entire user base.
During each phase of the rollout, perform comprehensive health checks, including automated tests and monitoring of key metrics. This meticulous, step-by-step process ensures a controlled, stable rollout. This minimizes the risk of widespread disruptions and keeps services available throughout the deployment.
4. Implement automated rollback procedures
Automated rollback procedures are essential for swiftly reverting to the previous version if issues arise during a deployment. This involves pre-configuring rollback scripts and automating the process so it’s quick and consistent. In practice, this means setting up scripts that get triggered automatically or with minimal manual intervention to revert updated instances to the last known good state.
You should thoroughly test automated rollback procedures in the staging environment to ensure they work as expected. This automation minimizes downtime and the likelihood of human error, making the deployment more reliable.
Related content: Read our guide to software deployment pipelines.
Rolling deployments with Octopus
Octopus Deploy facilitates rolling deployments by allowing the application to be incrementally updated across multiple servers. Instead of updating all servers at once, the update gets rolled out gradually, reducing downtime and mitigating risks.
In a typical rolling deployment, Octopus runs deployment steps sequentially. Each step targets multiple machines, performing actions in parallel. This approach is helpful for large-scale environments where you need to control and monitor updates closely.
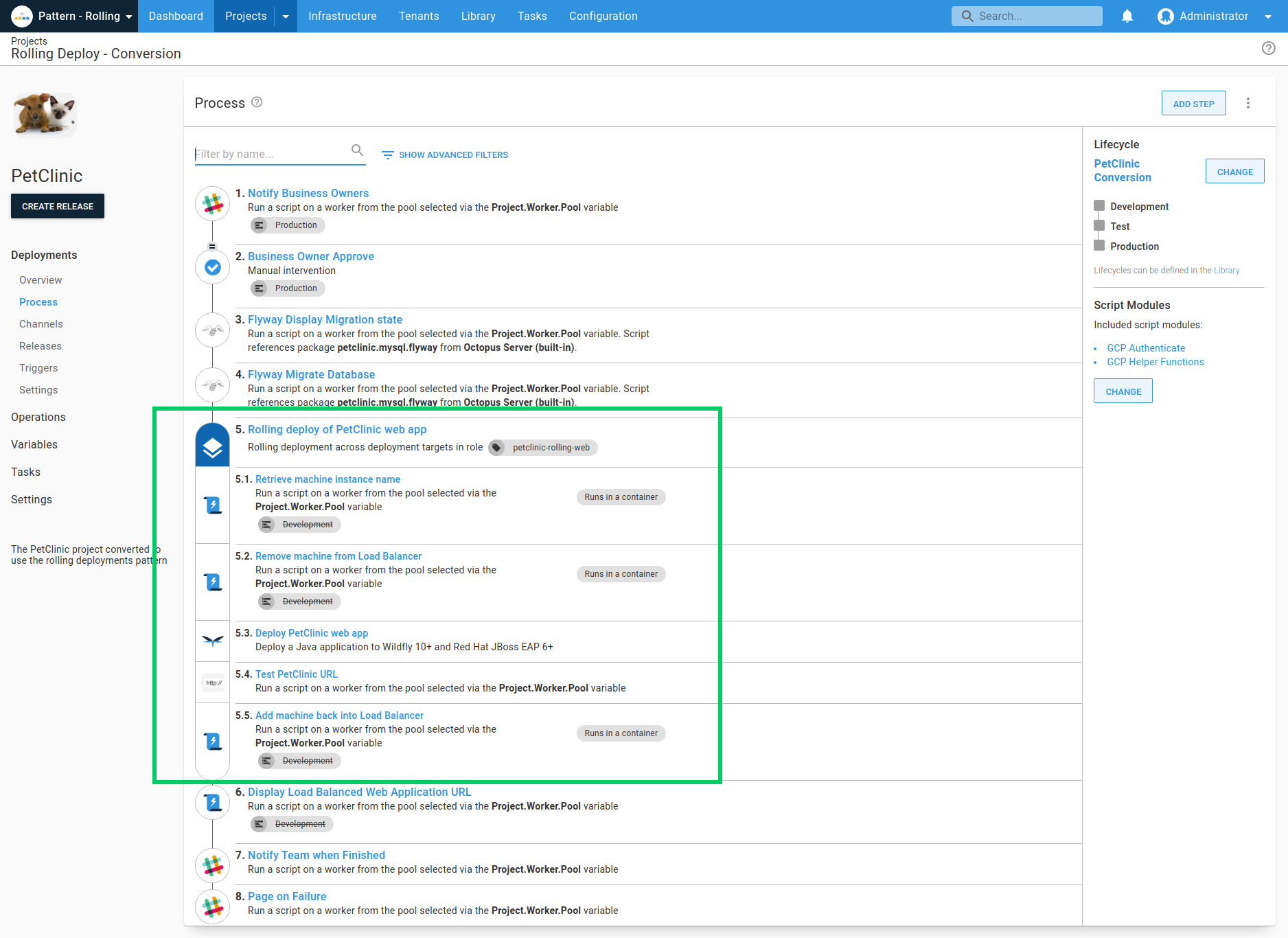
Here are a few important aspects of rolling deployments in Octopus:
- Setup and configuration: You can configure rolling deployments by selecting a PowerShell or NuGet package step and enabling the rolling deployment option. During configuration, you specify a window size that determines how many deployment targets can be updated at once. For example, a window size of 1 updates one server at a time, while a larger window size updates multiple servers at once.
- Window size: The window size is critical for controlling the deployment pace. A smaller window size ensures minimal impact if an issue arises but may extend the overall deployment time. A larger window size accelerates the deployment but increases the risk if problems occur.
- Child steps: Octopus supports child steps, letting you run multiple actions on one deployment target before moving to the next. This is useful for complex deployments requiring several tasks on each server. For example, taking a server out of the load balancer, deploying updates, and then reintegrating it into the load balancer.
- Variable run conditions: Child steps can have variable run conditions, letting you customize the deployment process based on specific criteria. For example, after updating a web service, a test step can set a variable indicating whether the service should get added back to the web farm.
- Guided failures: Octopus’s guided failure feature is particularly useful for rolling deployments. If an update fails on a server, you can retry, ignore, or exclude the server from further updates. This gives your flexible error handling without halting the entire deployment.
With these features, Octopus ensures that rolling deployments are efficient, controlled, and adaptable, making it a robust solution for managing software updates across multiple servers.
Get started with Octopus
Make complex deployments simple
Help us continuously improve
Please let us know if you have any feedback about this page.